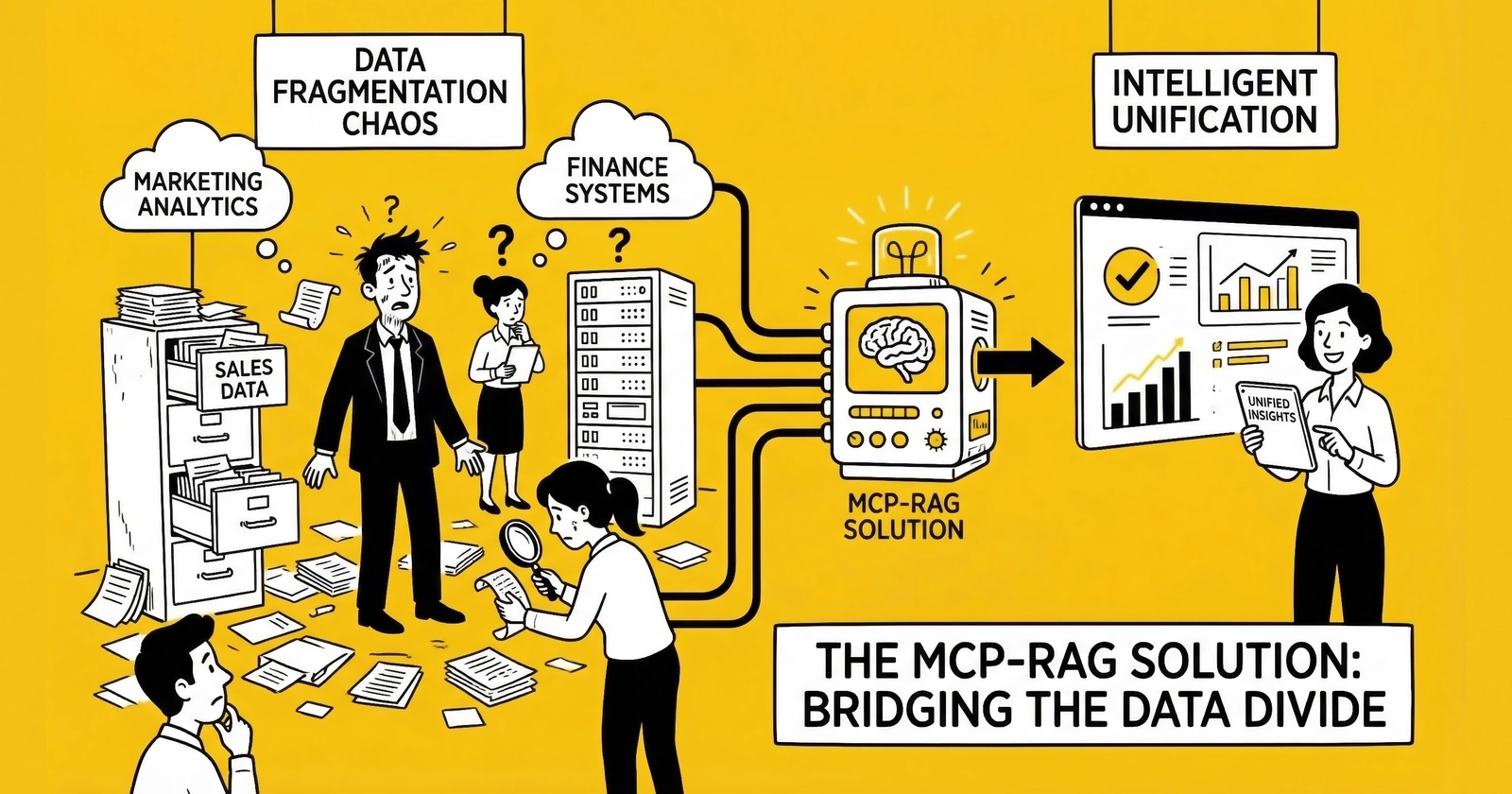
Why traditional integration failed – and how MCP and RAG are creating the unified data architecture enterprises have chased for decades
The invisible tax destroying enterprise value
Every enterprise is paying a hidden tax. It doesn’t appear on any income statement, yet it drains billions annually from organizational productivity, decision quality, and competitive position. This tax has a name: data fragmentation.
The numbers are staggering. IDC and McKinsey estimate that data silos cost the global economy $3.1 trillion annually – a figure so large it approaches the GDP of major nations. For individual organizations, the damage is equally severe: Gartner research shows that bad data caused by fragmentation costs enterprises an average of $12.9 million per year in direct losses from inefficiencies, errors, and missed opportunities.
But the true cost runs deeper than any balance sheet captures. When your sales team can’t access marketing campaign performance data in real-time, they miss opportunities with hot leads. When finance operates without current customer acquisition costs, budget decisions rest on outdated foundations. When product teams can’t see customer service patterns, they build features nobody requested while critical pain points fester.
This fragmentation has reached crisis proportions. The average large enterprise now runs 275+ SaaS applications, according to Productiv research – yet these systems rarely communicate. Each department optimized its individual tools without considering enterprise-wide implications. The result? An archipelago of disconnected data islands where critical insights drown in the space between systems.
The question that has plagued IT leaders for decades is finally being answered: How do you create unified data access without the massive infrastructure projects that have failed repeatedly? The answer lies in a convergence of technologies – Model Context Protocol (MCP) and Retrieval-Augmented Generation (RAG) – that are fundamentally reshaping how enterprises connect AI to their data.
This isn’t incremental improvement. It’s the end of an era where data fragmentation was accepted as an unavoidable cost of doing business.
The anatomy of enterprise data fragmentation
How we got here: the perfect storm
Data silos weren’t created by malicious actors or incompetent IT departments. They emerged from rational decisions made in isolation – each department selecting tools optimized for their specific workflows, each acquisition bringing legacy systems, each new initiative adding another layer to an increasingly complex technology stack.
The pattern is familiar to any enterprise technology leader: Sales chose Salesforce to solve sales problems. Operations selected SAP to handle operational workflows. Marketing adopted HubSpot for campaign management. Finance implemented Oracle for accounting. Each system excels at its primary function, but they were never designed to share a conversation.
Salesforce’s 2024 Connectivity Benchmark Report quantified this paradox: 72% of IT leaders describe their current infrastructure as “overly interdependent,” while simultaneously 80% report that data silos are hindering digital transformation efforts. The systems are connected enough to create dependency nightmares during updates, yet isolated enough to prevent meaningful data sharing.
The problem compounds geometrically as organizations scale. DATAVERSITY’s 2024 Trends in Data Management survey found that 68% of organizations cite data silos as their top concern – up 7% from the previous year. The challenge isn’t stabilizing; it’s accelerating.
The true cost breakdown
Understanding the full impact of data fragmentation requires examining its effects across multiple dimensions:
Productivity hemorrhage
Forrester Research found that knowledge workers spend an average of 12 hours every week “chasing data” across disconnected systems. At a $75,000 annual salary, that’s $1,500+ monthly in lost productivity per employee. Scale this across an organization with thousands of knowledge workers, and the annual cost reaches tens of millions in salary spent on information-seeking rather than value creation.
A Panopto study put even finer resolution on this waste: employees spend 5.3 hours every week waiting for data from colleagues or recreating information that already exists somewhere in the organization. That’s more than half of every workday lost to friction that integrated systems would eliminate.
Decision quality degradation
When executives make decisions based on partial information, the downstream costs multiply. Research from IDC reveals that fragmented data landscapes cause organizations to experience 20-30% revenue loss due to data inefficiencies – not from obvious errors, but from the accumulation of suboptimal decisions made without complete context.
Consider a common scenario: A marketing team launches a campaign targeting a customer segment based on CRM data, unaware that customer service has flagged 40% of that segment as at-risk due to recent complaints logged in a separate support system. The campaign not only wastes marketing spend but actively damages customer relationships. This pattern repeats across enterprises daily, invisible because nobody has visibility into the full picture.
Operational overhead
Maintaining data silos requires additional storage, management, and integration resources that wouldn’t exist in a unified architecture. Organizations maintain duplicate data across multiple systems – the same customer information might exist in the CRM, ERP, marketing automation platform, and customer service system, each with slightly different formats and varying levels of accuracy.
Studies suggest that organizations with severe data silos experience significantly higher operational costs compared to those with unified data architectures. The infrastructure overhead alone – separate servers, backup systems, security protocols, and administrative staff for each siloed system – represents substantial ongoing expense.
Security and compliance exposure
Fragmented data creates security blind spots. IBM’s 2025 Cost of a Data Breach Report indicates a global average breach cost of $4.44 million per incident, with data silos significantly increasing both breach likelihood and severity. When security teams lack visibility into where sensitive data resides across siloed systems, attack surfaces expand and incident response slows.
Compliance adds another dimension. GDPR, HIPAA, SOC 2, and other regulations require organizations to know what data they hold, where it’s stored, and how it’s protected. Fragmented architectures make this accounting nearly impossible, creating ongoing regulatory exposure.
Why traditional integration failed
If data silos impose such massive costs, why haven’t enterprises solved this problem already? Not for lack of trying. The enterprise integration market has consumed hundreds of billions in investment over the past three decades. Yet the silo problem persists.
ETL’s fundamental limitations
Extract, Transform, Load (ETL) pipelines were the traditional answer to data fragmentation. The approach seemed logical: extract data from source systems, transform it into a common format, and load it into a central warehouse for analysis. The ETL market reached $7.63 billion in 2024 and is projected to surge to $29.04 billion by 2029.
But ETL has inherent limitations that prevent it from solving the fragmentation problem:
Latency: Datavail found that two-thirds of ETL data is more than 5 days old by the time it reaches destination systems. For organizations requiring real-time or near-real-time data access – which increasingly includes most enterprises in competitive markets – this delay renders the data strategically useless.
Fragility: Traditional ETL pipelines break when source systems change. A single schema modification in a source database can cascade into pipeline failures that take days to diagnose and repair. Without proper monitoring, these pipelines “fail silently, leading to incomplete or inconsistent data loads.”
Complexity: Building and maintaining ETL workflows requires specialized technical expertise. Changes to data sources require constant updates to ETL scripts, increasing complexity over time. As organizations add more data sources, the maintenance burden grows exponentially.
Inflexibility: Organizations requiring dynamic, real-time data access find traditional ETL too rigid. The batch-processing model that ETL assumes simply doesn’t match modern business requirements for instant information access.
Data warehouse migration failures
The data warehouse approach – centralizing all organizational data in a single analytical repository – promised to eliminate silos. But implementation reality has been brutal.
Gartner reports that 80% of data migration projects fail to meet their objectives. McKinsey research shows 75% of migration programs run over budget and 38% fall more than a quarter behind schedule. The global impact of “surprise” migration spend exceeds $100 billion over three years, putting $500 billion of shareholder value at risk.
Research from Cloudficient reveals the specific failure modes:
| Failure Pattern | Percentage |
|---|---|
| Legacy data format incompatibility | 45% |
| Poor data quality affecting migrations | 84% |
| Reliance on 10+ year old systems | 73% |
| Timeline overrun by 40-100% | 61% |
The fundamental problem? Data warehouses attempt to move and copy data, a strategy that cannot keep pace with the velocity and variety of modern enterprise information. By the time data reaches the warehouse, it’s already aging. And maintaining the extraction, transformation, and loading infrastructure becomes its own IT burden.
The N×M integration problem
Perhaps the deepest structural barrier to unified data has been what practitioners call the “N×M problem.” When organizations build AI applications to connect with enterprise data sources, each combination of AI tool and data source historically required a custom integration.
Ten AI applications connecting to 100 data sources meant potentially 1,000 custom connectors to build and maintain. This engineering burden made most enterprise data permanently inaccessible to AI systems – not because the technology to access it didn’t exist, but because the integration cost was prohibitive.
This is the context into which Model Context Protocol emerged – not as another incremental improvement to ETL or data warehousing, but as a fundamental rearchitecting of how AI systems connect to enterprise data.
The MCP revolution
What MCP actually is
Model Context Protocol is an open standard introduced by Anthropic in November 2024 that provides a universal interface for AI systems to connect with data sources and tools. Often described as “USB-C for AI” – just as USB-C created a single connector standard for devices, MCP creates a single protocol standard for AI-to-data connections.
Before MCP, every AI application that needed to access enterprise data required custom integration work for each data source. A company wanting to connect Claude to their PostgreSQL database, Salesforce CRM, GitHub repositories, and internal documentation might need four separate, custom-built integrations – each with its own maintenance burden.
MCP transforms this from a multiplicative problem to an additive one. Rather than building N×M custom integrations, organizations implement MCP once on each side. The AI application becomes an MCP client. The data source exposes an MCP server. Any MCP client can communicate with any MCP server through the standardized protocol.
The technical architecture is straightforward:
- MCP Clients run within AI applications (chat assistants, coding tools, analysis platforms) and communicate with one or more MCP servers
- MCP Servers expose data sources and tools through standardized interfaces
- The Protocol defines how clients and servers exchange information using JSON-RPC 2.0
MCP specifies three core primitives:
- Resources: Context and data retrieval (documents, database records, files)
- Tools: Executable functions with side effects (write operations, API calls)
- Prompts: Reusable templates for LLM interactions
When an AI application connects to an MCP server, capability negotiation occurs automatically. The server declares what resources it offers and what tools it can execute. The client immediately begins accessing these capabilities without any custom code.
Unprecedented adoption velocity
The adoption trajectory of MCP has been remarkable by any technology standard measure. Within 12 months of launch:
- 97 million+ monthly SDK downloads across Python and TypeScript
- Over 10,000 active MCP servers deployed globally
- 5,800+ MCP servers publicly available in registries
- 300+ MCP clients in active use
For comparison, similar infrastructure standards like OpenAPI and OAuth 2.0 required 4-5 years to achieve comparable cross-vendor adoption. MCP achieved it in 12 months.
The reason for this velocity lies in the alignment of incentives across traditionally competing players. AI companies recognized that ecosystem interoperability benefits all participants – the more data sources accessible through MCP, the more valuable every MCP-compatible AI system becomes.
Timeline of major adoption:
| Date | Milestone |
|---|---|
| November 2024 | Anthropic launches MCP with initial servers for GitHub, Slack, Postgres |
| March 2025 | OpenAI announces full MCP adoption across ChatGPT and Agents SDK |
| April 2025 | Google DeepMind confirms MCP integration with Gemini ecosystem |
| May 2025 | Microsoft joins MCP steering committee at Build 2025, announces Windows 11 integration |
| December 2025 | Anthropic donates MCP to Agentic AI Foundation under Linux Foundation governance |
The formation of the Agentic AI Foundation (AAIF) cemented MCP’s position as the industry standard. Co-founded by Anthropic, OpenAI, and Block, with Amazon Web Services, Bloomberg, Cloudflare, Google, and Microsoft as platinum members, AAIF provides neutral governance ensuring no single vendor controls the protocol’s evolution.
Jensen Huang, CEO of NVIDIA, declared in November 2025: “The work on MCP has completely revolutionized the AI landscape.”
Why MCP succeeds where others failed
MCP’s success isn’t accidental. Several design decisions enable it to solve problems that defeated previous integration approaches:
1. No data movement required
Unlike ETL pipelines or data warehouses, MCP doesn’t copy data. It provides access. The database remains where it is; the MCP server exposes an interface to query it. This eliminates latency, maintains single sources of truth, and avoids the massive infrastructure overhead of data movement architectures.
2. Decentralized, not centralized
Traditional integration approaches tried to centralize everything in a single repository. MCP takes the opposite approach – a federated model where each data source runs its own MCP server. This matches how enterprises actually operate, with departments maintaining their own systems while exposing controlled access through standardized interfaces.
3. Security by design
MCP keeps credentials local. No API keys or sensitive data need to be shared with AI providers. All authentication remains with the MCP server under organizational control. The AI model never directly accesses data sources – it communicates only through the MCP client, which can enforce access controls, audit logging, and approval workflows.
4. Incremental adoption
Organizations don’t need to replace their existing infrastructure to adopt MCP. They can add MCP servers to existing systems incrementally – starting with a single database or application, proving value, then expanding. This reduces risk and allows learning before large-scale commitment.
5. Community-driven ecosystem
With 10,000+ MCP servers already available, most common enterprise systems already have production-ready implementations. Organizations often don’t need to build custom servers – they can deploy existing, community-vetted implementations for Salesforce, PostgreSQL, MySQL, Google Drive, Slack, GitHub, Jira, Notion, and hundreds of other platforms.
Enterprise implementation results
Early enterprise adopters are reporting significant results:
Development efficiency
Organizations report 30% reductions in development overhead when implementing AI features using MCP compared to custom integrations. GitHub’s MCP Developer Productivity Impact Study found developers completing integration tasks 50-75% faster than with traditional approaches.
Integration speed
Dust, an AI workflow platform, integrated Stripe payment capabilities in 5 minutes using MCP – versus the 8-week timeline traditional API integration would require. This isn’t an anomaly; the pattern of integration time collapsing from weeks to hours appears across enterprise implementations.
Healthcare results
Healthcare organizations have documented 70-80% reduction in integration costs and 25% increases in clinical staff efficiency through MCP adoption. The protocol’s security model – where patient data never leaves organizational control – addresses HIPAA concerns that blocked previous AI integration attempts.
Consumer packaged goods
CPG companies report MCP-enabled AI achieving 30% reduction in demand forecasting errors (Nestlé implementation), with temperature-sensitive product categories showing ROI within 3-6 months. Trade promotion optimization via MCP generates 15-25% higher incremental volume by coordinating pricing, competitive intelligence, and seasonality data that previously existed in separate systems.
RAG as the enterprise context engine
Beyond basic retrieval
While MCP solves the connectivity problem – how AI systems access data – Retrieval-Augmented Generation (RAG) addresses a complementary challenge: how AI systems use that data to generate accurate, contextual responses.
RAG works by retrieving relevant information from knowledge bases at inference time, then providing that information as context for language model generation. Rather than relying solely on what the model “learned” during training, RAG enables real-time access to current, organization-specific information.
The architecture operates through three stages:
- Retrieval: When a query arrives, the system searches knowledge bases using semantic similarity (comparing the meaning of the query to stored content) to find relevant documents
- Augmentation: Retrieved content is formatted and combined with the original query to provide context
- Generation: The language model generates a response grounded in both retrieved facts and its general capabilities
This approach transforms AI from systems that can only recall training data into systems that can access and reason over dynamic enterprise knowledge.
The evolution from basic to agentic RAG
RAG has evolved dramatically since Meta researchers coined the term in 2020:
Basic RAG (2020-2022): Keyword matching and simple retrieval. Documents chunked into fixed-size pieces, embedded as vectors, matched against query vectors. Functional but brittle – prone to retrieving contextually irrelevant content that happened to share keywords.
Advanced RAG (2023-2024): Dense vector search, query transformation, and neural re-ranking. Systems learned to rewrite queries for better retrieval, rank results by relevance beyond simple similarity, and handle multi-step retrieval for complex questions.
Graph RAG (2024): Microsoft Research introduced knowledge graphs that model entities and relationships explicitly. Rather than treating documents as isolated chunks, Graph RAG understands that “John Smith” in document A is the same person as “J. Smith, VP Sales” in document B. This enables multi-hop reasoning: “Find all customers who purchased from John Smith’s team last quarter” requires traversing relationships across multiple data sources.
Agentic RAG (2024-2025): The current frontier. AI agents autonomously decide retrieval strategies, refine queries through feedback loops, and orchestrate multi-step workflows. If initial retrieval doesn’t yield sufficient information, the agent formulates follow-up queries, searches different knowledge bases, or combines partial results into comprehensive answers.
Why RAG beats fine-tuning for enterprise
Enterprises face a choice: fine-tune models on company data, or use RAG to provide context at inference time. The economics strongly favor RAG for most use cases:
Cost comparison
| Approach | Cost | Time to Deploy |
|---|---|---|
| Fine-tuning 70B model | $50,000-$200,000 | Weeks |
| RAG embedding (10K docs) | Under $100 | Hours to days |
| Per-document RAG update | $0.001-$0.01 | Minutes |
Update flexibility
When policies change or new products launch, fine-tuned models require expensive retraining – potentially weeks of work before the AI reflects new information. RAG systems update in hours by simply embedding new documents into the knowledge base.
Audit and explainability
RAG provides natural auditability. Every response can cite the specific documents from which information was retrieved, with page numbers, section headers, and exact quotes. This provenance tracking is essential in regulated industries where AI decisions require explanation.
Accuracy results
Databricks reports that 60% of their LLM deployments now use RAG, establishing it as the dominant pattern for enterprise AI. Organizations implementing advanced RAG architectures report 45% cost reductions and 3x faster resolution times compared to keyword-only search systems.
The context engine paradigm
As 2025 draws to a close, the industry is converging on a new conceptualization of RAG’s role. Rather than viewing it as merely a retrieval technique, enterprise architects increasingly describe RAG as the “Context Engine” – a unified layer that assembles relevant information for any AI interaction.
RAGFlow’s 2025 analysis articulates this evolution:
“RAG is no longer just a step in ‘Retrieval-Augmented Generation.’ With ‘retrieval’ as its core capability, expanding its data scope, it evolves into a Context Engine supporting all context assembly needs, becoming the unified Context Layer and data foundation serving LLM applications.”
This reframing has practical implications. In the traditional search era, the initiator, executor, and consumer of retrieval were all humans. The user posed a question; the search engine returned links; the user read, compared, and synthesized.
In the AI agent era, AI systems are the primary consumers of retrieved information. This inverts requirements – AI agents need comprehensive context assembled from multiple sources, not a ranked list of links to evaluate. The Context Engine must gather, synthesize, and present information in formats optimized for AI reasoning, not human browsing.
The unified architecture
MCP + RAG: the complete solution
MCP and RAG solve complementary problems that together address the enterprise data fragmentation challenge:
| Challenge | Solution |
|---|---|
| How does AI access enterprise data? | MCP standardizes connectivity |
| How does AI use that data effectively? | RAG retrieves and contextualizes |
| How do we avoid custom integration for each source? | MCP servers provide universal access |
| How do we ground responses in current information? | RAG retrieves at inference time |
| How do we maintain security and governance? | MCP keeps credentials local; RAG respects permissions |
The architecture works together: MCP provides the plumbing that connects AI to data sources. RAG provides the intelligence that retrieves and contextualizes relevant information. Together, they enable AI systems that have comprehensive access to enterprise knowledge while generating responses grounded in current, accurate information.
Context engineering: the emerging discipline
As MCP and RAG mature, a higher-order discipline is emerging: Context Engineering – the practice of designing information environments so AI systems can understand intent and deliver enterprise-aligned outcomes.
Gartner formally defined context engineering in October 2025, recommending organizations appoint dedicated Context Engineering Leads integrated with AI and governance teams. The recognition reflects a fundamental insight: prompt engineering alone – crafting clever instructions – represents perhaps 5% of what makes enterprise AI successful. The remaining 95% depends on holistic information environments that provide situational awareness across enterprise systems.
Andrej Karpathy, former OpenAI founding member, captured this shift:
“In every industrial-strength LLM app, context engineering is the delicate art and science of filling the context window with just the right information for the next step.”
Promethium.ai has defined a five-level context architecture:
- Physical Schema: Column names, data types, table structures
- Relationships: Join paths, foreign keys, entity connections
- Data Catalog: Descriptions, owners, lineage information
- Semantic Layer: Metric definitions, business rules, calculation logic
- Memory/Learning: Query patterns, user preferences, historical context
Organizations achieving all five levels report 94-99% AI accuracy. Those with fragmented context struggle at 10-20% accuracy – a difference that determines whether AI initiatives succeed or fail at scale.
This isn’t abstract theory. LinkedIn implemented a combined RAG and knowledge graph architecture that improved customer service AI accuracy by 78% and reduced median resolution time by 29% over six months. The explicit relationship modeling enabled AI to understand customer context across interactions, account history, product usage, and support patterns – information that previously existed in separate systems never consulted simultaneously.
Knowledge graphs as context foundation
Knowledge graphs have emerged as the structural foundation for enterprise context engineering. Unlike unstructured document retrieval, knowledge graphs model entities and relationships explicitly.
Glean, a leading enterprise AI platform built by former Google Search engineers, explains the value:
“Large language models don’t work well with data from enterprise environments. When a model doesn’t have enough understanding of the context around a user’s request, it can give the wrong answer. Knowledge graphs contain many of the building blocks that inform a helpful, personalized response.”
The distinction matters for complex queries. Consider: “Show me all deals at risk where the primary contact has opened a support ticket in the last 30 days.”
This query requires:
- Understanding what “deal” means in the organization’s context
- Identifying which deals are “at risk” based on business definitions
- Mapping deals to primary contacts across CRM records
- Connecting contacts to support tickets in a separate system
- Applying time filters based on ticket creation dates
No single data source contains this answer. A knowledge graph that models the relationships – deals have contacts; contacts open tickets; tickets have creation dates – enables the AI to traverse connections and synthesize a response from multiple sources.
The defragmentation architecture
Pulling these elements together, the modern enterprise data architecture for AI looks fundamentally different from traditional integration approaches:
1. Data stays in place Unlike ETL or warehouse approaches, data remains in source systems. There’s no massive data movement project, no central repository to maintain, no latency from extraction and loading.
2. MCP servers expose access Each data source runs an MCP server that exposes standardized interfaces for AI access. Organizations start with high-priority systems and expand incrementally.
3. Knowledge graphs model relationships Entity and relationship models capture how data across sources connects – customers to orders, employees to projects, products to support tickets.
4. RAG retrieves contextually When AI needs information, RAG systems query across MCP-connected sources, using knowledge graph relationships to assemble comprehensive context.
5. Semantic layers provide business logic Metric definitions, business rules, and calculation logic ensure AI interprets data according to organizational understanding, not raw values.
6. Governance remains intact Permission systems, audit logging, and access controls operate at the MCP server level, ensuring AI respects the same security boundaries as human users.
This architecture addresses each failure mode of traditional integration:
- No data movement means no latency
- Federated design means no single point of failure
- Standardized protocol means no custom integration per source
- Local credentials mean no security compromise
- Incremental adoption means no massive migration project
Implementation realities
The 95% failure rate and how to beat it
Despite unprecedented technology availability, enterprise AI deployment remains challenging. The MIT NANDA report found that 95% of enterprise AI pilots fail to deliver measurable business impact. Understanding why most fail illuminates how to succeed.
Common failure patterns:
Pilot purgatory: Organizations run endless experiments without transitioning to production. Large enterprises take 9 months on average to scale AI initiatives versus 90 days for mid-market companies. The deliberation itself becomes the outcome.
AI as accessory: Organizations attempt to add AI to existing processes without redesigning workflows. Research shows organizations that fundamentally redesign workflows are 3x more likely to succeed than those adding AI as a supplement.
Build syndrome: Companies attempt to build custom AI infrastructure rather than leveraging existing platforms. MIT found that external AI vendor partnerships succeed 67% of the time versus 33% for internal builds.
Wrong target: Investment flows to customer-facing experiments while the highest ROI appears in compliance, finance automation, and operations – back-office functions that don’t generate executive excitement but do generate measurable returns.
Success patterns:
The 5% that succeed share common characteristics:
-
Start narrow: Successful implementations target a single, well-defined use case with measurable outcomes – not comprehensive enterprise transformation. The 90-day pilot model proven by Unilever and Nestlé prioritizes quick wins over grand visions.
-
Redesign, don’t augment: Rather than adding AI to existing processes, successful organizations redesign workflows around AI capabilities. This requires organizational change management, not just technology deployment.
-
Buy before build: Enterprise platforms provide production-ready infrastructure that internal teams typically underestimate in complexity. The critical capabilities – permission-aware retrieval, semantic layer integration, hallucination management – require years of refinement that vendors have already invested.
-
Measure outcomes, not outputs: Successful deployments track business metrics – time saved, decisions improved, costs reduced – not technology metrics like API calls or model accuracy scores.
-
Plan for governance: The EU AI Act compliance deadline arrives in August 2026. Forrester predicts that 30% of large enterprises will mandate AI training in 2026 to reduce risk. Organizations building governance into initial deployments avoid costly retrofitting.
Technology selection framework
With the MCP + RAG architecture as foundation, organizations must make practical technology choices:
MCP server selection
For standard integrations (Slack, Google Drive, PostgreSQL), community or vendor-supported MCP servers are typically superior to custom builds. The ecosystem already includes production-tested implementations for most common enterprise systems.
Custom MCP servers make sense for:
- Proprietary internal systems with no existing implementation
- Sensitive data requiring enhanced security controls
- Specialized access patterns not covered by standard servers
RAG platform selection
Enterprise RAG platforms have matured significantly. Key evaluation criteria:
- Permission-aware retrieval: Does the system respect source system permissions? Can it ensure users only access data they’re authorized to see?
- Semantic layer integration: Can the platform incorporate business definitions, not just raw data?
- Citation and provenance: Does every response cite specific sources for auditability?
- Multi-source federation: Can it query across multiple data sources in a single request?
- Hallucination management: What controls exist to prevent fabricated responses?
Leading platforms include Glean (enterprise knowledge management), Vectara (retrieval accuracy focus), and cloud-native offerings from Snowflake (Cortex) and Databricks (AI/BI).
Knowledge graph options
Knowledge graph implementation ranges from lightweight property graphs in Neo4j to enterprise platforms like Stardog or cloud-native options in major data platforms. Key considerations:
- Entity resolution: How does the system identify that records across sources represent the same entity?
- Relationship modeling: How expressive is the relationship vocabulary?
- Scale: What query performance at enterprise data volumes?
- Integration: How does the graph integrate with RAG retrieval?
Cost-benefit reality
The economics of unified data architecture have shifted dramatically with MCP and RAG:
Traditional approach costs:
- Enterprise integration platform: $50,000-$500,000 annually
- Data warehouse: $100,000-$1,000,000+ annually
- Custom ETL development: $100K-$1M per major integration
- Maintenance: 20-30% of initial investment annually
- Timeline: 12-24 months to initial deployment
MCP + RAG approach costs:
- MCP server deployment: Often free (open source) to $10-50K for enterprise implementations
- RAG platform: $20,000-$200,000 annually depending on scale
- Knowledge graph: $50,000-$300,000 annually for enterprise deployment
- Timeline: 90-180 days to initial deployment
The cost reduction is significant, but the more important shift is speed. Organizations can prove value in months rather than years, iterating based on real results rather than multi-year project plans.
ROI calculation:
Consider a mid-sized enterprise with 1,000 knowledge workers:
Current state:
- 12 hours/week per employee chasing data = $1,500/month/employee
- Annual data-chasing cost: $18 million
- $12.9 million in bad data costs (Gartner average)
- Total: ~$31 million annually in fragmentation costs
With unified architecture:
- 50% reduction in data-chasing time: $9 million savings
- 30% reduction in bad data costs: $3.9 million savings
- Implementation cost: $500K-$1M in year one
- Net first-year benefit: $12-13 million
These calculations are conservative. They don’t include revenue impacts from better decisions, customer experience improvements from unified context, or competitive advantages from faster insight generation.
The path forward
From fragmentation to foundation
The enterprise data fragmentation problem has persisted for decades not because technology was unavailable, but because previous approaches required moving data – a strategy that cannot scale with modern information velocity. MCP and RAG represent a fundamental architectural shift: instead of centralizing data, they provide universal access while leaving data in place.
This shift has profound implications:
For IT leaders: The integration tax that has consumed engineering resources for decades is finally addressable. Rather than building and maintaining custom connectors, organizations can adopt standardized protocols that leverage community-maintained implementations. Engineering talent previously dedicated to integration plumbing can redirect toward value-creating applications.
For business leaders: The data that has been locked in departmental silos becomes accessible for enterprise-wide insight. The 66% of organizational data that currently goes unused can finally contribute to decisions. Cross-functional analytics that were practically impossible become routine.
For data teams: The shift from moving data to providing access changes the fundamental job description. Rather than ETL specialists maintaining brittle pipelines, data teams become context engineers – designing information architectures that enable AI to understand enterprise knowledge.
The 90-day start
Organizations ready to address data fragmentation should consider a focused initial deployment:
Days 1-30: Assessment and selection
- Inventory current data sources and integration pain points
- Identify highest-value use case for initial deployment
- Select MCP servers and RAG platform
- Define success metrics
Days 31-60: Initial implementation
- Deploy MCP servers for priority data sources
- Configure RAG platform with initial knowledge base
- Implement basic knowledge graph for entity relationships
- Begin user testing with limited scope
Days 61-90: Validation and planning
- Measure results against success metrics
- Gather user feedback and iterate
- Document learnings and governance requirements
- Plan expansion to additional use cases and data sources
The key is starting with a narrow, well-defined use case that can prove value quickly – not attempting comprehensive enterprise transformation. Organizations that successfully deploy AI follow the pattern of proving value incrementally, not betting everything on a massive initial project.
The competitive imperative
The window for establishing unified data architecture as competitive advantage is closing. As MCP adoption accelerates toward the projected 90% of organizations by end of 2025, the technology itself becomes table stakes. The advantage accrues to organizations that implement effectively – that build the context engineering capabilities, knowledge graph foundations, and governance frameworks that transform raw connectivity into enterprise intelligence.
Organizations that delay face compounding disadvantage:
- Each quarter of fragmentation costs approximately $8 million for a typical large enterprise
- Competitors with unified architectures gain cumulative decision-making advantages
- The talent market for context engineering is tightening as demand grows
- Governance requirements increase as AI regulation expands
The $3.1 trillion global cost of data silos isn’t distributed evenly. Organizations that solve the fragmentation problem capture value from those that don’t. The technology is now available. The question is execution.
Key takeaways
-
Data silos impose a $3.1 trillion annual global tax. Individual enterprises lose $12.9 million yearly from fragmentation. Knowledge workers spend 12 hours per week – $1,500 monthly per employee – chasing data across disconnected systems.
-
Traditional integration approaches failed because they move data. ETL pipelines produce data that’s 5+ days stale. 80% of data migration projects fail. The N×M integration problem made custom connectors prohibitively expensive.
-
MCP transforms integration from multiplicative to additive. Organizations implement the protocol once on each side rather than building N×M custom integrations. 97 million+ monthly SDK downloads and adoption by all major AI vendors confirm MCP as the industry standard.
-
RAG grounds AI in current enterprise knowledge. 60% of enterprise LLM deployments now use RAG. The cost economics favor RAG over fine-tuning by orders of magnitude – $100 versus $50,000+ for equivalent knowledge bases.
-
Context engineering determines AI success. Organizations achieving complete context architecture report 94-99% AI accuracy versus 10-20% for fragmented approaches. This discipline – not prompt engineering – drives enterprise AI value.
-
The 95% enterprise AI failure rate has identifiable causes. Pilot purgatory, AI as accessory to existing processes, build versus buy decisions, and targeting wrong use cases explain most failures. The 5% that succeed share common patterns.
-
Implementation timelines have compressed from years to months. The 90-day pilot model – assessment, implementation, validation – enables organizations to prove value before major commitment. Incremental adoption reduces risk.
-
First-mover advantages are compounding. As MCP adoption accelerates, the technology becomes table stakes. Competitive advantage shifts to context engineering capabilities, knowledge graph foundations, and governance frameworks.
-
The economics strongly favor action. Conservative ROI calculations show $12-13 million net first-year benefit against $500K-$1M implementation cost for mid-sized enterprises. Delay costs approximately $8 million quarterly.
-
The data silo era is ending. MCP and RAG enable architectures where AI has comprehensive enterprise access without massive infrastructure projects. The technology is ready. The economic case is clear.
Frequently asked questions
What is the Model Context Protocol (MCP)?
MCP is an open standard introduced by Anthropic in November 2024 that provides a universal interface for AI systems to connect with data sources and tools. Often called “USB-C for AI,” it standardizes how AI applications access enterprise data through a single protocol rather than requiring custom integrations for each data source.
How much do data silos cost enterprises?
IDC and McKinsey estimate data silos cost the global economy $3.1 trillion annually. Individual organizations lose an average of $12.9 million per year in direct costs from inefficiencies, errors, and missed opportunities. Knowledge workers spend 12 hours per week chasing data across disconnected systems.
Why do traditional ETL pipelines fail?
Traditional ETL has four fundamental limitations: latency (two-thirds of ETL data is over 5 days old when it reaches destinations), fragility (pipelines break when source systems change), complexity (requiring specialized expertise and constant updates), and inflexibility (batch processing doesn’t match real-time business needs).
What is Retrieval-Augmented Generation (RAG)?
RAG enhances AI systems by retrieving relevant information from knowledge bases at inference time, then providing that context for response generation. Rather than relying solely on training data, RAG enables real-time access to current, organization-specific information with citation and auditability.
Why does RAG beat fine-tuning for enterprise use cases?
Fine-tuning a 70B parameter model costs $50,000-$200,000 in compute and takes weeks. RAG costs roughly $0.001-$0.01 per document to embed – a typical 10,000-document knowledge base can be indexed for under $100. RAG also updates in hours versus weeks for fine-tuning, and provides natural audit trails.
What is context engineering?
Context engineering is the practice of designing information environments so AI systems can understand intent and deliver enterprise-aligned outcomes. Gartner formally defined it in October 2025. Organizations achieving comprehensive context architecture report 94-99% AI accuracy versus 10-20% for fragmented approaches.
What adoption has MCP achieved?
Within 12 months of launch, MCP achieved 97 million+ monthly SDK downloads, over 10,000 active servers deployed globally, and adoption by Anthropic, OpenAI, Google DeepMind, Microsoft, and Amazon. The Agentic AI Foundation was formed to provide neutral governance under the Linux Foundation.
Why do 95% of enterprise AI pilots fail?
Common failure patterns include pilot purgatory (endless experiments without production deployment), treating AI as an accessory to existing processes rather than redesigning workflows, building custom infrastructure instead of leveraging existing platforms, and targeting low-ROI customer-facing experiments over high-ROI back-office operations.
How does MCP differ from traditional integration approaches?
Unlike ETL or data warehouses, MCP doesn’t copy data – it provides access. Data stays in source systems while MCP servers expose standardized interfaces. This eliminates latency, maintains single sources of truth, keeps credentials local for security, and enables incremental adoption rather than massive migration projects.
What ROI can enterprises expect from unified data architecture?
A typical mid-sized enterprise with 1,000 knowledge workers spends approximately $31 million annually on fragmentation costs. Conservative estimates suggest 50% reduction in data-chasing time ($9M savings) and 30% reduction in bad data costs ($3.9M savings), yielding $12-13 million net first-year benefit against $500K-$1M implementation cost.
Sources
- Anthropic - Creator of Model Context Protocol (MCP), launched November 2024 as universal AI-to-data connector standard
- IDC - Research firm documenting $3.1 trillion annual global cost of data silos
- Salesforce Connectivity Benchmark - Research showing 72% of IT leaders describe infrastructure as overly interdependent while 80% report data silos hindering transformation
- Linux Foundation - Host of Agentic AI Foundation providing neutral governance for MCP protocol evolution
- Databricks - Platform reporting 60% of LLM deployments now use RAG architecture
- IBM Cost of a Data Breach Report - Global average breach cost of $4.44 million with data silos increasing breach severity
- Glean - Enterprise AI platform demonstrating knowledge graph value for AI context assembly