Technical architecture decisions, data ingestion patterns, and vendor pricing for clean room implementation in lead generation operations.
Most articles on data clean rooms explain what they do. Publishers match audiences without sharing data. Buyers verify lead quality without exposing customer lists. Everyone understands the value proposition by now.
What’s missing is the implementation layer. Which platform runs on what infrastructure. How data actually enters the clean room. What hashing standards apply. What queries cost. Where encryption happens and who controls the keys.
These details determine whether a clean room implementation delivers results in 8 weeks or sits idle after 6 months of failed data engineering. They also determine whether your $50,000 annual platform estimate becomes $300,000 once you account for identity resolution licensing, compute overages, and partner onboarding fees.
This guide covers the technical architecture choices, data ingestion patterns, identity resolution mechanics, and pricing structures across the five platforms that dominate lead generation clean room implementations.
The Two Architectural Models
Before comparing vendors, understand the fundamental split in clean room architecture. Every platform falls into one of two models, and the choice has significant technical and compliance implications.
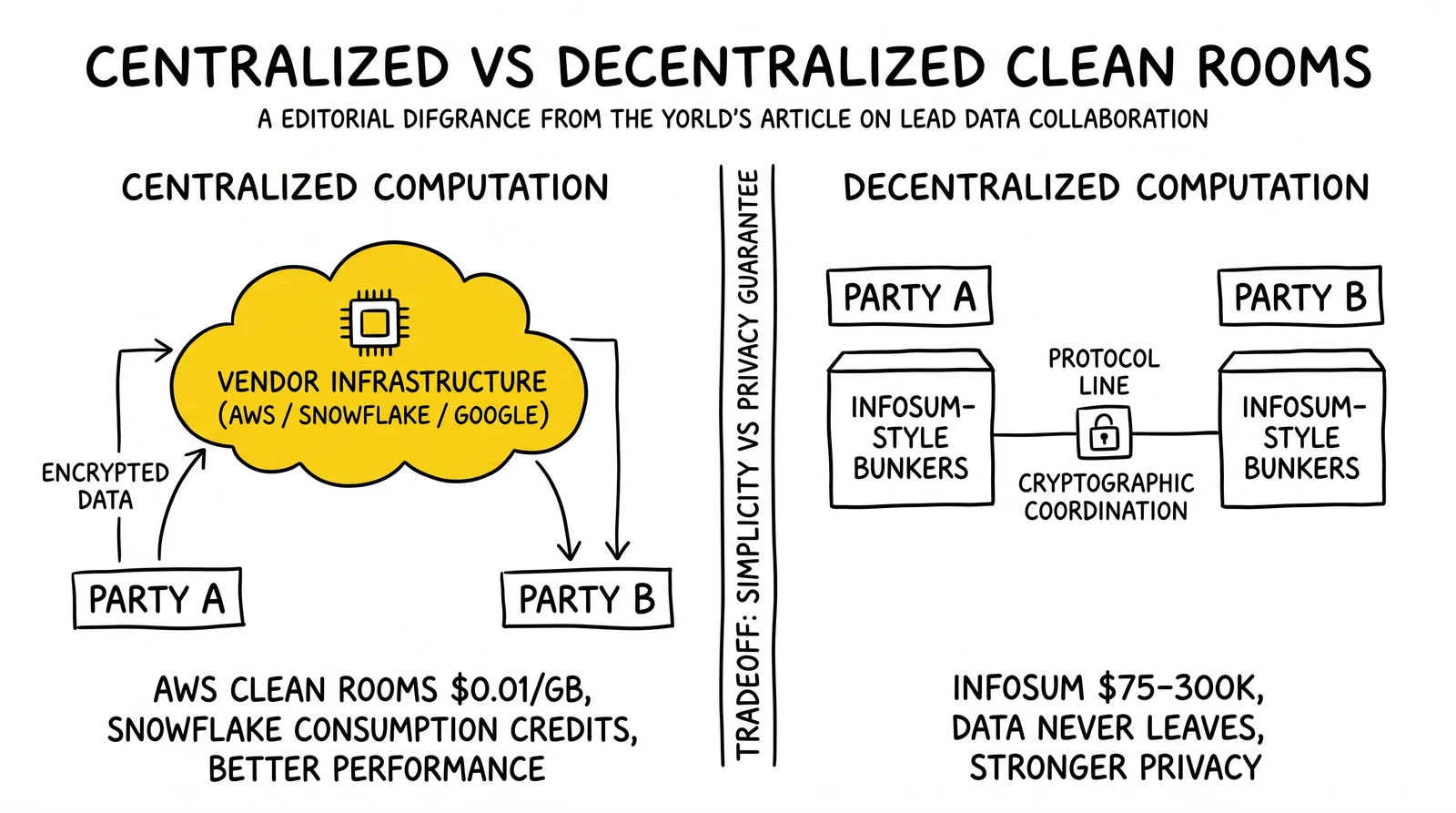
Centralized Computation Model
In the centralized model, each party contributes encrypted data to a shared cloud environment. The platform vendor controls the computational infrastructure. Data is encrypted before upload, but it does physically reside in a third-party environment – even if in a form that cannot be read without both parties’ keys.
AWS Clean Rooms and Google Ads Data Hub operate this way. Your data enters their environment. Computation happens on their infrastructure. Outputs return to you. The vendor’s security controls, not yours, protect the data during analysis.
This model delivers better performance and simpler implementation. SQL queries run on vendor-managed compute with familiar tooling. Integration with the broader cloud ecosystem (S3, Redshift, BigQuery) is straightforward. The tradeoff is that your data, even encrypted, exists outside your infrastructure boundary.
Decentralized Computation Model
In the decentralized model, data never leaves organizational control. Each party maintains their data in their own infrastructure. The clean room platform coordinates computation without centralizing data – running distributed cryptographic protocols across the participating parties’ environments.
InfoSum’s bunker architecture and some Snowflake implementations approach this model. Habu can facilitate either model depending on underlying platform configuration.
The decentralized model provides stronger privacy guarantees and may satisfy legal requirements that prohibit contributing data to third-party environments. The tradeoffs are higher implementation complexity, lower computational performance, and dependency on reliable network connectivity between participating environments.
Most lead generation operations can work with the centralized model given appropriate vendor security certifications. The decentralized model becomes relevant when dealing with regulated data categories or organizational policies that prohibit cloud data contribution.
AWS Clean Rooms: Technical Specifications
AWS Clean Rooms launched to general availability in March 2023. It operates within the AWS ecosystem, enabling collaboration between organizations with data in S3 without that data leaving AWS infrastructure.
How It Works
Each participating organization creates a collaboration in AWS Clean Rooms. The collaboration defines which AWS accounts participate, what data sources each contributes, and what analysis rules govern query execution.
Data remains in each party’s own S3 buckets or Glue catalog. AWS Clean Rooms creates secured views of contributed data rather than copying data to a shared location. Analysis runs within AWS’s secure multi-party computation environment.
Analysis rules are the core governance mechanism. Four rule types exist:
Aggregation rules permit queries that return aggregate results only. Minimum row counts (configurable from 2 to 100,000) prevent individual identification. Results must use aggregation functions: COUNT, SUM, AVG, STDDEV, VARIANCE. No individual record extraction.
List rules allow returning lists of records within defined constraints. The contributing party configures which columns can be returned and whether differential privacy noise is applied.
Custom analysis rules require query approval against pre-approved templates written by the data owner. Analysts submit queries, which execute only if they match approved patterns. This is the most restrictive mode, appropriate for sensitive data categories.
Differential privacy rules (added 2024) apply mathematical privacy guarantees to outputs, ensuring individual records cannot be inferred from aggregate results.
Data Ingestion
Contributing data to AWS Clean Rooms requires data in S3 in supported formats: Parquet, CSV, or ORC. Schema registration occurs through AWS Glue Data Catalog. Each table must be registered with column-level metadata and privacy classifications.
Personal identifiers require hashing before ingestion. AWS recommends SHA-256 for email and phone hashing, with consistent salting across parties to enable matching. The platform does not hash on your behalf – hashing is a pre-ingestion step in your data pipeline.
Typical pre-ingestion pipeline:
Raw CRM export → Normalize identifiers (lowercase, strip formatting)
→ Hash (SHA-256) → Schema validation → S3 upload → Glue catalog registrationData normalization before hashing is critical. “john.doe@example.com” and “John.Doe@Example.com” hash to different values. A consistent normalization step – lowercase, trim whitespace, strip plus-addressing – prevents match failures from formatting inconsistency.
AWS Clean Rooms ML
AWS added machine learning capabilities to Clean Rooms in 2024, enabling collaborative model training without data movement. Contributing parties can train lookalike models on combined datasets. The ML service coordinates training across parties without either party’s data leaving their account.
This capability matters for lead generators building audience extension models from combined publisher and buyer signal sets. Model training on combined data historically required centralizing both datasets – creating the data accumulation problem clean rooms are designed to avoid.
Identity Resolution Gap
AWS Clean Rooms does not include built-in identity resolution. If both parties hashed email addresses using identical normalization, deterministic matching works. If one party has email addresses and the other has only phone numbers, AWS Clean Rooms cannot bridge the gap natively.
Organizations needing cross-identifier matching must integrate a third-party identity graph. AWS has partnerships with LiveRamp, TransUnion, and Acxiom for identity resolution within Clean Rooms, but these are separately licensed services that add to implementation cost.
Pricing
AWS Clean Rooms charges $0.01 per GB of data analyzed per query. Storage remains at standard S3 pricing (~$23/TB/month). No platform licensing fee beyond consumption.
For context: a query analyzing 100GB of lead data costs $1.00. Running 1,000 queries monthly against a 100GB dataset runs $1,000/month in query costs, plus storage and data egress fees. Organizations processing billions of records on frequent refresh cycles should model compute costs carefully before assuming Clean Rooms is the low-cost option.
The Clean Rooms ML service carries additional pricing: $0.01 per 1,000 audience segments scored, plus standard SageMaker rates for model training compute.
Ideal for: AWS-native organizations, technical teams comfortable with S3 and Glue, use cases requiring machine learning collaboration, scenarios where cryptographic privacy guarantees matter more than identity resolution capability.
Snowflake Data Clean Rooms: Technical Specifications
Snowflake’s clean room implementation differs fundamentally from AWS’s. Rather than a separate service, Snowflake Clean Rooms are built on Snowflake’s native data sharing and secure view infrastructure. This means any organization with a Snowflake account can participate – the clean room is, conceptually, a set of access controls on shared data rather than a separate platform.
Architecture
Snowflake Clean Rooms use a provider-consumer model from Snowflake’s Data Sharing framework:
The provider creates a clean room object within their Snowflake account. They define what data tables are accessible, what analysis templates are permitted, and what privacy controls apply. The clean room is published to Snowflake’s Data Marketplace or shared directly to specific consumer accounts.
The consumer installs the clean room into their own Snowflake account. They can execute permitted queries against the provider’s data from within their own account – no data physically transfers. Snowflake’s infrastructure coordinates the cross-account computation.
This model scales well for multi-party scenarios. A lead network operating a Snowflake Clean Room can onboard 20 publisher partners and 15 buyer partners without architectural changes – each runs queries in their own account against the shared clean room.
Query Templates and Jinja2
Snowflake Clean Rooms use Jinja2-templated SQL for query governance. The provider defines templates that consumers execute with their own parameter values substituted. This prevents arbitrary query construction while allowing flexible analysis within approved patterns.
Example: a publisher creates a template that computes conversion rates by traffic source, with buyer-contributed conversion data substituted at query time. The buyer cannot modify the query structure – only supply their conversion table identifier. The template enforces the privacy controls.
This approach is more flexible than AWS’s fixed rule types but requires more configuration. Writing effective Jinja2 templates for complex clean room analyses requires SQL expertise and understanding of Snowflake’s Snowpark framework.
Data Ingestion
Snowflake Clean Rooms require data to be in Snowflake tables – either loaded directly or federated from external storage. Organizations without existing Snowflake infrastructure must either migrate data to Snowflake or establish a pipeline from their current data store.
If partners are already on Snowflake, data sharing is near-instantaneous – no ETL, no file transfer. If partners need data loaded, Snowflake’s ingestion options include Snowpipe for streaming, COPY command for batch, and connectors for common sources (Salesforce, HubSpot, S3).
Identifier hashing for Snowflake Clean Rooms can occur either before ingestion or within Snowflake using user-defined functions. In-database hashing through Snowflake’s SHA2 function is convenient but means raw PII enters Snowflake before being hashed – a compliance consideration for some organizations.
Privacy Controls
Snowflake Clean Rooms support differential privacy through an integration with Harvard’s OpenDP library. Operators define privacy budgets (epsilon values) that constrain how much information any sequence of queries can extract. As queries consume privacy budget, the system adds more noise to subsequent results.
Aggregation minimums are configurable per column and per query template. The provider sets these in the template definition – consumers cannot override them.
One gap: Snowflake Clean Rooms do not automatically enforce privacy controls on all queries. The controls are embedded in templates, but templates must be correctly authored. A poorly designed template can expose more data than intended. Governance review of templates before deployment is essential.
Identity Resolution
Snowflake has a native partnership with LiveRamp for identity resolution within Clean Rooms. Organizations using this integration can match across email, phone, postal address, and LiveRamp’s RampID – enabling cross-device matching without contributing device identifier data directly.
The integration requires a LiveRamp contract in addition to Snowflake. Match rate improvement over deterministic-only matching typically ranges from 15-25%, depending on how fragmented the identity data is.
Pricing
Snowflake Clean Rooms use Snowflake’s credit-based consumption model. Credits cost approximately $2-4 per credit depending on region and contract tier. Compute warehouse sizes determine credit consumption rate (X-Small: 1 credit/hour through 6X-Large: 512 credits/hour).
Clean room queries run on virtual warehouses sized to the analysis complexity. A simple overlap count against a 10M-record dataset might run in 2 minutes on a Medium warehouse (4 credits/hour), consuming 0.13 credits at $0.26-0.52. A complex attribution analysis might run 30 minutes on a Large warehouse, consuming 8 credits at $16-32.
Storage costs approximately $23-40/TB/month depending on region and tier. Organizations already on Snowflake with a data infrastructure investment may find Clean Rooms adds minimal marginal cost.
Ideal for: Organizations already on Snowflake, data teams comfortable with SQL, scenarios requiring multi-party collaboration at scale, use cases needing flexible query templates rather than fixed rule types.
LiveRamp Safe Haven: Technical Specifications
LiveRamp Safe Haven occupies a different market position than the cloud-native options. It is purpose-built for enterprise data collaboration with identity resolution as the core differentiator, not an add-on. The platform is expensive and complex to implement – but provides capabilities the cloud-native platforms cannot match.
RampID: The Identity Foundation
Safe Haven’s primary advantage is RampID, LiveRamp’s persistent cross-device identity graph. RampID resolves identities across email, phone, postal address, mobile device identifiers, and connected TV identifiers – creating a unified profile that matches across the fragmented identity signals that lead generation data sources produce.
When a lead file contains an email address but the buyer’s customer database has phone numbers and a mailing address, RampID bridges the gap. The practical match rate improvement over deterministic-only matching is typically 20-35% for lead generation use cases with fragmented input data.
RampID is not a cookie or a device fingerprint. It persists across device changes, email updates, and browser resets through ongoing resolution from offline anchor data. For lead generation operations where lead data may be weeks or months old, RampID’s persistence matters – deterministic match rates degrade as identifiers go stale.
Data Ingestion
Safe Haven ingestion begins with data onboarding, which LiveRamp calls “data activation.” Organizations send lead files to LiveRamp’s secure onboarding environment. LiveRamp’s resolution engine processes the files, resolving personal identifiers against the RampID graph and returning tokenized records for use in Safe Haven.
Supported input formats include CSV, fixed-width, and Parquet. Files transfer via SFTP with PGP encryption, through LiveRamp’s secure portal, or via API. LiveRamp provides column mapping templates to standardize field naming across partners.
Onboarding latency ranges from 24-72 hours for initial files, declining to 4-8 hours for subsequent refreshes as resolution improves. High-volume partners can negotiate near-real-time onboarding through API integration.
Collaboration Patterns
Safe Haven supports three collaboration modes:
Trusted partner collaboration provides direct analysis between two pre-approved partners. Both parties must be Safe Haven customers. Analysis runs on LiveRamp’s infrastructure with configurable privacy controls.
Marketplace collaboration connects publishers and buyers through LiveRamp’s network of Safe Haven participants. If a publisher is already in the network, buyers can connect without requiring the publisher to separately contract for Safe Haven – reducing friction for buyer-initiated partnerships.
Programmatic activation extends beyond analytics. Clean room insights – matched segments, lookalike audiences – can be activated directly on advertising platforms including Google, Facebook, The Trade Desk, and 200+ other destinations. This activation pathway is Safe Haven’s most distinctive capability relative to cloud-native platforms.
For lead generation, programmatic activation enables this workflow: identify the 34% of a publisher’s leads that match your high-LTV customer profile → build a lookalike audience from those characteristics → activate that audience directly on Facebook or Google for top-of-funnel acquisition. The entire workflow stays within Safe Haven without raw data exposure.
Privacy Controls
Safe Haven enforces aggregation minimums across all outputs (minimum 25 records, configurable up to 100). Differential privacy is available as an optional control. All computation occurs on LiveRamp’s infrastructure, which is SOC 2 Type II certified.
LiveRamp audits all queries and can identify patterns suggesting re-identification attempts. Unusual query sequences – many small queries that could be combined to infer individual records – trigger review.
Pricing
Safe Haven pricing is enterprise licensed, not consumption-based. Annual contracts start at approximately $100,000 and scale based on data volume processed, number of partner connections, and feature tier.
Organizations that primarily need identity resolution to improve Snowflake or AWS Clean Room match rates can license LiveRamp’s identity resolution service separately (RampID tokenization only) without the full Safe Haven platform. This hybrid approach costs less than full Safe Haven implementation while capturing the match rate benefit.
Ideal for: Enterprise lead buyers with $1M+ annual lead spend, large publishers requiring cross-device audience measurement, scenarios where programmatic activation of clean room audiences is required, operations where identity resolution across fragmented touchpoints determines match rate viability.
InfoSum: The Decentralized Architecture
InfoSum’s architectural position is distinctive: data never leaves organizational infrastructure, even in encrypted form. This is a genuine technical differentiator from the other platforms, not a marketing claim.
Bunker Architecture
InfoSum calls each organization’s data infrastructure a “bunker.” Data in the bunker is indexed and queryable through InfoSum’s API, but the data itself never transfers to InfoSum’s servers or partner environments. When two organizations collaborate, InfoSum’s platform sends computation instructions to each bunker and aggregates the results – never the data.
This distributed computation model has technical constraints. Latency is higher than centralized models because each query round-trips to multiple locations. Complex queries require multiple rounds of computation. Very large datasets may time out under complex analytical workloads.
The compliance advantage compensates for these performance constraints in specific use cases. Organizations under legal requirements that prohibit contributing data to any third-party infrastructure – certain financial services firms, healthcare organizations – can participate in clean room collaboration through InfoSum when other platforms are disqualified.
Data Ingestion
InfoSum ingestion requires deploying an InfoSum agent within your infrastructure. The agent connects to your data store (database, data warehouse, S3-compatible storage) and creates an indexed representation for InfoSum’s computation layer.
Data never leaves your environment. The agent serves query results to InfoSum’s coordination layer. Partners receive aggregated outputs, not source data.
Supported data sources include Snowflake, Databricks, BigQuery, Redshift, PostgreSQL, and S3/CSV flat files through a connector framework. Connector availability varies – confirm your specific data source is supported before implementation. Organizations with unusual database configurations may require custom connector development.
Initial setup typically requires 2-4 weeks of infrastructure configuration, primarily deploying the agent securely within your environment and establishing connectivity. Ongoing data refresh is automated once the agent is configured.
Identity Resolution
InfoSum has partnerships with identity resolution providers including Experian and TransUnion for augmented matching. The resolution occurs within each party’s bunker environment – the identity provider supplies lookup tables that the bunker uses locally rather than sending data to the provider.
This keeps resolution within the decentralized model, but requires identity lookup tables to be maintained within each participating organization’s environment. Setup complexity is higher than the centralized alternative.
Pricing
InfoSum pricing is based on number of bunkers (data connections), partner connections, and query volume/complexity. Enterprise implementations typically run $75,000-300,000 annually. Smaller implementations for specific use cases may be structured at lower costs.
InfoSum does not publish pricing publicly. Enterprise contracts are negotiated based on use case scope.
Ideal for: Privacy-conscious organizations under legal requirements prohibiting third-party data contribution, publishers requiring strict data sovereignty, financial services and healthcare organizations with data residency constraints.
Habu: The Interoperability Layer
Habu occupies a meta-layer position. Rather than operating its own clean room infrastructure, Habu connects existing clean room platforms – enabling collaboration between organizations on different underlying platforms.
How Habu Works
Habu integrates with Snowflake, AWS Clean Rooms, Google Ads Data Hub, Databricks, and proprietary clean room implementations. When two organizations want to collaborate but use different underlying platforms, Habu translates between them.
A publisher on Snowflake can collaborate with a buyer on AWS Clean Rooms through Habu without either party migrating their data infrastructure. Habu handles the cross-platform query translation and result aggregation.
This matters practically because partner ecosystem diversity is high. In a network of 50 publishers and 30 buyers, platform standardization is unlikely. Habu’s interoperability layer enables collaboration at network scale without requiring platform homogenization.
Technical Implementation
Habu connects to each party’s existing clean room environment through native integrations. The integration requires API credentials for the underlying platform, plus Habu-specific configuration for permitted collaboration patterns.
For Snowflake: Habu connects via service account with appropriate Clean Rooms permissions. For AWS: Habu uses an IAM role with Clean Rooms collaboration access. The party does not need to change their existing data infrastructure – Habu orchestrates across it.
Habu provides a marketing-accessible interface for query execution. Non-technical users can run pre-approved analysis templates through Habu’s UI without writing SQL or accessing the underlying platform console. This lowers the operational barrier for ongoing clean room use compared to direct platform access.
Activation Integrations
Habu includes pre-built activation integrations with advertising platforms – Google, Meta, The Trade Desk, Amazon DSP. Clean room audience outputs can route directly to these platforms for campaign activation without manual export steps.
This activation pathway overlaps with LiveRamp Safe Haven’s capability but operates cross-platform rather than requiring LiveRamp infrastructure for both parties.
Pricing
Habu uses subscription pricing plus per-partner connection fees. Typical implementations run $50,000-200,000 annually depending on the size of the partner network. Organizations with large partner networks (20+ partners) may negotiate volume pricing.
Ideal for: Lead networks facilitating collaboration across diverse partner technology stacks, organizations with existing clean room implementations seeking to extend collaboration to partners on different platforms, marketing teams needing accessible UI without deep technical resources.
Identity Resolution: The Matching Foundation
Regardless of platform, clean room effectiveness depends on match rates. Match rates depend on identity resolution – the ability to connect records from different organizations that represent the same individual.
Deterministic Matching
Deterministic matching requires identical identifiers on both sides. Hashed email addresses are the most reliable deterministic identifier for lead generation – email addresses change less frequently than phone numbers and are captured more consistently than postal addresses.
For deterministic matching to work, hashing must be consistent. The standard approach uses SHA-256 on normalized identifiers:
Input: "John.Doe+marketing@Example.com"
Normalize: "john.doe+marketing@example.com"
Strip plus-addressing (optional): "john.doe@example.com"
Hash: SHA-256 → "3d4f2..."The critical decision is whether to strip plus-addressing and whether to lowercase before hashing. Both parties must make identical decisions. Document your normalization approach and share it with every partner before implementation.
Phone number normalization is similarly critical. E.164 format (+15555551234) is the standard, but compliance varies. Strip extensions, country codes, and formatting characters before hashing. A phone number normalized differently between two parties generates different hashes and misses the match.
Probabilistic Matching
When deterministic identifiers are unavailable or don’t match, probabilistic matching combines multiple partial signals to infer likely matches:
- First name initial + last name + postal code
- Device type + geographic area + behavioral patterns
- Partial email domain + demographics + estimated age range
Probabilistic matching achieves 30-50% of deterministic match rates and introduces false positive risk – records matched that don’t actually represent the same individual. For suppression use cases, false positives are acceptable (suppressing a non-match wastes less money than marketing to an existing customer). For attribution use cases, false positives create measurement error.
Most enterprise clean room platforms support probabilistic matching through integration with identity graph providers. The identity graph vendor (LiveRamp, Experian, TransUnion) maintains cross-identifier resolution tables that extend matching beyond what either party’s first-party data alone supports.
Match Rate Benchmarks by Use Case
| Use Case | Deterministic Only | With Identity Graph |
|---|---|---|
| Publisher-Buyer Email Match | 50-65% | 65-80% |
| Buyer Customer vs. Lead Pool | 45-60% | 60-75% |
| Cross-Device Attribution | 20-35% | 40-60% |
| Suppression Matching | 55-70% | 70-85% |
These ranges reflect industry benchmarks across lead generation verticals. Match rates vary significantly based on data age (fresh leads match better than aged), data completeness (partial records miss more), and identifier coverage (single identifier vs. multiple backup identifiers).
Data Pipeline Architecture for Clean Room Ingestion
Building reliable clean room ingestion requires treating the clean room as a data destination like any other – with schema management, monitoring, and refresh scheduling.
Schema Design
Clean room schemas should be narrow: only the columns required for approved analyses. Contributing wide schemas with dozens of columns creates two problems. Privacy controls must account for every column. Query governance becomes complex when analysts have access to many attributes.
Design schemas specifically for each clean room collaboration:
Lead quality verification schema (publisher side):
- lead_id_hash (SHA-256 of normalized email)
- lead_timestamp (unix epoch)
- traffic_source (enum)
- form_id (anonymized)
- consent_timestamp (unix epoch)
Conversion schema (buyer side):
- lead_id_hash (SHA-256 of normalized email – must match publisher hashing)
- conversion_timestamp (unix epoch, null if not converted)
- conversion_value (numeric, null if not converted)
No names, no addresses, no raw contact information in either schema. The hash provides the join key. Every other column is an event attribute.
Refresh Scheduling
Clean room analyses age quickly. Lead data from 30 days ago produces different match rates and conversion insights than current data. Design refresh schedules aligned with business questions:
- Suppression matching: refresh daily or in near-real-time for active campaigns
- Attribution analysis: refresh weekly to capture conversion lag
- Audience overlap for partnership evaluation: refresh monthly or on-demand
Automated refresh pipelines should include data quality checks before ingestion. A pipeline that silently delivers 50% fewer records than expected (due to an upstream schema change) produces clean room outputs that appear valid but represent only half the data – a dangerous misrepresentation.
Error Handling
Clean room ingestion failures are silent unless monitored. Build monitoring for:
- Record count validation against expected ranges
- Hash format validation (length, character set)
- Schema consistency checks
- Ingestion latency alerts
- Match rate monitoring (sudden drops indicate upstream data quality issues)
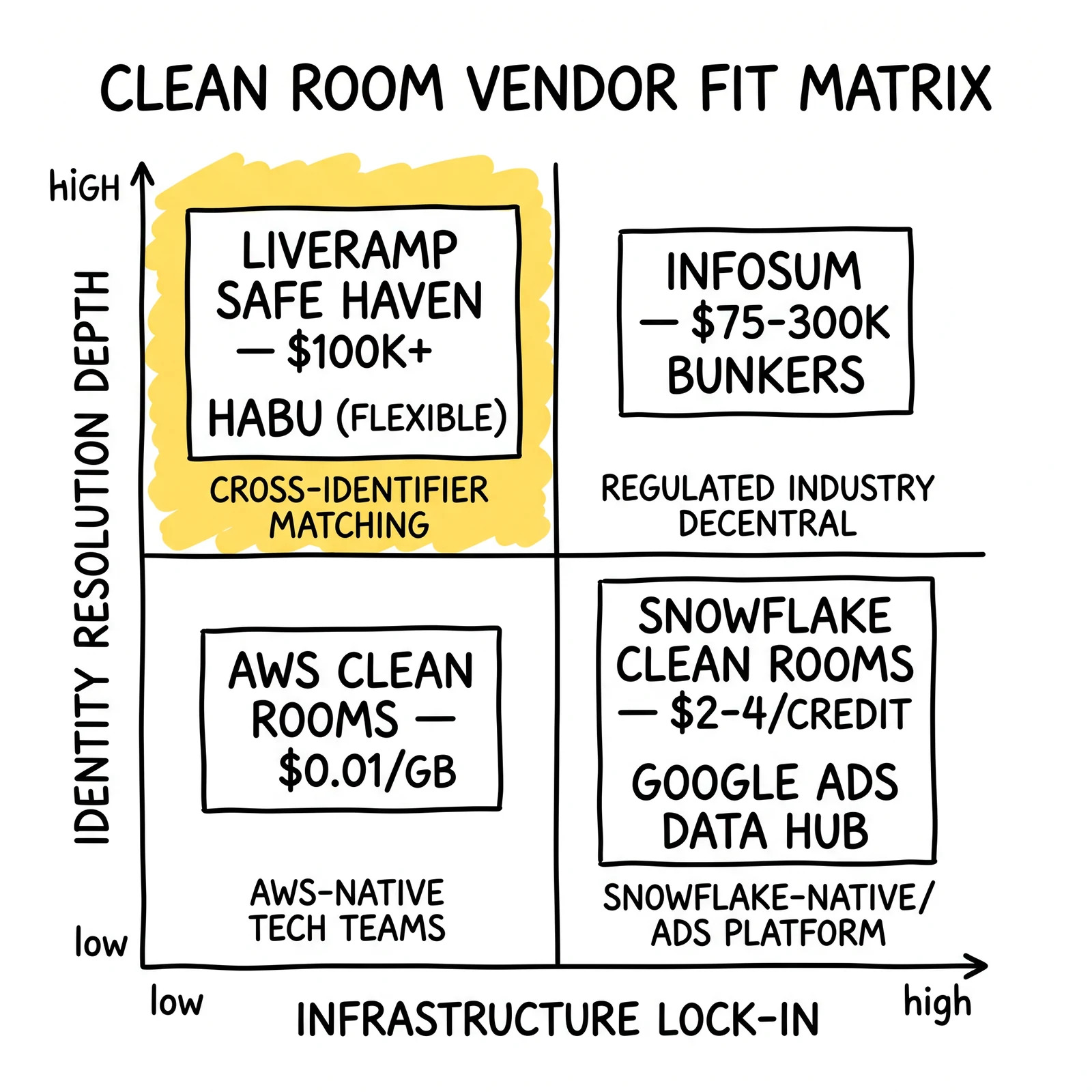
Vendor Selection Decision Matrix
| Factor | AWS Clean Rooms | Snowflake | LiveRamp Safe Haven | InfoSum | Habu |
|---|---|---|---|---|---|
| Data Residency | AWS-controlled | Snowflake-controlled | LiveRamp-controlled | Your infrastructure | Varies by underlying |
| Identity Resolution | Requires third-party | Requires LiveRamp add-on | Built-in (RampID) | Experian/TransUnion partners | Depends on underlying |
| Pricing Model | Consumption ($0.01/GB) | Credit consumption ($2-4/credit) | Enterprise license ($100K+) | Enterprise license ($75K-300K) | Subscription + per-partner |
| SQL Interface | Yes (Analysis Rules) | Yes (Jinja2 SQL) | No (UI + API) | No (API) | Yes (simplified) |
| Multi-cloud | AWS only | Snowflake-native | Platform-agnostic | Platform-agnostic | Multi-platform |
| Activation | No | No | Yes (200+ destinations) | No | Yes (major DSPs) |
| Implementation Time | 4-8 weeks | 6-12 weeks | 12-20 weeks | 8-16 weeks | 4-8 weeks |
| Technical Complexity | High | High | Medium | High | Low-Medium |
Decision Logic
Start with infrastructure alignment. An AWS shop should evaluate AWS Clean Rooms seriously before considering alternatives. Snowflake users should prototype with Snowflake Clean Rooms before adding platform cost. The migration overhead of introducing a new infrastructure platform rarely justifies the switch unless a specific capability gap (identity resolution, activation) requires it.
If match rate is the primary constraint – your lead data and partner customer data don’t share enough clean email addresses – LiveRamp Safe Haven’s RampID becomes the differentiated option despite cost. The economics work when improved match rates translate to measurable business decisions: accurate attribution, reliable suppression, verified publisher performance.
If partner ecosystem diversity is the constraint – collaborating with 20+ partners on different infrastructure stacks – Habu’s interoperability reduces coordination overhead more than any single-platform optimization.
If data residency is a legal requirement – data cannot leave organizational infrastructure – InfoSum is the only option that satisfies the constraint without legal workarounds.
Frequently Asked Questions
What is the minimum data volume that makes clean room implementation worth the cost?
Clean rooms provide most value when match pools contain at least 50,000 records on each side. Below this threshold, aggregation minimums (typically 25-50 records) consume enough of the result set to limit analytical granularity. At 50,000 records, a 50% match rate yields 25,000 matched records – enough to run meaningful segment analysis without running into minimum thresholds constantly. Operations processing fewer than 10,000 monthly leads should evaluate whether the implementation investment justifies the analytical output at that scale.
Can two organizations use different clean room platforms and still collaborate?
Yes, with Habu as the interoperability layer, or if both platforms share a common identity token (RampID, for example). Direct collaboration between AWS Clean Rooms and Snowflake Clean Rooms requires a translation layer. Without Habu or a shared token standard, both parties typically need to be on the same platform – which influences partner onboarding decisions.
How does differential privacy noise affect analytical accuracy?
Differential privacy adds calibrated statistical noise to outputs. The noise magnitude depends on the privacy budget (epsilon value) and query sensitivity. For high-level aggregate queries (total match count, conversion rate), noise is small relative to the value. For granular segment queries (conversion rate for 35-44-year-old homeowners in California), noise may be large relative to the result. Tight privacy budgets that limit information disclosure also limit analytical precision. Design your epsilon values based on how sensitive the data is, not on maximizing query accuracy.
What happens to data when a partnership ends?
Each platform handles termination differently. AWS Clean Rooms: revoking the collaboration removes cross-account access; each party retains their own data in S3. Snowflake: the provider unpublishes the clean room share; consumer access is terminated immediately. LiveRamp Safe Haven: contracted data deletion timelines apply; typically 30-90 days post-termination. InfoSum: the connection is severed; no data was ever transferred, so deletion is immediate. Define termination procedures and audit log retention in partnership agreements before implementation.
What’s the difference between a clean room and a data marketplace?
A data marketplace (Snowflake Marketplace, AWS Data Exchange) sells or licenses data sets – the buyer receives data. A clean room enables analysis on data that neither party receives. Marketplaces are appropriate when the use case is data acquisition. Clean rooms are appropriate when the use case is collaborative analysis without acquisition. Some platforms (Snowflake, AWS) offer both; the distinction is in how the collaboration is structured, not the underlying technology.
How do I validate that a clean room is actually protecting my data?
Request the vendor’s SOC 2 Type II report and review the access controls and cryptographic protections sections. For AWS Clean Rooms and Snowflake, verify that your collaboration configuration enforces the intended analysis rules – create a test query that should be blocked by your rules and confirm it is blocked. For InfoSum, verify the agent deployment is network-isolated and cannot exfiltrate data. Audit log review should show only authorized query patterns. A security-focused implementation review before first production use is appropriate for any new clean room deployment.
Key Takeaways
-
The two architectural models have compliance implications. Centralized computation (AWS, Google, Snowflake) is faster and simpler but data exists in vendor infrastructure. Decentralized computation (InfoSum) keeps data in your environment but carries performance constraints.
-
Identity resolution determines match rates more than platform choice. Without a cross-identifier identity graph, deterministic match rates of 50-65% represent the ceiling. LiveRamp’s RampID or similar graph services improve rates to 65-80% for typical lead generation data.
-
Pricing models align with different use patterns. AWS ($0.01/GB) and Snowflake (credits) suit variable-volume use cases. LiveRamp ($100K+) and InfoSum ($75K-300K) require volume commitments to justify licensing cost.
-
Habu solves the partner ecosystem diversity problem. When collaborating with partners across multiple cloud platforms, Habu’s interoperability layer avoids requiring partner infrastructure standardization.
-
Data pipeline engineering precedes clean room value. Identifier normalization, schema design, refresh scheduling, and error monitoring are prerequisites. Poor upstream data quality surfaces as unexpectedly low match rates and misleading analytical outputs.
-
Schema design should be narrow by default. Contribute only columns required for approved analyses. Wide schemas complicate query governance and expand the privacy control surface area.
Sources
- AWS Clean Rooms - Amazon Web Services’ data clean room solution enabling privacy-preserving collaboration without sharing raw data.
- AWS Clean Rooms Documentation - Technical specifications, analysis rule types, pricing, and ML capabilities
- AWS Clean Rooms Pricing - $0.01/GB analyzed pricing structure and S3 storage costs
- Google Ads Data Hub - Google’s clean room technology for analyzing advertising data with privacy controls.
- LiveRamp: Data Clean Rooms Explained - Enterprise clean room platform documentation explaining identity resolution and privacy-preserving analysis.
- Snowflake Data Clean Rooms - Cloud-native clean room solution with built-in governance and collaboration features.
- Snowflake Data Clean Rooms Guide - Architecture, query template model, and consumption pricing
- Forrester Research - Industry research supporting the 90% B2C marketer adoption statistic and clean room market trends.
- InfoSum Platform - Bunker architecture and decentralized computation model
- Habu Platform - Multi-platform interoperability and activation integrations
Technical architecture decisions made early in clean room implementation determine the ceiling on analytical capability and the floor on implementation cost. Platform selection should follow infrastructure alignment logic – not feature lists. Identity resolution investment should reflect actual match rate impact on business decisions. For the strategic and use-case framework around clean room adoption, see the companion piece on data clean rooms for lead generation privacy matching.