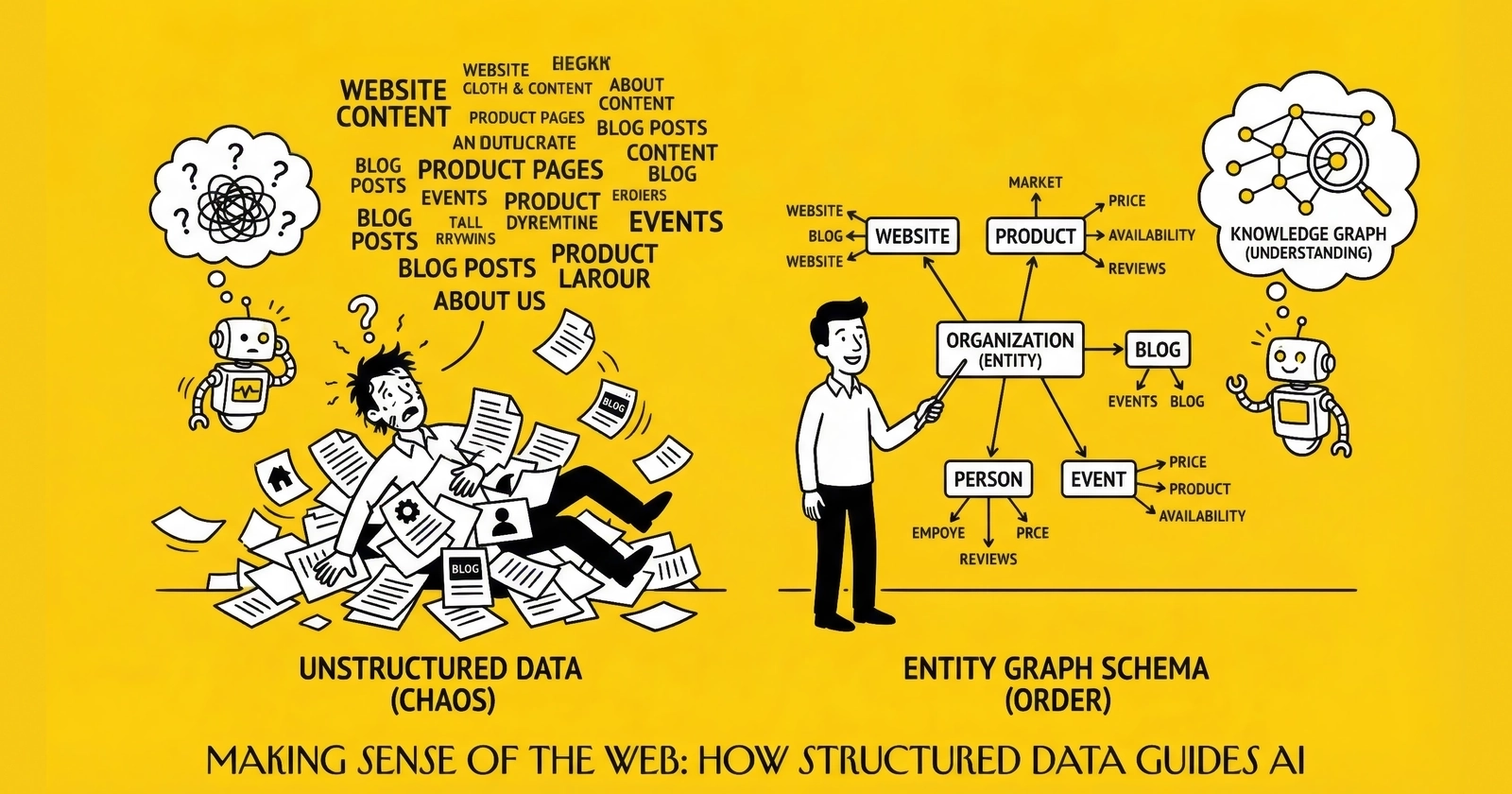
Schema markup has historically been a page-level optimization. Implement Organization schema on your homepage. Add Article schema to blog posts. Mark up FAQ pages for rich snippets. Each implementation sits in isolation, optimized independently.
This approach worked for traditional search, where Google processed pages individually based on content quality and authority signals. Improve individual pages, improve overall visibility.
The shift to AI-driven search changes this calculation fundamentally. When AI systems encounter your content, they’re not just reading it. They’re mapping it into knowledge graphs – vast networks of interconnected entities and relationships. They’re asking how your products relate to your industry. How your executives relate to your organizational expertise. How your content topics relate to broader knowledge domains.
LLMs integrated with knowledge graphs achieve 300% higher accuracy than those without structured entity data. For lead generation companies, this means the difference between being cited as an authoritative source and being ignored entirely. Understanding how the lead economy works provides essential context for why entity relationships matter so much in this industry.
From Page Markup to Entity Architecture
Understanding why entity relationships matter requires stepping back to knowledge graph fundamentals. Knowledge graphs are built from RDF triples – subject-predicate-object statements that capture relationships.
A simple example:
- Subject: “Sarah Chen”
- Predicate: “worksFor”
- Object: “LeadGen Solutions”
This single triple captures a relationship. Thousands of these triples, connected together, form a knowledge graph. Google’s Knowledge Graph contains over 500 billion facts structured as triples.
When you implement schema markup, you’re creating triples about your business. Every schema property is a predicate. Every entity is a subject or object. Together, they form a semantic description of your business that machines process and reason about.
The difference between basic and sophisticated implementations: sophisticated implementations create networks of triples that tell a coherent story, not isolated facts.
Isolated vs. Connected Implementations
Basic Implementation (Isolated Triples):
- Product page: “LeadFlow Pro” has “Price: $299/month”
- Product page: “LeadFlow Pro” has “Rating: 4.8 stars”
- Team page: “Michael Torres” is “VP of Sales”
- Organization page: “LeadGen Solutions” is “located in Austin, TX”
Each triple is accurate but disconnected. AI systems know individual facts without understanding the relationships between them.
Advanced Implementation (Connected Triples):
- “LeadFlow Pro” has “Price: $299/month”
- “LeadFlow Pro” has “Rating: 4.8 stars”
- “LeadFlow Pro” is “offered by” “LeadGen Solutions”
- “Michael Torres” “worksFor” “LeadGen Solutions”
- “Michael Torres” is “author of” “5 Articles About Lead Distribution”
- “LeadGen Solutions” is “headquartered in” “Austin, TX”
- “Sarah Chen” is “founder of” “LeadGen Solutions”
- “Sarah Chen” has “knowsAbout” “Lead Distribution, TCPA Compliance, Ping/Post Systems”
Now AI systems see relationships. They understand that Michael Torres is connected to LeadGen Solutions, which offers LeadFlow Pro, which relates to lead distribution – the same topic he writes about. The organization’s location provides geographic context. The founder’s expertise signals topical authority.
This second approach is what AI systems increasingly prioritize. It’s the difference between markup and knowledge infrastructure.
Entity Types for Lead Generation Companies
Different entities fall into different classes, each with specific properties and relationship opportunities. For lead generation companies, the entity landscape typically includes:
Organization Entities
Your company itself forms the foundation. Organization schema should include:
{
"@context": "https://schema.org",
"@type": "Organization",
"@id": "https://leadgensolutions.com/#organization",
"name": "LeadGen Solutions",
"legalName": "LeadGen Solutions, Inc.",
"url": "https://leadgensolutions.com",
"logo": "https://leadgensolutions.com/logo.png",
"foundingDate": "2018",
"numberOfEmployees": {
"@type": "QuantitativeValue",
"value": 85
},
"address": {
"@type": "PostalAddress",
"streetAddress": "500 Congress Ave, Suite 400",
"addressLocality": "Austin",
"addressRegion": "TX",
"postalCode": "78701"
},
"sameAs": [
"https://www.linkedin.com/company/leadgen-solutions",
"https://www.crunchbase.com/organization/leadgen-solutions",
"https://twitter.com/leadgensolutions"
]
}The @id property creates a stable identifier that other entities can reference. Every time another page references your organization, it should point to this same @id.
Person Entities
Key individuals – founders, executives, thought leaders – should have Person schema linking them to the organization:
{
"@context": "https://schema.org",
"@type": "Person",
"@id": "https://leadgensolutions.com/team/sarah-chen/#person",
"name": "Sarah Chen",
"jobTitle": "Chief Executive Officer",
"image": "https://leadgensolutions.com/team/sarah-chen.jpg",
"worksFor": {
"@id": "https://leadgensolutions.com/#organization"
},
"knowsAbout": [
"Lead Generation",
"Lead Distribution Systems",
"TCPA Compliance",
"Ping/Post Technology"
],
"sameAs": [
"https://www.linkedin.com/in/sarah-chen-leadgen",
"https://twitter.com/sarahchen_leads"
]
}The knowsAbout property signals expertise areas. The worksFor property creates the organizational relationship. The sameAs links verify identity across platforms.
Product/Service Entities
Lead generation offerings should use Service or SoftwareApplication schema:
{
"@context": "https://schema.org",
"@type": "SoftwareApplication",
"@id": "https://leadgensolutions.com/products/leadflow-pro/#product",
"name": "LeadFlow Pro",
"applicationCategory": "Lead Distribution Software",
"operatingSystem": "Web-based",
"offers": {
"@type": "Offer",
"price": "299",
"priceCurrency": "USD",
"priceValidUntil": "2026-12-31"
},
"provider": {
"@id": "https://leadgensolutions.com/#organization"
},
"featureList": [
"Real-time lead routing",
"Ping/post integration",
"TCPA compliance tracking",
"Multi-buyer distribution"
],
"aggregateRating": {
"@type": "AggregateRating",
"ratingValue": "4.8",
"ratingCount": "247"
}
}The provider property links the product to your organization entity. featureList provides semantic detail about capabilities.
Content Entities
Articles and guides should link to their authors and publisher:
{
"@context": "https://schema.org",
"@type": "Article",
"@id": "https://leadgensolutions.com/blog/ping-post-guide/#article",
"headline": "Ping/Post Systems Explained: Real-Time Lead Auctions",
"author": {
"@id": "https://leadgensolutions.com/team/sarah-chen/#person"
},
"publisher": {
"@id": "https://leadgensolutions.com/#organization"
},
"datePublished": "2025-11-15",
"dateModified": "2026-01-05",
"about": [
"Ping/Post Systems",
"Real-Time Lead Distribution",
"Lead Auctions"
],
"wordCount": 4500
}The author reference uses the @id of the Person entity. The publisher references the Organization entity. These connections tell AI systems who created the content and what organization stands behind it.
The @id Property: Creating Entity Identity
The most powerful feature of JSON-LD schema is creating stable identifiers using the @id property. This is where entity relationships materialize.
Consider a typical scenario. Your CEO appears on multiple pages:
- Homepage: Organization schema mentioning the CEO as founder
- Team page: Person schema for the CEO
- Blog posts: Article schema with the CEO as author
- Press releases: NewsArticle schema mentioning the CEO
- Podcast page: Podcast schema with the CEO as host
Without entity identity, these are five separate mentions of a person. AI systems can’t confirm they’re the same individual.
With consistent @id usage, they reference the same entity:
// Homepage Organization schema
{
"@type": "Organization",
"@id": "https://leadgensolutions.com/#organization",
"founder": {
"@type": "Person",
"@id": "https://leadgensolutions.com/team/sarah-chen/#person"
}
}
// Team page Person schema
{
"@type": "Person",
"@id": "https://leadgensolutions.com/team/sarah-chen/#person",
"name": "Sarah Chen",
"jobTitle": "Chief Executive Officer",
"worksFor": {
"@id": "https://leadgensolutions.com/#organization"
}
}
// Blog post Article schema
{
"@type": "Article",
"@id": "https://leadgensolutions.com/blog/tcpa-guide/#article",
"author": {
"@id": "https://leadgensolutions.com/team/sarah-chen/#person"
},
"publisher": {
"@id": "https://leadgensolutions.com/#organization"
}
}Now AI systems understand that all pages discuss the same person in the same role. They connect the triples into a coherent understanding of Sarah Chen’s relationship to the organization and its content.
@id Patterns and Conventions
Establishing consistent @id patterns prevents fragmentation:
| Entity Type | Pattern | Example |
|---|---|---|
| Organization | domain.com/#organization | https://leadgen.com/#organization |
| Person | domain.com/team/[slug]/#person | https://leadgen.com/team/sarah-chen/#person |
| Product | domain.com/products/[slug]/#product | https://leadgen.com/products/leadflow/#product |
| Article | domain.com/blog/[slug]/#article | https://leadgen.com/blog/tcpa-guide/#article |
| FAQ | domain.com/faq/#faq | https://leadgen.com/faq/#faq |
| Location | domain.com/locations/[city]/#location | https://leadgen.com/locations/austin/#location |
The # fragment identifier is conventional for JSON-LD. It creates unique identifiers that don’t conflict with page URLs.
The sameAs Property: External Authority
If @id creates internal identity, sameAs creates external authority. The sameAs property links your entities to external sources where the same entity is described authoritatively.
Organization sameAs Links
"sameAs": [
"https://www.linkedin.com/company/leadgen-solutions",
"https://www.crunchbase.com/organization/leadgen-solutions",
"https://en.wikipedia.org/wiki/LeadGen_Solutions",
"https://www.wikidata.org/wiki/Q12345678",
"https://twitter.com/leadgensolutions",
"https://www.facebook.com/leadgensolutions",
"https://www.glassdoor.com/Overview/Working-at-LeadGen-Solutions"
]Person sameAs Links
"sameAs": [
"https://www.linkedin.com/in/sarah-chen-leadgen",
"https://twitter.com/sarahchen_leads",
"https://en.wikipedia.org/wiki/Sarah_Chen_(entrepreneur)"
]These external references matter because AI systems use them for verification. When you link to your Wikipedia page, you’re saying: “This is how this entity is described in a trusted, neutral source.” When you link to Crunchbase: “Here’s verified business information.”
This verification function is critical in an era where AI systems try to avoid hallucinations. If multiple independent sources describe you consistently, AI can cite you with confidence.
Building Your sameAs Portfolio
Audit your organization’s presence across platforms:
| Platform | Priority | Purpose |
|---|---|---|
| LinkedIn (Company) | High | Professional verification |
| Crunchbase | High | Business verification |
| Wikipedia | High (if applicable) | Authoritative description |
| Wikidata | High | Knowledge graph integration |
| Twitter/X | Medium | Social verification |
| Glassdoor | Medium | Employer verification |
| Industry directories | Medium | Domain authority |
| BBB | Low-Medium | Trust signal |
For executives and thought leaders:
- LinkedIn profiles (essential)
- Twitter/X accounts
- Wikipedia (if notable)
- Industry association profiles
- Conference speaker profiles
Organizations that systematically build these external references report better AI citation rates and more prominent knowledge panel appearances. This aligns with LLMO strategies for AI citation that prioritize verifiable authority signals.
Entity Linking to External Knowledge Bases
Wikidata is particularly important because it’s the authoritative source for Google’s Knowledge Graph. Linking to Wikidata involves:
Finding Wikidata Entities
- Search Wikidata.org for your organization, people, and products
- Note the Q number (e.g., Q12345678) for each entity
- Add the full URL to sameAs properties
Creating Wikidata Entries
If your organization isn’t in Wikidata but meets notability criteria:
Notability indicators:
- Significant news coverage in reliable sources
- Industry recognition or awards
- Substantial market presence or funding
- Recognition in trade publications
Creation process:
- Create a Wikidata account
- Add a new item with required properties (name, description, instance of)
- Add external identifiers (website, LinkedIn, etc.)
- Add statements (founded, headquarters, industry)
- Cite reliable sources for each statement
Wikidata entries can exist independently of Wikipedia articles. Many organizations have Wikidata entries without Wikipedia pages.
The Wikipedia Connection
If your organization has a Wikipedia article:
- There’s almost certainly a corresponding Wikidata entry
- Link to both in your sameAs properties
- Ensure consistency between your markup and Wikipedia/Wikidata descriptions
For lead generation companies, Wikipedia notability typically requires:
- Coverage in major business publications
- Significant funding rounds covered by press
- Industry leadership recognition
- Regulatory significance (e.g., involvement in major TCPA cases)
Topic Clusters as Semantic Architecture
Entity relationships extend beyond people and organizations to topics. Topic cluster architecture – pillar pages covering broad topics with satellite pages exploring subtopics – becomes semantic architecture when implemented with schema.
Lead Generation Topic Cluster Example
Pillar Page: “Lead Distribution Systems”
{
"@type": "Article",
"@id": "https://leadgen.com/guides/lead-distribution/#article",
"headline": "Complete Guide to Lead Distribution Systems",
"author": {
"@id": "https://leadgen.com/team/sarah-chen/#person"
},
"publisher": {
"@id": "https://leadgen.com/#organization"
},
"about": [
"Lead Distribution",
"Lead Routing",
"Ping/Post Systems"
]
}Satellite Page 1: “Ping/Post Technology”
{
"@type": "Article",
"@id": "https://leadgen.com/guides/ping-post/#article",
"headline": "Ping/Post Systems Explained",
"about": "Ping/Post Technology",
"isPartOf": {
"@id": "https://leadgen.com/guides/lead-distribution/#article"
}
}Satellite Page 2: “Multi-Buyer Distribution”
{
"@type": "Article",
"@id": "https://leadgen.com/guides/multi-buyer/#article",
"headline": "Multi-Buyer Lead Distribution Strategies",
"about": "Multi-Buyer Distribution",
"isPartOf": {
"@id": "https://leadgen.com/guides/lead-distribution/#article"
}
}For detailed strategies on multi-buyer lead distribution, connecting content entities to operational guides creates valuable semantic relationships.
Product Page Connecting to Topic Content:
{
"@type": "SoftwareApplication",
"@id": "https://leadgen.com/products/leadflow/#product",
"name": "LeadFlow Distribution Platform",
"about": [
"Lead Distribution",
"Ping/Post Technology",
"Multi-Buyer Distribution"
],
"mentions": [
{
"@id": "https://leadgen.com/guides/lead-distribution/#article"
},
{
"@id": "https://leadgen.com/guides/ping-post/#article"
}
]
}Now AI systems understand:
- Your product relates to multiple topic areas
- Your content covers those topics comprehensively
- Content and product are semantically related
- Your organization has topical authority in lead distribution
This semantic structure enables better AI citations. When an AI answers questions about ping/post systems, it sees you’ve covered the topic comprehensively, linked to related topics, and have products serving this market. Understanding organic SEO strategies for lead generation complements this semantic approach with traditional authority-building techniques.
E-E-A-T Signals Through Entity Architecture
Google’s E-E-A-T framework – Experience, Expertise, Authoritativeness, Trustworthiness – is communicated more effectively through structured entities than unstructured text.
Experience Signals
Entity architecture demonstrates experience through:
| Signal | Implementation |
|---|---|
| Author background | Person schema with jobTitle, work history, years in industry |
| First-hand knowledge | knowsAbout property listing specific expertise areas |
| Operational involvement | Articles authored by people with operational roles |
| Case study attribution | Connecting case studies to authors who led the work |
Expertise Signals
| Signal | Implementation |
|---|---|
| Credentials | hasCredential or hasOccupation properties |
| Topic depth | Multiple articles by same author in expertise area |
| Content comprehensiveness | Topic clusters with isPartOf relationships |
| Industry recognition | award properties on Person and Organization |
Authoritativeness Signals
| Signal | Implementation |
|---|---|
| External verification | sameAs links to Wikipedia, Wikidata, authoritative sources |
| Industry recognition | Organization mentions in reliable publications |
| Third-party validation | Review schema with aggregate ratings |
| Citation network | Content linked from external authoritative sources |
Trustworthiness Signals
| Signal | Implementation |
|---|---|
| Consistent identity | Same @id used across all entity references |
| Current information | dateModified property kept current |
| Transparent ownership | Clear Organization schema with contact info |
| Compliance signals | Privacy policy, terms pages linked |
Implementation for Lead Generation Verticals
Entity graph architecture varies by lead generation vertical. Different verticals require different entity emphasis.
Insurance Lead Generation
Priority entities:
- Organization with insurance industry associations
- People with insurance licenses, credentials
- Products with specific insurance line focus
- Content covering TCPA, state regulations, carrier relationships
Key relationships:
- Licensed agents as authors of compliance content
- Products linked to specific insurance lines (auto, home, life, health)
- Location entities for state-specific operations
Mortgage Lead Generation
Priority entities:
- Organization with mortgage industry affiliations (MBA, etc.)
- People with MLO credentials, NMLS numbers
- Products categorized by loan type
- Content covering rate environments, qualification criteria
Key relationships:
- Licensed loan officers as content authors
- Products linked to loan types (conventional, FHA, VA, jumbo)
- Content linked to rate trend analysis, market conditions
Home Services Lead Generation
Priority entities:
- Organization as LocalBusiness with service areas
- Location entities for each service market
- Service entities for each trade (HVAC, plumbing, roofing)
- Content organized by service type and location
Key relationships:
- Location entities linked to service offerings
- Content tailored to geographic markets
- Reviews aggregated by location and service
Legal Lead Generation
Priority entities:
- Organization with bar associations, legal directories
- Attorney entities with bar numbers, practice areas
- Service entities for case types
- Content covering case qualification, legal standards
Key relationships:
- Attorneys as authors of legal content
- Case types linked to qualification criteria
- Compliance content linked to ethical requirements
Progressive Implementation Roadmap
Building comprehensive entity graphs takes time. A phased approach prevents overwhelm while producing incremental value.
Phase 1: Foundation (Weeks 1-4)
Objectives:
- Establish Organization schema with comprehensive properties
- Create stable @id patterns for organization entity
- Audit and populate external profiles (LinkedIn, Crunchbase)
- Document organizational structure for later phases
Deliverables:
- Organization schema on homepage
- sameAs links to verified external profiles
- @id pattern documentation
- External profile audit and optimization
Phase 2: People (Weeks 5-8)
Objectives:
- Create Person schemas for key individuals
- Link people to Organization using worksFor
- Populate sameAs links for each person
- Create team pages with linked Person markup
Deliverables:
- Person schema for 5-20 key individuals
- Team page with structured data
- Author pages for content creators
- External profile optimization for individuals
Phase 3: Content Authority (Weeks 9-12)
Objectives:
- Implement Article schema across content
- Link articles to People (authors) and Organization (publisher)
- Mark up topic clusters with isPartOf relationships
- Use about and mentions properties for topical linking
Deliverables:
- Article schema on all blog posts
- Author attribution in schema (not just bylines)
- Topic cluster semantic structure
- FAQ schema on relevant pages
Phase 4: Products and Services (Weeks 13-16)
Objectives:
- Implement Service or SoftwareApplication schema
- Link products to organization
- Connect products to related content
- Mark up features, reviews, pricing
Deliverables:
- Product/Service schema on offering pages
- Feature lists in structured data
- Review aggregation schema
- Product-content semantic connections
Phase 5: Topical Authority (Weeks 17+)
Objectives:
- Build comprehensive topic coverage
- Link content to external authority sources
- Create semantic density around key topics
- Monitor and optimize based on AI visibility
Deliverables:
- Pillar content for each major topic
- External references in about properties
- Topic glossary pages with structured data
- Ongoing optimization process
Measuring Entity Graph Effectiveness
Entity graph effectiveness is harder to quantify than traditional SEO metrics. Measurement requires multiple dimensions.
Search Console Monitoring
Enhancement reports: Track entity-related enhancements and errors.
Rich result status: Monitor which pages show rich results.
Structured data errors: Address validation issues promptly.
Manual AI Testing
Brand queries: Search for your company in ChatGPT, Perplexity, Google AI Overview. Are you mentioned? Is information accurate?
Topic queries: Search for topics you cover. Does your content appear in AI responses?
Competitor comparison: How do AI responses about competitors compare to your visibility?
Knowledge Panel Tracking
Panel appearance: Does your organization have a Google Knowledge Panel?
Panel accuracy: Is the information correct and current?
Panel completeness: Are sameAs links reflected in the panel?
Entity Consistency Audit
@id consistency: Are the same entities referenced with the same @id across all pages?
sameAs coverage: Are external profiles linked consistently?
Relationship accuracy: Do entity relationships reflect current reality?
Advanced Measurement
For organizations with engineering resources:
- API querying: Systematically query AI APIs and measure citation frequency
- Knowledge Graph API: Monitor Google’s Knowledge Graph API for your entities
- Training data tracking: Track when content appears in AI system updates
- Correlation analysis: Connect entity improvements to Search Console metrics
Common Entity Graph Mistakes
Organizations implementing entity architecture frequently make these errors.
Inconsistent @id Usage
The mistake: Using different @id patterns on different pages for the same entity.
The problem: AI systems see multiple entities instead of one connected entity.
The fix: Establish @id conventions and audit all pages for consistency.
Missing sameAs Links
The mistake: Implementing entity schema without external verification links.
The problem: AI systems can’t verify your entities against trusted sources.
The fix: Audit external presence and link to verified profiles systematically.
Orphaned Entities
The mistake: Creating Person or Product entities without linking them to Organization.
The problem: Entities float without organizational context.
The fix: Every Person should worksFor Organization. Every Product should have provider Organization.
Stale Entity Information
The mistake: Not updating schema when reality changes (title changes, people leave, products retire).
The problem: AI systems cite outdated or incorrect information.
The fix: Include schema updates in organizational change processes.
Over-Markup
The mistake: Creating entities for everything – every employee, every minor product, every event.
The problem: Signal-to-noise ratio decreases. Important entities get lost.
The fix: Limit entities to those significant enough for public identification.
Ignoring Validation
The mistake: Implementing schema without testing in Google’s Rich Results Test or Schema Markup Validator.
The problem: Errors prevent processing, wasting implementation effort.
The fix: Validate every page before deployment. Monitor Search Console for new errors.
The Competitive Advantage Window
Less than 30% of websites implement schema markup effectively. Even fewer build comprehensive entity graphs. The opportunity to establish authority through entity architecture is available now but closing.
As more organizations implement sophisticated structured data:
- AI systems will have more sources to choose from
- Differentiation will require greater entity completeness
- Early movers will have established authority signals
Organizations that build entity graph infrastructure now position themselves for compounding benefits:
- Each new piece of content inherits organizational authority
- Each new author inherits organizational credibility
- Each new product connects to established topical authority
Entity graphs are infrastructure investments, not tactical optimizations. The returns compound over time as semantic connections deepen.
Key Takeaways
-
Entity relationships outperform isolated page markup. Connected knowledge graphs produce better AI visibility than individually optimized pages. AI systems with knowledge graph integration achieve 300% higher accuracy.
-
The @id property creates entity connections. Consistent @id URIs across pages allow AI systems to understand multiple references describe the same entity. Without @id, your entities fragment.
-
sameAs properties establish external verification. Linking to Wikipedia, Wikidata, LinkedIn, and authoritative sources increases AI citation confidence. Multiple independent sources describing you consistently enables confident citation.
-
Topic clusters become semantic architecture. Using isPartOf relationships and about properties transforms content organization from navigational to semantic – the structure AI systems process.
-
E-E-A-T signals communicate through entity structure. Experience, expertise, authoritativeness, and trustworthiness demonstrate more effectively through structured relationships than unstructured text.
-
Progressive implementation prevents overwhelm. Building entity graphs in phases over 4-6 months creates sustainable results. Each phase builds on previous work.
-
Lead generation verticals require tailored approaches. Insurance, mortgage, home services, and legal lead generation each emphasize different entity types and relationships.
-
Measurement requires multiple dimensions. Track Search Console enhancements, manual AI queries, knowledge panel appearances, and entity consistency audits.
-
Wikidata integration provides knowledge graph connection. Linking to Wikidata connects your entities to Google’s Knowledge Graph foundation, enabling disambiguation and verification.
-
The competitive window is open but closing. Less than 30% of organizations implement schema effectively. Early entity graph builders establish authority that compounds over time.
Frequently Asked Questions
What is an entity graph in the context of AI search?
An entity graph is a network of connected entities – people, organizations, products, concepts – and their relationships, represented through structured data like JSON-LD schema. AI systems use entity graphs to understand context, verify information, and determine citation confidence. When your schema markup creates connected entities rather than isolated page-level markup, you’re building an entity graph that AI can reason about.
How do entity graphs improve AI search visibility?
LLMs integrated with knowledge graphs achieve 300% higher accuracy than those operating without structured entity data. Entity graphs provide AI systems with verified, structured relationships that reduce hallucination risk and increase citation confidence. When AI can see how your content connects to verified organizations, credentialed authors, and established topics, it can cite you with confidence.
What’s the difference between schema markup and entity graphs?
Basic schema markup describes individual pages – this page is an Article, this page is a Product. Entity graphs connect those pages into semantic networks. A Product page with schema is useful but limited. A Product page linked to its manufacturer organization, connected to the team who built it, and associated with content that explains it forms an entity graph. The difference is isolation versus connection.
What is the @id property and why does it matter?
The @id property creates stable identifiers for entities in JSON-LD schema markup. Using consistent @id URIs across pages allows AI systems to understand that multiple references describe the same entity. Without @id, your CEO mentioned on five different pages appears as five separate people to AI systems. With consistent @id usage, they’re recognized as the same individual with accumulated authority.
How do sameAs links affect AI visibility?
sameAs links connect your entities to external authoritative sources – Wikipedia, Wikidata, LinkedIn, Crunchbase. AI systems use these connections for verification. When multiple independent sources describe your organization consistently, AI systems can cite you with higher confidence. Organizations with comprehensive sameAs link portfolios report higher AI citation rates and better knowledge panel representation.
What entities should lead generation companies prioritize?
Start with Organization (your company and its key properties), then People (founders, executives, thought leaders who create content), then Products/Services (your lead generation offerings), then Articles (your authoritative content). Connect these entities with relationship properties like worksFor, author, publisher, and offers. This creates a semantic foundation that AI systems can process and verify. For foundational understanding, see our guide on what lead generation actually is.
How do entity graphs support E-E-A-T signals?
Entity graphs communicate E-E-A-T more effectively than unstructured text. Experience shows through author credentials linked to content. Expertise demonstrates through topic clusters and author depth. Authoritativeness establishes through sameAs links to verified sources. Trustworthiness proves through consistent identification across pages. E-E-A-T isn’t just content quality – it’s structured proof of credibility.
How long does it take to build a comprehensive entity graph?
A phased approach typically takes 4-6 months for comprehensive implementation. Phase 1 (weeks 1-4): Organization foundation and external profiles. Phase 2 (weeks 5-8): People entities and team structure. Phase 3 (weeks 9-12): Content authority and author attribution. Phase 4 (weeks 13-16): Products, services, and offerings. Each phase builds on previous work for compounding benefits.
Should I link to Wikidata if my company isn’t on Wikipedia?
Wikidata entries can exist independently of Wikipedia articles. If your company meets Wikidata’s notability criteria – significant news coverage, industry recognition, market presence, or funding – you can create an entry directly. Wikidata provides verified entity identification that AI systems reference for disambiguation and verification.
How do I measure entity graph effectiveness?
Track multiple dimensions: Search Console enhancement reports for structured data processing, manual AI queries about your brand and topics, knowledge panel appearances and accuracy, and entity consistency audits across your site. Entity graph effectiveness compounds over time – initial changes may take weeks to reflect in AI system behavior.
Can entity graphs help with local lead generation?
Yes, entity graphs are particularly valuable for local operations. LocalBusiness schema with location entities, local team members, and location-specific content creates semantic signals for local search and maps visibility. For multi-location operations, entity graphs help AI systems disambiguate between locations and understand the relationship between local offices and parent organization.
What’s the relationship between entity graphs and topic clusters?
Topic clusters become semantic architecture when implemented with entity relationships. Using isPartOf to connect satellite content to pillar pages, about properties to link content to topic concepts, and mentions to connect products to related content transforms content organization from purely navigational to semantic. This semantic structure is what AI systems understand and use for topical authority assessment.
Sources
- Google Structured Data Documentation - Official Google guidelines for implementing structured data and JSON-LD markup
- Schema.org Full Hierarchy - Complete documentation of schema types, properties, and relationships for entity markup
- W3C JSON-LD 1.1 Specification - Technical standard for JSON-LD format used in structured data implementation
- Wikidata Introduction - Guide to creating and linking entities in the Wikidata knowledge base
- Google Rich Results Test - Google’s official tool for validating structured data implementation
- Schema Markup Validator - Schema.org’s validation tool for testing JSON-LD and other structured data formats