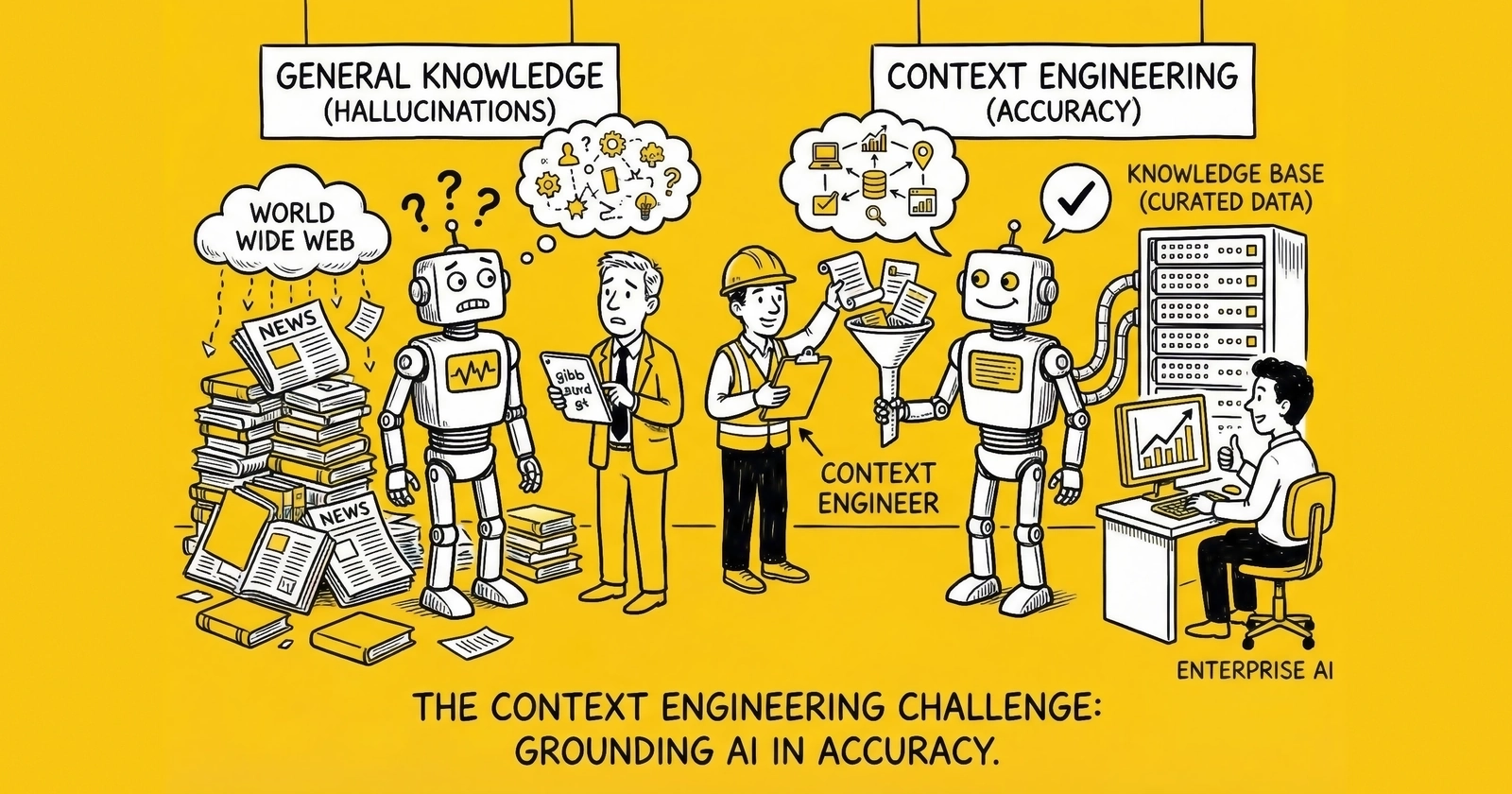
Why prompt engineering is only 5% of the equation – and how the five-level context architecture determines whether enterprise AI succeeds
The uncomfortable truth about enterprise AI
The statistics are damning. MIT research reveals that 95% of enterprise AI pilots fail to deliver measurable business impact. Not 50%. Not even 80%. Ninety-five percent. Our analysis of enterprise AI failures identifies the root causes – and context gaps top the list.
These aren’t amateur efforts. They’re well-funded initiatives at sophisticated organizations, staffed by talented teams, using state-of-the-art models from the best AI providers. Yet the vast majority produce nothing beyond impressive demos.
What separates the 5% that succeed from the 95% that don’t?
The conventional wisdom focuses on prompts. Craft the perfect instruction, the thinking goes, and the AI will perform. This belief spawned an entire discipline – prompt engineering – complete with courses, certifications, and specialized job titles.
But prompt engineering is a misdirection. It addresses perhaps 5% of what makes enterprise AI successful. The remaining 95% depends on something less glamorous but far more consequential: the information environment surrounding those prompts.
In June 2025, Andrej Karpathy – former Director of AI at Tesla, former founding member of OpenAI – crystallized this reality:
“People associate prompts with short task descriptions you’d give an LLM in your day-to-day use. When in every industrial-strength LLM app, context engineering is the delicate art and science of filling the context window with just the right information for the next step.”
Gartner formalized the shift in October 2025 with explicit guidance: “Context engineering is in, and prompt engineering is out. AI leaders must prioritize context over prompts.”
This isn’t semantic quibbling. It’s a fundamental reframing of what makes AI work in enterprise settings – and why most organizations are investing in the wrong things.
What context engineering actually is
Beyond the prompt
A prompt is what you say to an AI. Context is everything else the model sees.
Think of an LLM as a processor and its context window – the text input it processes at once – as working memory. As Karpathy explains, your job is akin to an operating system: load that working memory with just the right information for the task at hand.
This context can come from many sources: the user’s immediate query, system instructions defining behavior, retrieved knowledge from databases and documentation, outputs from tools and APIs, summaries of prior interactions, examples demonstrating expected behavior, business rules and calculation logic, relationship information connecting entities, and historical patterns and user preferences.
Context engineering is the practice of orchestrating all these pieces into the information state that the model ultimately processes. It’s not a static prompt but a dynamic assembly of information at runtime – carefully curated, formatted, and prioritized based on the specific task.
Tobi Lütke, CEO of Shopify, captured the essence: “Context engineering describes the core skill better: the art of providing all the context for the task to be plausibly solvable by the LLM.”
The CPU/RAM mental model
Karpathy’s analogy provides a useful mental model:
| Computer | LLM System |
|---|---|
| CPU | The language model itself |
| RAM | Context window (128K-1M+ tokens) |
| Operating System | Your context engineering layer |
| Application | The specific task being performed |
Just as an operating system manages what gets loaded into RAM for a running application, context engineering manages what information gets assembled into the context window for each AI interaction.
The implications are profound. No matter how powerful the CPU, if the wrong data is loaded into RAM, the application fails. Similarly, no matter how capable the model, if the wrong context is provided, the AI produces garbage – or worse, confident-sounding garbage that misleads decision-makers.
Science and art
Context engineering is, as Karpathy puts it, “both a science and an art.”
The science involves established methods that reliably improve performance: few-shot prompting that provides examples of expected behavior, retrieval-augmented generation that fetches relevant documents, chain-of-thought prompting that encourages step-by-step reasoning, structured outputs that specify response formats, and tool use that gives models access to calculators, APIs, and databases. These techniques have empirical support. We know from research and practice that they improve results in predictable ways.
But applying these techniques effectively requires judgment – the art. Which retrieved documents are actually relevant? How many examples are enough without overwhelming the window? What information is essential versus nice-to-have? How should conflicting sources be prioritized? When does more context actually degrade performance?
Every model has a context length limit. Overstuffing that window doesn’t just increase latency and cost – it can actively degrade quality if important information gets lost in noise. Finding the sweet spot is non-trivial.
The five-level context architecture
Why context fragmentation breaks AI
Over the past decade, enterprises mastered data integration. Modern data stacks aggregate information from hundreds of sources into centralized platforms. ETL pipelines run continuously. Data lakes hold petabytes.
But context didn’t follow.
Context remains distributed across systems that don’t communicate: database schemas contain technical metadata, data models describe relationships, data catalogs hold business definitions, BI tools encode calculation logic, and analyst minds hold tribal knowledge. Each system maintains partial context. None talk to each other systematically. When AI tries to answer a business question, it’s working with fragments – like trying to solve a puzzle with most pieces missing.
This is why the same organizations that successfully integrated their data are failing at AI. Data integration isn’t context integration.
The five levels
Promethium.ai has defined a five-level context architecture that determines AI accuracy:
Level 1: Physical Schema (Technical Metadata)
The foundation: column names, data types, table structures. This is what the database knows about itself.
Without Level 1: AI has no idea what data exists or how it’s structured. With Level 1: AI can identify relevant tables and columns, but doesn’t understand what they mean.
Level 2: Relationships
How entities connect: join paths, foreign keys, cardinality rules. This is what data models capture.
Without Level 2: AI can query individual tables but can’t combine information across sources. With Level 2: AI can traverse connections – linking customers to orders to products – but doesn’t understand business meaning.
Level 3: Data Catalog (Business Definitions)
What things mean: descriptions, owners, lineage. This is what data catalogs provide.
Without Level 3: AI might find the right tables but misinterpret what columns represent. With Level 3: AI understands that “CUST_LTV” means “Customer Lifetime Value” and who owns that definition.
Level 4: Semantic Layer
How to calculate: metric definitions, business rules, fiscal calendars. This is what BI tools encode.
Without Level 4: AI makes up its own calculation logic, producing answers that don’t match organizational understanding. With Level 4: AI applies the same formulas that finance uses, producing consistent, trusted results.
Level 5: Memory and Learning
What worked before: query patterns, user preferences, historical corrections. This is tribal knowledge made systematic.
Without Level 5: Every interaction starts from scratch; the system never learns. With Level 5: AI improves continuously, incorporating feedback and adapting to organizational patterns.
The accuracy gap
The research is stark. According to Promethium’s analysis:
| Context Levels | Typical AI Accuracy |
|---|---|
| Level 1 only | 10-20% |
| Levels 1-2 | 25-40% |
| Levels 1-3 | 50-65% |
| Levels 1-4 | 75-85% |
| All 5 levels | 94-99% |
Organizations with fragmented context struggle at 10-20% accuracy. Those systematically capturing all five levels achieve 94-99% accuracy. This isn’t a marginal improvement – it’s the difference between AI that’s useless and AI that’s transformative.
The implications for enterprise AI strategy are immediate: investing in models while neglecting context is like buying a sports car and filling it with contaminated fuel.
Why each level matters: a practical example
Consider the query: “Show me Q4 revenue by product category for the Western region.”
Level 1 (Schema) gets you: Tables containing revenue, product, and region data exist. The AI knows where to look.
Level 2 (Relationships) adds: Revenue connects to products via order_line_items. Products connect to categories. Orders connect to regions via shipping address. The AI knows how to join the data.
Level 3 (Catalog) adds: “Revenue” in this context means the transactions table, not the forecasts table. “Western region” includes California, Oregon, Washington, Nevada, and Arizona. The AI avoids ambiguity.
Level 4 (Semantic) adds: Revenue should exclude returns and chargebacks. Q4 follows the fiscal calendar (October-December, not October-September). Categories use the 2024 taxonomy, not the deprecated 2022 version. The AI applies organizational business logic.
Level 5 (Memory) adds: This user typically wants revenue net of discounts. Similar queries from this department usually exclude test accounts. Last time this question was asked, the user wanted comparison to Q3. The AI anticipates needs and avoids past mistakes.
Without all five levels, the AI might produce a number. But it probably won’t be the right number – and worse, there’s no way to know.
Knowledge graphs as context foundation
Why graphs beat tables for AI
Knowledge graphs have emerged as the structural foundation for enterprise context engineering. Unlike traditional databases that organize information in rigid tables, knowledge graphs represent data as networks of interconnected entities and relationships.
This architectural alignment creates natural synergies with how LLMs work. Language models are themselves massive networks of statistical correlations. Research shows that simply expressing metadata semantically – using knowledge graph structures instead of traditional schemas – can triple zero-shot accuracy without any model training.
The benefits extend beyond structural compatibility. Knowledge graphs enable multi-hop reasoning – questions that span multiple connections. “Show incidents tied to components introduced after the Q3 release” requires traversing several relationships from incidents to components to releases to dates; graphs make this traversal explicit and reliable. They also resolve ambiguity by attaching canonical identifiers to entities. “Apple” in a query could mean the company, the fruit, or a project code, but a knowledge graph that models your organization’s entities knows which one the user means based on context.
Governance benefits follow naturally. Permission controls can be embedded at the entity level, with the graph understanding that certain relationships are visible only to specific roles and enforcing access policy during retrieval rather than after. And because graphs make relationships explicit, AI systems can explain their reasoning – “I found this answer by connecting Customer X to their Orders, then to the Products purchased, then to the Category those products belong to.” This audit trail builds trust.
LinkedIn’s 78% accuracy improvement
The business case for knowledge graphs has production evidence. In a paper published in April 2025, LinkedIn reported that combining RAG with a knowledge graph improved the accuracy of their customer service AI by 78%.
Over six months of deployment, the system reduced median per-issue resolution time from 40 hours to 15 hours – a 63% improvement in operational efficiency.
The key wasn’t the graph alone but the combination. Traditional RAG retrieves documents based on semantic similarity – “find content that seems related to this query.” Graph-enhanced RAG adds structural understanding – “find content about entities that are actually connected to what the user is asking about.”
For complex queries requiring understanding across multiple sources and relationship types, this combination dramatically outperforms either approach alone.
Building the enterprise knowledge graph
Creating an effective knowledge graph for context engineering requires systematic effort across four dimensions. First, entity extraction: identify the key entities in your domain – customers, products, employees, projects, systems, documents – which become the nodes in your graph. Second, relationship modeling: define how entities connect (customers purchase products, employees work on projects, projects use systems, systems process documents), with these relationships becoming edges. Third, property capture: attach relevant attributes to entities like customer segments, product categories, and employee departments, enabling filtering and aggregation. Fourth, continuous refresh: because enterprise knowledge changes constantly as new employees join, products launch, and projects complete, the graph must update in real-time or near-real-time to remain useful.
Glean, a leading enterprise AI platform, describes their approach: “We’ve built a real-time crawler architecture that powers both semantic and lexical search, continuously ingesting enterprise content and metadata. This same infrastructure feeds our knowledge graph.”
The investment is significant but the payoff is substantial. Organizations that build comprehensive knowledge graphs create durable infrastructure that improves AI accuracy across every use case – not just one application at a time.
From prompts to pipelines
The context engineering stack
Production AI systems don’t rely on clever prompts. They build context pipelines – systematic processes for assembling the right information at runtime.
A typical context engineering stack includes five integrated layers. The query understanding layer comes first: before retrieving anything, understand what the user actually needs through intent classification, entity extraction, query expansion, and disambiguation. The retrieval orchestration layer follows: once intent is understood, gather relevant context from multiple sources including vector search against document embeddings, graph traversal across the knowledge base, structured queries against databases, API calls to external systems, and memory retrieval from conversation history.
Raw retrieved content then flows to the context assembly layer, where it must be formatted and prioritized through relevance ranking, deduplication, summarization, formatting for optimal model consumption, and token budgeting to fit within window limits. The generation layer receives the assembled context: system prompts define behavior, retrieved context provides facts, the user query specifies the task, and output constraints guide format. Finally, the feedback loop captures signals for improvement – user acceptance or rejection, explicit corrections, usage patterns, and error analysis.
This is context engineering in practice – not a single prompt but an integrated system for assembling information dynamically.
The role of MCP
Model Context Protocol (MCP) has emerged as the standard for connecting AI systems to context sources. Introduced by Anthropic in November 2024 and subsequently adopted by OpenAI, Google, and Microsoft, MCP provides a universal interface for accessing resources like documents, database records, and files; executing tools with side effects; and reusing prompt templates and patterns.
For context engineering, MCP solves the integration problem. Rather than building custom connections to each data source, organizations implement MCP servers that expose standardized interfaces. Any MCP-compatible AI client can then access those sources through the protocol.
Ardoq, an enterprise architecture vendor, describes the impact: “MCP, an open standard, standardizes how AI assistants access external data sources. Users work where they already are – ChatGPT, Copilot, Claude, Gemini – rather than switching to dedicated tools. An architect can ask an AI assistant to ‘Generate a summary of our application portfolio costs by business capability’ and receive synthesized insights combining data from multiple reports.”
The organizational implication: enterprise architects, data engineers, and knowledge managers are becoming context engineers – curating and exposing information so AI systems can consume it effectively.
Agentic context engineering
As AI moves from assistants to agents – systems that take autonomous action rather than just answering questions – context engineering becomes even more critical. Agentic systems must maintain context across extended workflows: what was the original goal, what actions have been taken, what results were observed, what remains to be done, and what constraints must be respected. This requires persistent memory, state management, and careful orchestration of context across multiple steps. Agents that lose track of their mission mid-workflow produce chaos. Context engineering prevents that drift.
The 12-Factor Agent framework – adapting classic software engineering principles for AI systems – emphasizes this: “Own your context window and control loop.” Agents must be designed with explicit context management, not implicit assumptions that the model will figure it out.
Implementation strategy
Assessing your context maturity
Before investing in context infrastructure, organizations should assess their current state across all five levels. For Level 1 (Schema), ask whether technical metadata is documented and accessible, whether AI systems can query schema information programmatically, and whether column names are descriptive or cryptic. For Level 2 (Relationships), examine whether data models are documented with relationship information, whether AI can traverse joins between tables, and whether foreign keys and cardinality rules are explicit.
Level 3 (Catalog) assessment focuses on whether a data catalog exists with business definitions, whether it’s populated and maintained, and whether AI can access catalog information at query time. Level 4 (Semantic) examines whether metric definitions are centralized or scattered, whether different tools use different calculation logic, and whether business rule encoding is accessible to AI systems. Level 5 (Memory) asks whether successful query patterns are captured, whether AI systems learn from corrections, and whether user preference information personalizes responses.
Most organizations discover significant gaps. The goal isn’t to achieve perfection immediately but to understand the baseline and prioritize investments.
The incremental path
Context engineering success doesn’t require comprehensive transformation. Start focused and build incrementally.
Phase 1: Foundation (Months 1-3) begins with selecting a single high-value domain like customer analytics. Document Level 1 and Level 2 context for that domain, implement basic retrieval from a knowledge base, and measure accuracy on a set of representative queries.
Phase 2: Business Logic (Months 4-6) adds Level 3 catalog information for the pilot domain and implements Level 4 semantic layer for key metrics, integrating with existing BI definitions where possible. Compare accuracy to Phase 1 baseline to demonstrate progress.
Phase 3: Learning (Months 7-9) implements feedback capture mechanisms and begins Level 5 memory and learning capabilities. Analyze error patterns and address them systematically while expanding to adjacent domains.
Phase 4: Scale (Months 10-12) extends context architecture to additional domains, implements cross-domain context spanning multiple areas, builds automated context quality monitoring, and plans enterprise-wide rollout.
Each phase builds on the previous, demonstrating value incrementally while developing organizational capability.
The context engineering role
Gartner recommends organizations appoint dedicated Context Engineering Leads integrated with AI and governance teams. This isn’t just another title – it’s recognition that context curation requires explicit ownership.
Context Engineering responsibilities span architecture (designing how context flows from sources to AI systems), curation (ensuring context sources are accurate, complete, and current), integration (connecting new data sources and tools to the context pipeline), quality (monitoring context quality and addressing degradation), governance (ensuring context respects access controls and privacy requirements), and optimization (improving context assembly for accuracy and efficiency).
This role bridges traditional data engineering (moving data) with AI operations (deploying models). Neither function alone has the complete picture; Context Engineering connects them.
Common pitfalls
Organizations implementing context engineering frequently stumble in predictable ways.
The first pitfall is treating problems as prompt issues. When AI produces wrong answers, the instinct is to refine the prompt, but often the real problem is missing or incorrect context. Before adjusting prompts, validate that the right information is reaching the model. The second is over-engineering the schema – attempting comprehensive ontologies before proving value. Start with a minimal viable context architecture, just enough structure to answer real questions, and expand based on usage patterns.
Ignoring permissions is the third common mistake. Context must respect access controls, and building retrieval systems that surface information users shouldn’t see creates compliance and security risks. Embed permission checks into retrieval, not just the user interface. Fourth, many teams treat embeddings as sufficient. Vector embeddings enable semantic similarity search, but similarity isn’t relevance – a document that seems related based on word patterns might not actually answer the question. Hybrid approaches combining vectors with graph constraints outperform either alone.
The fifth pitfall is neglecting feedback loops. Context engineering requires continuous refinement through capturing user acceptance, corrections, and usage patterns. Analyze errors to identify context gaps. Systems that don’t learn from experience plateau at mediocre accuracy.
The competitive dimension
Context as strategic asset
The 95% failure rate in enterprise AI isn’t just a technology problem – it’s a competitive opportunity. Organizations that master context engineering create durable advantages that are difficult for competitors to replicate.
Every interaction captured, every correction incorporated, every pattern learned makes the context architecture more valuable. Unlike models that any competitor can license, organizational context is proprietary – it accumulates uniquely within each organization. This accumulated knowledge creates compounding returns: better context produces more accurate answers, which produces more user trust, which produces more usage, which produces more feedback for improvement. The flywheel creates accelerating advantage.
As context-aware AI becomes embedded in operational processes, it becomes infrastructure. Switching costs increase. The organization’s institutional knowledge becomes encoded in systems that competitors can’t easily replicate. Gartner’s guidance is explicit: organizations moving to context-rich AI solutions see greater productivity gains and lower misinformation risks. The investment in context engineering pays dividends across every AI use case – not just isolated applications.
The window is closing
The 95% failure rate won’t persist indefinitely. As context engineering matures as a discipline, more organizations will achieve success. The early movers – those building context infrastructure now – will establish advantages before the practice becomes table stakes.
Consider the progression: 2024-2025 saw context engineering emerge as a recognized discipline, 2026-2027 will see leaders demonstrate measurable competitive advantage, and by 2028-2030 context architecture becomes a baseline expectation. Organizations starting in 2028 will face competitors with three years of accumulated context, refined pipelines, and embedded workflows. Catching up will be significantly harder than leading.
The time to invest is now – not when the discipline is mature but while competitive advantage is still available to early movers.
Key takeaways
-
95% of enterprise AI pilots fail – and prompt engineering isn’t the solution. MIT research shows most failures stem from information environment problems, not instruction quality. Prompts represent only 5% of enterprise AI success factors.
-
Context engineering is the practice of filling the context window with the right information. Beyond prompts, it includes retrieved knowledge, tool outputs, conversation history, business rules, relationship data, and user preferences – orchestrated dynamically at runtime.
-
The five-level context architecture determines accuracy. Physical schema (10-20% accuracy alone), relationships (25-40%), data catalog (50-65%), semantic layer (75-85%), and memory/learning (94-99% with all five). The gap is transformative versus useless.
-
Data integration isn’t context integration. Organizations successfully integrated data over decades but left context fragmented across schemas, catalogs, BI tools, and analyst minds. AI working with fragments produces unreliable answers.
-
Knowledge graphs triple zero-shot accuracy. Expressing metadata semantically using graph structures aligns with how LLMs work. LinkedIn achieved 78% accuracy improvement and 63% faster resolution times combining RAG with knowledge graphs.
-
MCP standardizes context access. Model Context Protocol, adopted by all major AI providers, solves the integration problem – organizations implement MCP servers once rather than building custom connections for each AI application and data source.
-
Production systems build context pipelines, not clever prompts. Query understanding, retrieval orchestration, context assembly, generation, and feedback loops form an integrated system for dynamically assembling information.
-
Gartner recommends dedicated Context Engineering Leads. The role bridges data engineering and AI operations – designing architecture, curating sources, monitoring quality, and ensuring governance across the context pipeline.
-
Context is a strategic asset competitors can’t license. Unlike models available to anyone, organizational context is proprietary. Better context creates compounding returns: more accuracy, more trust, more usage, more feedback.
-
The competitive window is closing. Early movers building context infrastructure now will establish three-year advantages before the practice becomes table stakes. Organizations starting late face embedded workflows and accumulated knowledge they can’t easily replicate.
Frequently asked questions
What is context engineering?
Context engineering is the practice of orchestrating all information pieces that an AI model processes into the right information state at runtime. It goes beyond prompts to include retrieved knowledge, tool outputs, conversation history, business rules, relationship information, and user preferences – everything the model sees beyond the immediate query.
Why does Gartner say “context engineering is in, prompt engineering is out”?
Gartner’s October 2025 guidance recognizes that prompts represent only about 5% of what makes enterprise AI successful. The remaining 95% depends on the information environment surrounding those prompts. Organizations investing heavily in prompt crafting while neglecting context see minimal improvement versus comprehensive context investment.
What is the five-level context architecture?
Promethium.ai’s framework identifies five levels: Level 1 (Physical Schema – column names, data types), Level 2 (Relationships – join paths, foreign keys), Level 3 (Data Catalog – business definitions), Level 4 (Semantic Layer – metric definitions, business rules), and Level 5 (Memory/Learning – query patterns, user preferences). Organizations achieving all five levels report 94-99% AI accuracy.
What accuracy do organizations achieve at each context level?
Research shows dramatic accuracy differences: Level 1 only achieves 10-20% accuracy, Levels 1-2 reach 25-40%, Levels 1-3 reach 50-65%, Levels 1-4 reach 75-85%, and all five levels achieve 94-99%. The gap between fragmented and comprehensive context determines whether AI initiatives succeed or fail.
Why do knowledge graphs improve AI accuracy?
Knowledge graphs represent data as networks of interconnected entities and relationships, aligning naturally with how LLMs work. Research shows expressing metadata semantically using knowledge graph structures can triple zero-shot accuracy without model training. LinkedIn reported 78% accuracy improvement combining RAG with knowledge graphs.
What is the role of MCP in context engineering?
Model Context Protocol (MCP) provides a universal interface for connecting AI systems to context sources – documents, databases, APIs, and tools. Adopted by Anthropic, OpenAI, Google, and Microsoft, MCP standardizes how AI systems access resources, execute functions, and reuse patterns, solving the integration problem for context pipelines.
What is the typical context engineering pipeline?
Production systems include query understanding (intent classification, entity extraction), retrieval orchestration (vector search, graph traversal, API calls), context assembly (relevance ranking, deduplication, formatting, token budgeting), generation layer (system prompts, retrieved context, user query), and feedback loops (capturing corrections and usage patterns).
What common pitfalls derail context engineering initiatives?
Key pitfalls include treating problems as prompt issues when context is missing, over-engineering schemas before proving value, ignoring permissions in retrieval systems, treating vector embeddings as sufficient without graph constraints, and failing to implement feedback loops for continuous improvement.
Why is context engineering a competitive advantage?
Unlike models that any competitor can license, organizational context is proprietary. Better context produces more accurate answers, more trust, more usage, and more feedback – creating compounding returns. As context-aware AI becomes embedded in workflows, switching costs increase and competitors can’t easily replicate institutional knowledge.
What role should organizations create for context engineering?
Gartner recommends dedicated Context Engineering Leads integrated with AI and governance teams. Responsibilities include architecture design, context source curation, integration of new sources, quality monitoring, governance enforcement, and optimization. This role bridges data engineering and AI operations.
Sources
- Anthropic Research - Research on AI model capabilities and context window optimization from Claude’s developer
- Stanford HAI (Human-Centered AI Institute) - Academic research on enterprise AI implementation and failure rates
- arXiv - Preprint repository for AI research papers on RAG, knowledge graphs, and retrieval systems
- Databricks - Enterprise data platform documentation on vector databases and semantic layers
- Salesforce Resources - Enterprise CRM integration patterns for AI context assembly
Research and industry benchmarks current as of late 2025. Enterprise AI implementation varies by organization and data maturity. Verify specific accuracy claims through pilot testing in your environment.