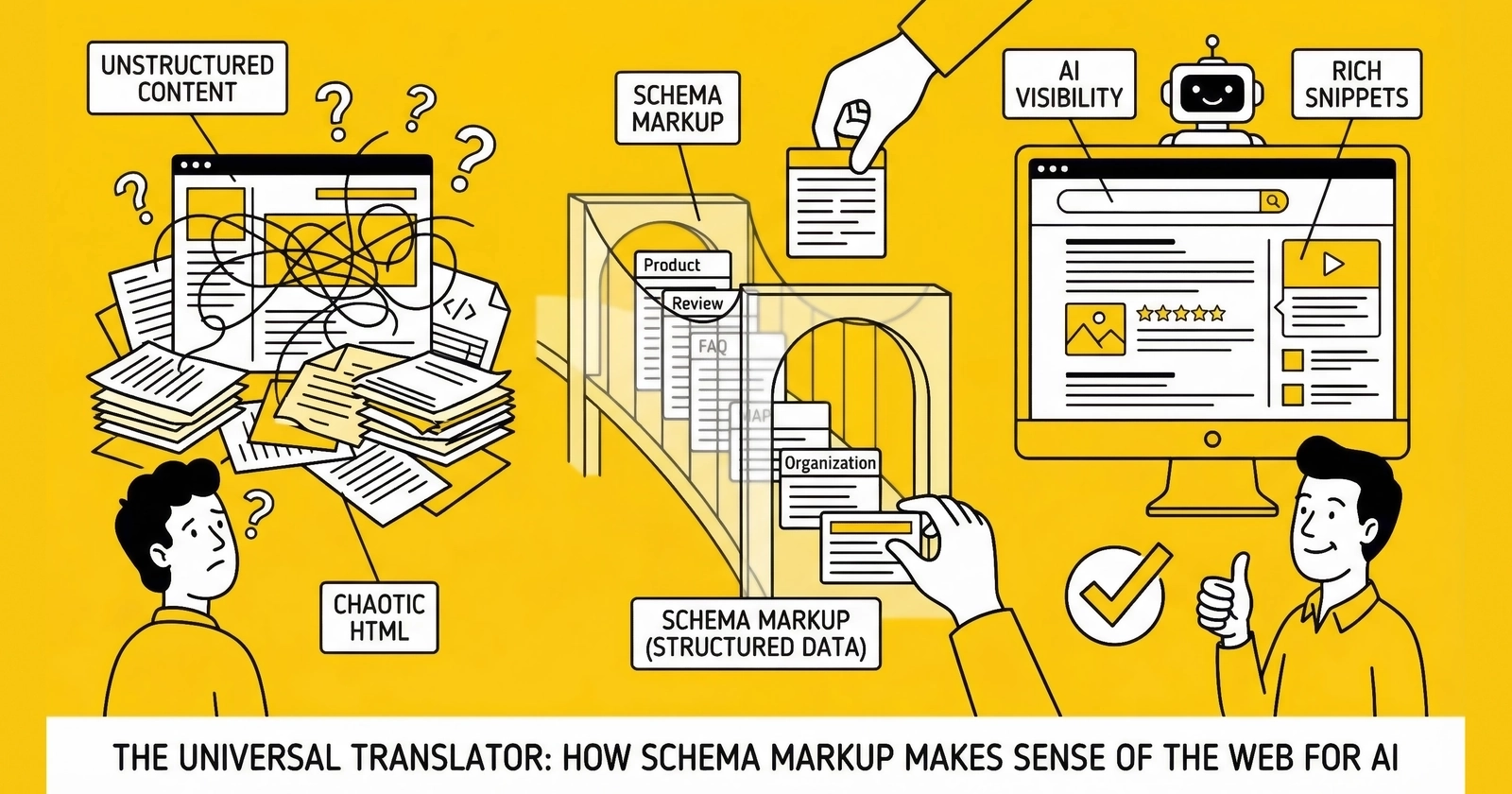
Pages with comprehensive schema markup are 3x more likely to appear in AI Overviews. Language models achieve 300% higher accuracy with structured data. Less than 30% of websites implement schema effectively. The competitive advantage window is open – but narrowing.
A lead generation company publishes a comprehensive guide to TCPA compliance. The content is authoritative, well-researched, and regularly updated. It ranks position four for target keywords. When users ask ChatGPT about TCPA consent requirements, the guide doesn’t appear in responses.
A competitor’s guide ranks position seven – three positions lower. But their page includes comprehensive schema markup: Article schema with author credentials, FAQPage schema for common questions, Organization schema establishing company authority. When users ask ChatGPT the same questions, this competitor gets cited.
The difference isn’t content quality. Both guides are excellent. The difference is structured data. AI systems could parse the competitor’s content structure, verify author credentials, and extract specific answers. The first company’s content required inference – and inference introduces uncertainty that AI systems avoid.
This is schema markup in the AI era. It’s not about rich snippets anymore. It’s about whether artificial intelligence trusts your content enough to cite it. Understanding how LLMO strategies differ from traditional SEO helps contextualize why structured data matters so much for AI visibility.
From Rich Snippets to AI Infrastructure
The traditional pitch for schema markup was straightforward: implement structured data, earn rich snippets, increase click-through rates. Food Network reported 35% traffic increases. Rotten Tomatoes saw 25% higher CTR on pages with schema. These were measurable gains.
That narrative hasn’t disappeared, but it’s been overshadowed by something larger. The question isn’t whether schema improves search results – it does. The question is whether AI systems cite your content at all.
The 3x AI Overview Visibility Factor
According to BrightEdge research, pages with comprehensive schema markup are three times more likely to appear in Google AI Overviews. This isn’t a minor optimization. It’s the difference between visibility to millions of users and complete invisibility in the fastest-growing search interface.
The numbers compound:
| Metric | Impact |
|---|---|
| AI Overview appearance | 3x more likely with schema |
| LLM accuracy | 300% higher with knowledge graphs |
| AI citation sources | 82.5% from pages with structured data |
| Effective adoption | <30% of websites |
That last statistic – less than 30% effective adoption – represents a significant competitive advantage window. Organizations implementing comprehensive schema now, while most competitors haven’t, establish visibility advantages that compound over time. For a comprehensive overview of the industry these practices apply to, see our guide on how the lead economy works.
Why Language Models Prefer Structured Data
When an AI system generates a response, it needs to verify information before presenting it. Structured data makes verification possible. It provides clear, machine-readable signals about:
- What content says (Article, FAQ, HowTo schemas)
- Who wrote it (Person, author attribution)
- When it was published (datePublished, dateModified)
- Where expertise comes from (credentials, Organization affiliation)
Unstructured text requires inference. Inference introduces hallucination risk. Hallucination erodes user trust. This creates a direct incentive for AI systems to prioritize structured, well-marked content.
They’re not doing it because anyone mandated it. They’re doing it because structured data produces better answers.
The Knowledge Graph Connection
Understanding the mechanism requires looking at how AI systems process information at scale. Google’s Knowledge Graph contains billions of facts and entities. When an AI system encounters content, it tries to connect that content to entities it already understands.
If your schema markup clearly identifies the entities your content discusses – using properties like @type, @id, and sameAs – the AI system can immediately ground your content in its knowledge framework. It knows your company exists. It understands your author’s credentials. It can verify claims against what it already knows.
Without schema markup, the AI system makes these connections through inference. That process is inherently uncertain.
Priority Schema Types for Lead Generation
Not all schema types deliver equal value for lead generation businesses. Prioritization matters.
Organization Schema – The Foundation
Every schema implementation begins with Organization schema on your homepage. This isn’t optional – it’s the foundation everything else builds on.
Organization schema tells AI systems:
- Your company’s legal name and identity
- Your address and contact information
- Your logo and brand identity
- URLs where your brand is verified (LinkedIn, industry directories)
- Your company description and industry
Implementation for lead generation:
{
"@context": "https://schema.org",
"@type": "Organization",
"@id": "https://yoursite.com/#organization",
"name": "Your Lead Generation Company",
"url": "https://yoursite.com",
"logo": "https://yoursite.com/logo.png",
"description": "Lead generation company specializing in exclusive insurance leads with TCPA-compliant consent capture",
"foundingDate": "2018-03-15",
"sameAs": [
"https://www.linkedin.com/company/yourcompany",
"https://www.bbb.org/your-business"
],
"address": {
"@type": "PostalAddress",
"streetAddress": "123 Main Street",
"addressLocality": "Austin",
"addressRegion": "TX",
"postalCode": "78701",
"addressCountry": "US"
},
"contactPoint": {
"@type": "ContactPoint",
"contactType": "Sales",
"telephone": "+1-555-123-4567",
"email": "sales@yoursite.com"
}
}The @id property creates a stable identifier other schemas can reference. The sameAs properties link to authoritative external sources where your organization is verified – critical for AI systems disambiguating between similar companies.
Article Schema – Content Authority
Article schema marks up content with metadata about authorship, publication date, and content type. For lead generation content – compliance guides, industry analysis, buyer’s guides – this establishes authority signals AI systems recognize.
Implementation for lead generation articles:
{
"@context": "https://schema.org",
"@type": "Article",
"@id": "https://yoursite.com/tcpa-compliance-guide/#article",
"headline": "TCPA Compliance Guide for Lead Generators 2026",
"description": "Complete guide to TCPA consent requirements, one-to-one consent rules, and compliance documentation for lead generation",
"image": "https://yoursite.com/images/tcpa-guide.jpg",
"datePublished": "2026-01-10T10:00:00Z",
"dateModified": "2026-01-10T10:00:00Z",
"author": {
"@type": "Person",
"@id": "https://yoursite.com/team/author-name/#person",
"name": "Author Name",
"jobTitle": "VP of Compliance",
"url": "https://yoursite.com/team/author-name/"
},
"publisher": {
"@type": "Organization",
"@id": "https://yoursite.com/#organization"
},
"mainEntityOfPage": {
"@type": "WebPage",
"@id": "https://yoursite.com/tcpa-compliance-guide/"
}
}Notice the author includes jobTitle – this signals expertise to AI systems evaluating E-E-A-T. The publisher references your Organization schema via @id, creating a connected data structure.
FAQPage Schema – Question Capture
FAQPage schema is particularly valuable for lead generation because it directly addresses questions users ask AI systems. When someone asks ChatGPT about lead generation practices, FAQ-marked content has higher extraction probability.
Implementation for lead generation FAQs:
{
"@context": "https://schema.org",
"@type": "FAQPage",
"@id": "https://yoursite.com/lead-pricing-faq/#faqpage",
"mainEntity": [
{
"@type": "Question",
"name": "What is the typical CPL for exclusive auto insurance leads?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Exclusive auto insurance leads typically range from $25-45 CPL depending on geographic targeting, credit requirements, and delivery method. Real-time exclusive leads with warm transfer command premium pricing of $60-80."
}
},
{
"@type": "Question",
"name": "What is the difference between exclusive and shared leads?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Exclusive leads are sold to one buyer only. Shared leads are sold to multiple buyers (typically 3-5). Exclusive leads have higher contact rates (typically 60-70% vs 40-50%) and conversion rates, justifying their 2-3x price premium."
}
}
]
}FAQ schema typically delivers 10-30% CTR increases in traditional search. For AI systems, it provides pre-structured question-answer pairs that can be directly extracted into responses. To understand what lead generation actually involves, FAQ schema can address the common questions buyers ask about lead types and pricing.
LocalBusiness Schema – Geographic Leads
For lead generation companies serving specific geographic markets or helping buyers find local leads, LocalBusiness schema establishes geographic authority.
Implementation:
{
"@context": "https://schema.org",
"@type": "LocalBusiness",
"@id": "https://yoursite.com/#localbusiness",
"name": "Your Lead Generation Company",
"image": "https://yoursite.com/logo.png",
"address": {
"@type": "PostalAddress",
"streetAddress": "123 Main Street",
"addressLocality": "Austin",
"addressRegion": "TX",
"postalCode": "78701",
"addressCountry": "US"
},
"geo": {
"@type": "GeoCoordinates",
"latitude": "30.2672",
"longitude": "-97.7431"
},
"areaServed": {
"@type": "State",
"name": "Texas"
},
"priceRange": "$$"
}Service Schema – Offering Clarity
Service schema helps AI systems understand what you offer. For lead generation companies with multiple products (exclusive leads, shared leads, live transfers, aged leads), Service schema clarifies offerings.
{
"@context": "https://schema.org",
"@type": "Service",
"@id": "https://yoursite.com/services/exclusive-leads/#service",
"name": "Exclusive Insurance Leads",
"description": "Real-time exclusive auto insurance leads delivered via API with TrustedForm consent verification",
"provider": {
"@type": "Organization",
"@id": "https://yoursite.com/#organization"
},
"serviceType": "Lead Generation",
"areaServed": {
"@type": "Country",
"name": "United States"
}
}Technical Implementation with JSON-LD
JSON-LD is the format Google recommends and AI systems process most reliably. Understanding implementation patterns prevents common errors.
Why JSON-LD Over Microdata
Three formats exist for schema markup: JSON-LD, Microdata, and RDFa. JSON-LD is the clear standard:
| Aspect | JSON-LD | Microdata | RDFa |
|---|---|---|---|
| Google preference | Recommended | Supported | Supported |
| Maintenance | Separate from HTML | Embedded in HTML | Embedded in HTML |
| Framework compatibility | High | Medium | Low |
| Error risk | Lower | Higher | Higher |
JSON-LD places schema in a separate <script> block, keeping it isolated from HTML structure. Changes to page layout don’t break schema. Microdata embeds markup directly into HTML, making maintenance difficult.
Placement and Structure
JSON-LD schema typically goes in the <head> section of your page:
<head>
<title>Your Page Title</title>
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Your Article Headline",
...
}
</script>
</head>Multiple schema blocks can exist on the same page – Organization schema plus Article schema plus FAQPage schema. Each should be in its own <script type="application/ld+json"> block.
Nesting and Entity Relationships
Complex pages benefit from nested schema that establishes relationships:
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Lead Generation Compliance Guide",
"author": {
"@type": "Person",
"name": "Author Name",
"jobTitle": "VP of Compliance",
"worksFor": {
"@type": "Organization",
"@id": "https://yoursite.com/#organization"
}
},
"publisher": {
"@type": "Organization",
"@id": "https://yoursite.com/#organization"
},
"about": {
"@type": "Thing",
"name": "TCPA Compliance",
"sameAs": "https://en.wikipedia.org/wiki/Telephone_Consumer_Protection_Act_of_1991"
}
}This structure tells AI systems:
- The article is written by a specific person
- That person works for your organization
- The article is about TCPA compliance (linked to authoritative definition)
- Your organization publishes the content
The @id Reference Pattern
The @id property creates stable identifiers that other schemas can reference. This prevents duplication and creates connected data structures:
// Organization schema (homepage)
{
"@type": "Organization",
"@id": "https://yoursite.com/#organization",
"name": "Your Company"
}
// Article schema (content page)
{
"@type": "Article",
"publisher": {
"@type": "Organization",
"@id": "https://yoursite.com/#organization" // References the same entity
}
}When AI systems encounter the Article schema, they can look up the referenced Organization and understand the publishing entity without duplicating information.
Validation and Testing
Implementation without validation is implementation without results. Testing separates successful deployments from invisible markup.
Google Rich Results Test
The primary validation tool: https://search.google.com/test/rich-results
This shows:
- Which structured data Google recognizes
- Which schema types are detected
- Errors preventing rich results eligibility
- Preview of how rich results appear
Test every page before deployment. Test again after any template changes.
Schema Markup Validator
Schema.org’s validator (https://validator.schema.org) provides neutral validation not dependent on any specific search engine. Use as a second opinion before submitting to Google.
Search Console Enhancements Report
After deployment, monitor Google Search Console’s Enhancements section:
- How many pages have valid schema markup
- Items with warnings (valid but suboptimal)
- Items with errors (preventing rich results)
- Specific error messages
This reveals production issues that development testing misses – JavaScript loading delays, CDN caching, template logic errors.
Common Implementation Mistakes
The gap between understanding schema and implementing it correctly is where most organizations stumble.
Mistake 1: Syntax Errors in JSON
JSON is unforgiving. A missing comma breaks everything. A trailing comma breaks everything. A mismatched bracket breaks everything.
Correct:
{
"name": "Your Company",
"address": "123 Main Street"
}Incorrect (trailing comma):
{
"name": "Your Company",
"address": "123 Main Street",
}The difference is invisible to humans but fatal to machines. Use a JSON validator before deploying.
Mistake 2: Missing Required Properties
Every schema type has required properties. Article schema requires headline, author, and datePublished. Product schema requires name and offers. Missing required properties means schema gets processed but doesn’t qualify for rich results.
Check Schema.org documentation for required properties before implementing.
Mistake 3: Schema Doesn’t Match Visible Content
Critical rule: never markup content that isn’t visible on the page. If you use FAQ schema, those questions and answers must appear on the page. If you markup pricing, that price must match what users see.
AI systems cross-reference schema with visible content. Discrepancies are interpreted as unreliability. Your credibility takes a hit.
Mistake 4: Multiple Competing Schemas
Some organizations implement the same schema type twice using different methods. Some tools auto-inject schema that conflicts with developer-implemented markup. When Google encounters multiple conflicting implementations, it often ignores all of them.
Audit pages to ensure only one schema implementation per entity type exists.
Mistake 5: Heavy Schema Impacting Performance
Large JSON-LD implementations add overhead. They increase HTML payload and require parsing. On mobile connections, this slows page loading.
Solution: prioritize core schemas for immediate rendering. Secondary schemas can load asynchronously.
Progressive Implementation Roadmap
Rather than attempting full implementation immediately, follow staged deployment:
Week 1-2: Foundation
- Implement Organization schema on homepage
- Validate with Rich Results Test
- Submit to Search Console
- Establish baseline in Enhancements Report
Week 3-4: Core Content
- Implement Article schema on top 10 traffic pages
- Add author attribution with Person schema
- Test each article individually
- Monitor Search Console for validation
Week 5-6: Specialized Schemas
- Identify high-value pages for FAQPage schema
- Implement Service schema for product pages
- Add one schema type at a time
- Test and validate before moving to next
Week 7-8: Scaling
- Automate schema for similar page types
- Create templates for consistent markup
- Document implementation patterns
- Train team on maintenance
Ongoing: Monitoring
- Review Search Console weekly for errors
- Update dateModified on revised content
- Monitor AI citation frequency monthly
- Audit quarterly for schema validity
Lead Generation-Specific Implementation
Schema implementation for lead generation has specific considerations beyond general best practices.
Compliance Content Markup
Lead generation compliance content benefits from comprehensive schema because:
- Questions are specific and frequent
- Information changes with regulations
- Authoritative sources are limited
- AI systems prioritize accuracy for YMYL topics
Recommended schema combination for compliance guides:
- Article schema (establishes content type and authorship)
- FAQPage schema (captures common questions)
- Person schema for compliance experts
- Organization schema for publishing entity
Service and Product Differentiation
Lead generation offerings (exclusive leads, shared leads, live transfers) should have distinct schema:
{
"@context": "https://schema.org",
"@type": "Service",
"name": "Exclusive Auto Insurance Leads",
"description": "Real-time exclusive auto insurance leads with TrustedForm consent verification",
"offers": {
"@type": "Offer",
"priceSpecification": {
"@type": "UnitPriceSpecification",
"price": "35.00",
"priceCurrency": "USD",
"unitText": "per lead"
}
}
}Author Expertise for E-E-A-T
Author schema should emphasize lead generation expertise:
{
"@type": "Person",
"@id": "https://yoursite.com/team/expert-name/#person",
"name": "Expert Name",
"jobTitle": "VP of Lead Operations",
"description": "12-year lead generation veteran specializing in insurance verticals with experience managing 2M+ annual lead volume",
"knowsAbout": [
"Lead Generation",
"TCPA Compliance",
"Performance Marketing",
"Insurance Marketing"
],
"sameAs": [
"https://linkedin.com/in/expertprofile"
]
}The knowsAbout property explicitly signals expertise areas to AI systems.
Key Takeaways
-
Pages with schema markup are 3x more likely to appear in AI Overviews. This is the primary business case for schema implementation in 2026.
-
Language models achieve 300% higher accuracy with structured data. AI systems prefer content they can verify through schema markup.
-
Less than 30% of websites implement schema effectively. This represents a significant competitive advantage window.
-
Organization schema is the foundation. Every implementation starts here, establishing identity that other schemas reference.
-
JSON-LD is the standard format. Google recommends it, and it’s easier to maintain than Microdata or RDFa.
-
82.5% of AI Overview citations come from pages with structured data. Schema isn’t optional for AI visibility.
-
Validation is non-negotiable. Use Rich Results Test, Schema.org Validator, and Search Console Enhancements Report.
-
Schema must match visible content exactly. Discrepancies damage credibility with AI systems.
-
Progressive implementation outperforms all-at-once deployment. Start with Organization and Article, then expand.
-
Author schema with expertise signals strengthens E-E-A-T. Include jobTitle, description, and knowsAbout properties.
Frequently Asked Questions
What is schema markup and why does it matter for lead generation?
Schema markup is structured data embedded in page code that helps search engines and AI systems understand content. For lead generation, schema matters because AI systems use it to verify information before citing sources. Pages with comprehensive schema are 3x more likely to appear in AI Overviews, and 82.5% of AI citations come from pages with structured data.
Which schema types should lead generation companies implement first?
Start with Organization schema on your homepage (establishing company identity), then add Article schema to your core content pages (compliance guides, industry analysis). Next, implement FAQPage schema for content addressing common questions. Service schema for your offerings and Person schema for author credentials complete the foundation.
Is schema markup a direct ranking factor?
Google hasn’t confirmed schema as a direct ranking factor. However, schema indirectly impacts rankings through improved click-through rates, better content understanding, and more frequent rich result appearances. For AI visibility, the connection is more direct – AI systems explicitly prefer structured data for verification.
What’s the difference between JSON-LD and Microdata?
JSON-LD places schema in a separate script block, keeping it isolated from HTML. Microdata embeds markup directly into HTML elements. JSON-LD is Google’s recommended format because it’s easier to maintain, less error-prone, and compatible with modern development frameworks. Choose JSON-LD for new implementations.
How do I validate schema markup before deployment?
Use Google’s Rich Results Test to verify Google recognizes your schema and check for errors. Use Schema.org Validator as a second opinion. After deployment, monitor Google Search Console’s Enhancements Report for production issues. Test every page before deployment and after any template changes.
Can incorrect schema markup hurt my site?
Poorly implemented schema can cause problems – syntax errors, missing required properties, and conflicting implementations can confuse search engines. However, invalid schema is usually ignored rather than penalized. The risk is missing benefits, not active harm. Always validate before deploying.
How often should schema markup be updated?
Update schema whenever underlying content changes. Always update dateModified when revising articles. Update pricing and availability in real-time if possible. Review aggregate ratings and review counts regularly. AI systems expect schema to reflect current reality.
What happens if schema doesn’t match visible page content?
AI systems cross-reference schema with visible content. When they find discrepancies, they deprioritize your content and interpret the mismatch as unreliability. Never markup content that isn’t visible on the page. If your FAQ schema contains questions, those questions must appear on the page.
How does schema markup affect AI citation probability?
Schema markup increases citation probability by enabling AI systems to verify information confidently. When an AI generates a response, it needs to verify claims before presenting them. Structured data provides clear signals about content type, authorship, publication date, and expertise – all factors AI systems use to determine citation-worthiness.
Can I implement schema through plugins or should I code it manually?
Both approaches work. Plugins (like Yoast SEO or Rank Math for WordPress) provide templated schema implementation suitable for standard content types. Manual implementation offers more control for complex or specialized schemas. Many organizations use plugins for basic schemas and manual implementation for specialized markup.
How long does it take to see results from schema implementation?
Initial results can appear within weeks as search engines process new markup. Significant visibility improvements – particularly in AI Overviews – typically take 4-8 weeks to materialize. Establish a baseline before implementing, then compare metrics after at least 8 weeks.
Should I implement schema on every page?
Organization schema should appear on every page. Article schema should appear on content pages. FAQ schema should appear only on pages with actual FAQ content. Service schema should appear on service/product pages. Don’t implement schema types that don’t match page content.
How does schema relate to LLMO and E-E-A-T?
Schema markup supports both LLMO (Large Language Model Optimization) and E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness). For LLMO, schema helps AI systems understand and cite your content. For E-E-A-T, author schema with credentials and Organization schema with business information provide trust signals AI systems recognize. For complementary optimization approaches, explore our guides on GEO strategies and organic SEO for lead generation.
What’s the @id property and why does it matter?
The @id property creates a stable identifier that other schemas can reference. Your Organization schema might have @id": "https://yoursite.com/#organization". Article schemas can then reference this same entity as their publisher without duplicating information. This creates connected data structures that AI systems understand more effectively.
How do I measure schema markup ROI?
Short-term (4-8 weeks): track rich result appearances and CTR changes. Medium-term (2-3 months): monitor traffic changes and AI Overview appearances through manual searches. Long-term (6+ months): track citation frequency in AI responses, entity recognition improvements, and organic traffic stability. Connect schema metrics to business outcomes where possible.