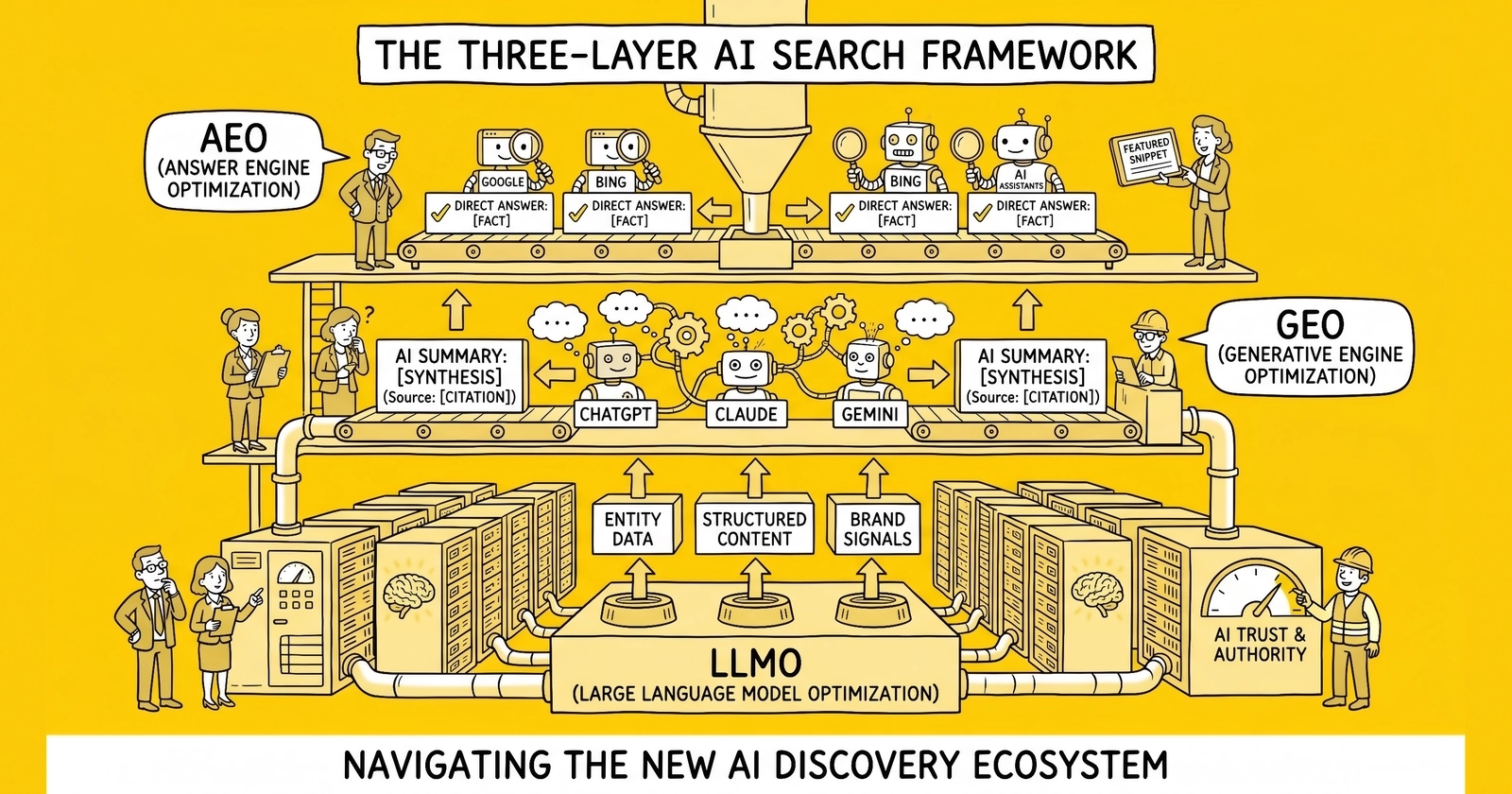
Three acronyms, three problems, one schema stack – operators who collapse LLMO, GEO, and AEO into a single campaign typically optimize for none of them.
Why three frameworks emerged simultaneously
The AI search landscape fractured between November 2023 and April 2026. Before that window, search optimization meant Google. After it, search optimization meant a fragmented surface area: ChatGPT trained on snapshots of the web, Perplexity citing live sources, Google AI Overviews synthesizing across the index, voice assistants extracting direct answers, and a dozen smaller engines slicing the same content differently. Each surface produced its own optimization vocabulary. By 2026, three terms dominated practitioner conversations – LLMO, GEO, and AEO – and most operators conflated them.
The conflation is understandable. The three frameworks share a foundation. All three reward structured data, entity clarity, author credibility, and content that survives extraction without losing meaning. All three penalize keyword stuffing, thin content, and unverifiable claims. Sites that win in one usually rank in the others. But the tactics, measurement systems, and even the underlying mathematics diverge enough that treating them as synonyms produces blind spots – sites that build training-data authority but lose retrieval citations, or sites optimized for direct extraction that never appear in synthesized answers.
Pranjal Aggarwal and co-authors at Princeton, Georgia Tech, the Allen Institute for AI, and IIT Delhi formalized the first of the three. Their paper, GEO: Generative Engine Optimization, hit arXiv on November 16, 2023, and won publication at KDD 2024. The paper introduced GEO-bench, a benchmark of diverse user queries, and demonstrated that nine specific optimization tactics could boost source visibility by up to 40 percent in generative engine responses. The number circulated through SEO Twitter, settled into agency pitch decks, and seeded the term GEO before most marketing teams understood what a generative engine was.
LLMO emerged in parallel from the practitioner side rather than academia. Marketers watching ChatGPT cite some sources and ignore others started optimizing for the model itself rather than the engine wrapped around it. By early 2026, LLMO had calcified into a recognizable framework with four pillars – entity architecture, E-E-A-T amplification, content structure for AI consumption, and cross-platform optimization – and dedicated tooling stacks. Adobe Analytics reported AI traffic growth of 527 percent across five months. Conversion rates from AI-referred sessions ran 4.4 times higher than traditional organic, with Claude visitors averaging 4.56 dollars per session and Perplexity visitors 3.12 dollars. The economics justified separate budgets.
AEO arrived last and matured fastest. The April 2026 Open PR coverage of eight AEO-as-a-service agencies marked the inflection point at which Answer Engine Optimization transitioned from experimental practice to formally defined service category. The term itself predates the others – voice search optimization in the 2017-2019 era used AEO to mean optimizing for direct-answer extraction in Google’s featured snippets and Alexa replies. The 2026 version inherited that tactical DNA but applied it to AI-native answer surfaces rather than legacy voice and featured snippet formats. Conductor’s enterprise AEO definition, frase.io’s complete AEO guide, and Wikipedia’s generative engine optimization entry all treat AEO and GEO as overlapping but non-identical disciplines. Trade publications use the terms interchangeably; vendors selling tooling do not.
Three frameworks emerged simultaneously because the underlying technology fractured into three problem spaces at roughly the same time. Pretrained model citation is one problem. Retrieval-augmented generation is another. Direct answer extraction is a third. Marketers needed labels to budget against, and the SEO industry obliged.
LLMO – what it actually means
Large Language Model Optimization optimizes for citation inside the model itself. ChatGPT, Claude, and Gemini all draw on pre-training corpora that AI vendors curated months or years before the user ever asked a question. When a user asks ChatGPT-4 a question with the browsing tool disabled, the model answers from its training data – and the sources that appear, both as named citations and as paraphrased influence on the answer, were locked in long before the query.
This creates a mechanical reality most marketers misunderstand: LLMO is partially retroactive. A site that publishes great content today cannot guarantee inclusion in a model trained six months ago. What it can do is appear consistently across the web sources AI vendors crawl during training – Wikipedia, GitHub, Reddit, news archives, academic preprints, and the long tail of authoritative trade publications. Common Crawl, the public web archive most AI vendors sample, captures roughly 250 billion pages across two decades. Sites with broad citation coverage in Common Crawl get represented across model generations.
The four pillars practitioners converged on by 2026 are entity architecture, E-E-A-T amplification, content structure for AI consumption, and cross-platform distribution. Entity architecture demands that a company describe itself precisely and consistently across every surface – not “a digital marketing agency” on one page and “an integrated communications partner” on another. Language models reading both pages register ambiguity and downweight the entity. The fix is canonical entity description, repeated across the homepage, About page, author bios, LinkedIn, Crunchbase, Wikipedia, and Wikidata, with the same name, same description, and same domain expertise framing.
E-E-A-T amplification – Experience, Expertise, Authoritativeness, Trustworthiness – runs deeper for LLMO than for traditional SEO. Google’s E-E-A-T scoring considers signals on the source page. Language models consider signals across the entire web representation of the entity. A founder claiming compliance expertise without a LinkedIn profile, conference bio, or trade press coverage produces inconsistency that LLM training pipelines flag and downweight. Operators who systematize their LLMO presence typically report 45 percent increases in citation frequency within two quarters once entity consistency catches up across platforms.
Content structure for AI consumption is the most tactical pillar. Language models extract from text the way human readers skim – section headers signal scope, opening sentences carry the load, FAQ blocks get pulled verbatim. A 5,000-word essay with no structure produces fewer citations than a 2,000-word piece with clear H2s, an FAQ block, and statistics formatted as standalone facts. Featured snippet patterns – 40-to-60-word direct answers – show up disproportionately in ChatGPT outputs because the training pipeline rewards extractable units.
Cross-platform optimization recognizes that LLMs trained on different mixes produce different citation patterns. Anthropic’s Claude weights Common Crawl differently than OpenAI’s GPT models. Google’s Gemini draws heavily on Google’s index. Perplexity uses real-time retrieval. The implication is uncomfortable: a site can dominate ChatGPT citations and barely appear in Claude. Operators measuring share-of-voice across all four major models often discover platform-specific gaps that no single-channel optimization fixes.
LLMO’s measurement gap remains its biggest weakness. Citation frequency does not appear in Google Analytics. AI-referred traffic shows up as direct or unattributed in most attribution systems. Operators triangulate using brand search volume, direct traffic patterns, and dedicated tools like Profound and Peec.ai – but the data is fuzzy enough that finance teams remain skeptical, and most LLMO budgets still sit inside SEO line items rather than as standalone investments.
GEO – Generative Engine Optimization
Generative Engine Optimization is the only one of the three frameworks with a peer-reviewed origin. The Aggarwal et al. paper introduced GEO as the first formal paradigm for optimizing content visibility in generative engine responses. Generative engines, in the paper’s definition, are systems that synthesize answers from live retrieved sources rather than from pre-training alone – Perplexity, Google AI Overviews, Bing’s Copilot, and the retrieval-augmented modes of ChatGPT and Claude. The paper’s contribution was empirical: nine specific tactics tested across the GEO-bench benchmark of diverse user queries.
The nine tactics, in order of measured impact, are quotation inclusion, statistics addition, citing sources, simplifying language, adding fluency improvements, easy-to-understand authority signaling, technical terminology where appropriate, keyword stuffing where useful, and unique words. Several tactics produced visibility lifts of 30 to 40 percent on relevant queries; others produced negligible gains. The headline number that traveled – up to 40 percent visibility increase – came from combining the highest-performing tactics on subject-matter pages where the underlying content was already strong.
What separates GEO from generic content advice is the empirical specificity. Quoted statistics outperform paraphrased statistics. Direct citations to authoritative sources, formatted as visible quotation marks rather than buried hyperlinks, increase the probability that a generative engine surfaces the source. Simpler sentence structures get extracted more often than complex ones. The tactics map cleanly to retrieval-augmented generation mechanics: when the engine assembles an answer from retrieved chunks, chunks that contain quotable, attributable, scannable units survive the assembly process intact.
Schema and entity discipline accelerate GEO results without appearing in the original Princeton tactics list. Retrieval systems use embedding-based similarity to find candidate sources, then language models rerank and synthesize. Schema improves the metadata that reranking models see. Entity graphs improve the disambiguation that retrieval systems perform. Sites with comprehensive entity-graph schema implementations consistently outperform sites with identical content but no schema in vendor-reported retrieval tests.
Google’s AI Overviews represent the largest GEO surface in 2026. BrightEdge research from late 2025 found that pages with comprehensive schema markup are three times more likely to appear in AI Overviews. Search Engine Land’s three-site experiment crystallized the stakes: identical pages with well-implemented schema ranked position three and appeared in AI Overviews; pages with poorly implemented schema ranked position eight with no AI Overview appearance; pages with no schema were not indexed at all. The structural finding – that schema may move from optimization to visibility prerequisite – drives most of the 2026 enterprise SEO spending pivot.
Perplexity is the second-largest GEO surface and the most demanding on citation discipline. Perplexity surfaces sources next to its synthesized answers. Users click sources at meaningful rates – Perplexity visitors converting at 3.12 dollars per session per Adobe Analytics data – which means Perplexity citations produce trackable traffic in ways ChatGPT citations rarely do. Sites optimized for Perplexity stack quoted statistics, named expert citations, and clear publication dates. Perplexity’s ranking model penalizes vague claims and rewards specificity ruthlessly.
The 40 percent visibility lift the original GEO paper claimed has held up reasonably well in practitioner testing through 2026. The number is not universal – some content categories see 10 percent gains, others 60 percent – but the median sits near the original benchmark. Sites that invest in generative engine optimization tactics typically report meaningful citation lifts within 60 to 90 days, faster than typical SEO timelines because retrieval engines re-index continuously rather than waiting on Google’s crawl budget.
AEO – Answer Engine Optimization
Answer Engine Optimization positions content for direct extraction into answer surfaces – featured snippets, voice replies, AI Overview answer boxes, ChatGPT direct responses, and Perplexity’s headline answer paragraph. AEO’s optimization target is the answer itself, not the citation that supports it. A site can be cited inside a Perplexity answer without producing the answer’s headline sentence; AEO targets the headline sentence.
The April 2026 inflection point matters because it formalized AEO as a budget category separate from GEO. Before April 2026, AEO existed at the margins, a tactical extension of featured-snippet optimization. The eight agencies launching AEO-as-a-service offerings in April 2026 – covered in Open PR’s industry timeline – converted AEO from a tactic into a service line with standardized deliverables: answer-box audits, direct-extraction content rewrites, schema retrofits, and citation tracking dedicated to answer-position appearances rather than overall mentions.
The tactical core of AEO is direct-extraction formatting. Featured snippets in the 2017-2022 era taught marketers that 40-to-60-word direct answers, placed immediately after the question, won extraction. The 2026 AEO version applied the same lesson to AI surfaces. Question phrased as the user phrases it. Answer in the first sentence. Supporting context in the next two to three sentences. Total answer block under 80 words. The pattern recurs across ChatGPT, Perplexity, Google AI Overviews, Alexa, and Siri. Content engineered to fit the pattern gets extracted at meaningfully higher rates than identical information buried in flowing prose.
FAQPage schema is the highest-leverage AEO investment. Practitioner testing reported by frase.io and circulated through SEO Twitter in late 2025 put FAQPage citation rates near 67 percent on queries where structured Q-and-A content existed. Pages with FAQPage schema appear in AI Overviews, ChatGPT outputs, and Perplexity answers at substantially higher rates than equivalent unstructured content. The mechanism is mechanical: AI assistants render answers in question-and-answer format, and content already structured that way is cheaper to extract verbatim than reconstructed prose.
DefinedTerm schema pairs naturally with FAQPage for AEO. When a user asks “what is TCPA,” “what is CPL,” or “what is ping/post,” the answer engine looks for content that has already declared a clean definition. DefinedTerm schema exposes that definition explicitly. Sites with comprehensive jargon glossaries – particularly in compliance-heavy verticals like insurance, healthcare, and financial services – dominate definitional queries when their schema declares the definitions formally rather than burying them in body text.
HowTo schema wins step-extraction queries that AEO uniquely captures. When users ask “how do I get a TCPA-compliant consent form,” “how do I score a lead,” or “how do I set up boberdoo,” answer engines pull step-by-step responses. HowTo schema declares those steps explicitly. Sites with proper HowTo implementation produce richer answer-surface appearances than sites with identical instructional content in unstructured paragraphs.
The measurement problem for AEO is that direct extraction often produces zero-click outcomes. The user gets the answer; the site gets credit only if the answer surface displays the source. Google’s AI Overviews show source attribution prominently. ChatGPT shows source attribution only when browsing is on or when the user clicks the citations icon. Voice assistants show no attribution at all. AEO measurement therefore depends heavily on share-of-voice tooling – Profound, Peec.ai, Ahrefs Brand Radar, and BrightEdge’s LLMO modules – that survey AI surfaces directly rather than waiting for traffic to land.
The schema layer that ties them together
The schema stack that powers all three layers is more uniform than the optimization tactics suggest. LLMO, GEO, and AEO converge on a five-schema pattern: Article plus FAQPage plus BreadcrumbList plus DefinedTerm plus HowTo, anchored by Organization on the site root and Person for every author. The five-stack delivers compounding citation lift because each schema type addresses a different extraction pattern.
Article schema with comprehensive author and publication metadata is the foundation. Date published, date modified, author with linked Person schema, publisher with linked Organization schema, and headline that exactly matches the H1. AI systems use Article schema to verify provenance – when the answer engine cites a claim, it pulls publication date and author from Article schema rather than parsing the visible page.
FAQPage schema produces the largest single citation lift in vendor-published tests. The 67 percent rate that frase.io’s testing surfaced applies specifically to queries where structured Q-and-A content exists and matches the user’s phrasing. Sites that implement FAQPage schema across every relevant page, with questions phrased the way users phrase them and answers structured as 40-to-60-word direct responses, produce dramatically higher AI surface coverage than sites with the same information in unstructured form.
BreadcrumbList schema provides hierarchy that retrieval engines use for topic disambiguation. When Perplexity decides whether to surface a page about “auto insurance leads,” BreadcrumbList markup confirming Home > Verticals > Insurance > Auto matters more than the raw URL path. Sites with deep hierarchies and complete BreadcrumbList markup outperform sites with identical content but flat or missing breadcrumbs.
DefinedTerm and HowTo are the schemas most operators skip and most LLMO consultants recommend implementing first. DefinedTerm declares industry jargon – TCPA, ping/post, CPL, PEWC, CASL – as named concepts with explicit definitions. HowTo declares procedural content as numbered steps. Both schemas correspond directly to common AI query patterns (“define X,” “how do I X”) that the standard Article-plus-FAQ stack underserves.
The compound effect is the part most operators underestimate. Pages with Article alone produce a baseline citation rate. Pages with Article plus FAQPage produce roughly 50 percent more citations in vendor-reported tests. Pages with the full five-stack roughly double the baseline. The lift is non-linear because each schema type unlocks a different query category – and queries cluster around the schema patterns operators have already implemented.
| Schema | Primary AI surface | Citation lift over Article-only baseline |
|---|---|---|
| Article alone | All surfaces (baseline) | 1.0x |
| Article + BreadcrumbList | Perplexity, AI Overviews | 1.2x |
| Article + FAQPage | ChatGPT, AI Overviews, voice | 1.5x |
| Article + FAQPage + DefinedTerm | Definitional queries across all surfaces | 1.7x |
| Full five-stack (+ HowTo) | All extraction patterns | 2.0x |
Source: Practitioner testing aggregated from frase.io, BrightEdge, and Schema App vendor case studies, 2025-2026. Lift varies by content category and query distribution.
The implementation discipline matters as much as the schema selection. Schema App CEO Martha van Berkel describes schema as “translating your content into Schema.org and defining the relationships between pages and entities to build a data layer for AI.” That data-layer framing captures why partial implementations underperform. A site that implements Article schema but leaves Organization schema malformed produces ambiguous provenance signals. A site that implements FAQPage schema but lets the visible content drift away from the schema content gets penalized for inconsistency. The discipline that produces the doubling effect is end-to-end consistency, not schema breadth alone.
The entity graph and Wikidata sameAs
Schema markup tells AI systems what content claims. Entity graphs tell AI systems what content is. The distinction matters because language models reason about entities, not pages. A page about “ActiveProspect” and a page about “TrustedForm” describe the same parent organization. AI systems that recognize this connection treat both pages as supporting evidence for the same entity. Systems that miss the connection treat them as unrelated noise.
The Wikidata sameAs pattern is the canonical mechanism for declaring entity identity across the web. Wikidata maintains structured records for organizations, people, products, and concepts, each identified by a Q-number. Q-numbers are stable, language-independent identifiers – Wikidata’s Q95 is Google, regardless of what locale or language renders the page. Sites that include Wikidata Q-number URLs in sameAs properties give AI systems an unambiguous anchor for entity disambiguation.
The pattern matters most for organizations with common names or substantial entity overlap. A lead generation company named Apex appears in dozens of unrelated business categories. Wikidata sameAs links collapse the ambiguity. The same pattern applies to people – a founder named John Smith appears across countless industries; LinkedIn URL, Crunchbase URL, and Wikidata Q-number in the Person schema’s sameAs array distinguish the specific John Smith authoring a specific article from the thousands of others.
Google’s Knowledge Graph contains over 500 billion facts structured as RDF triples, with Wikidata as one of its primary upstream sources. AI systems trained on web crawls inherit Wikidata’s entity model implicitly. Sites that align their schema with Wikidata identifiers get the benefit of two decades of curated entity work. Sites that ignore Wikidata produce schema that AI systems must disambiguate from scratch – slower, less reliable, and prone to entity confusion that depresses citation confidence.
The strategic implication is unintuitive: investing in Wikidata presence for an organization or its key people often produces more LLMO and GEO lift than another quarter of content production. A founder with a Wikidata entry, linked from the Person schema sameAs array, gets cited more reliably across ChatGPT and Perplexity than the same founder with no Wikidata presence. The asymmetry exists because entity confidence multiplies all downstream citation decisions. AI systems cite confidently disambiguated sources at substantially higher rates than ambiguous ones.
The implementation work is unglamorous. Audit organizational and personnel presence across LinkedIn, Crunchbase, Wikipedia, Wikidata, GitHub, conference databases, and trade press. Identify the canonical Wikidata Q-numbers that already exist. Create entries for organizations and people that meet Wikidata’s notability bar but lack records. Add Q-number URLs to schema sameAs arrays. Maintain consistency between Wikidata records and on-site descriptions. The work compounds over months rather than weeks, but it produces durable AI citation lift that no amount of on-page optimization replicates.
Vertical playbook – lead-gen, ecommerce, SaaS
The three-layer framework applies to every vertical that competes for organic visibility, but the layer weighting differs sharply by business model. Lead generation, ecommerce, and SaaS approach LLMO, GEO, and AEO with different priorities because their conversion mechanics reward different surfaces.
Lead generation prioritizes GEO and AEO over LLMO. The reasoning is conversion-side. Lead-gen buyers ask AI assistants high-intent vertical queries – “best Medicare advantage leads,” “auto insurance lead vendors,” “TCPA-compliant lead provider” – and expect actionable answers. Perplexity citations and Google AI Overview appearances drive attributable traffic; ChatGPT mentions without browsing produce brand awareness but minimal direct conversion. The pattern across leading lead-gen sites in 2026 is heavy investment in FAQPage and DefinedTerm schema across vertical landing pages, comprehensive HowTo schema for the parts of the funnel buyers actually research, and Wikidata sameAs links for compliance frameworks like TCPA, CASL, and state-level mini-TCPA acts. The LLMO playbook for lead generation emphasizes Perplexity and AI Overview share-of-voice over ChatGPT mention counts.
Ecommerce prioritizes AEO above the other two layers. Shopping queries – “best running shoes under 100 dollars,” “compare iPhone 16 cases,” “is product X waterproof” – produce direct extraction from AI surfaces at high rates. Product schema, AggregateRating schema, FAQPage schema for product pages, and HowTo schema for use-case content drive most ecommerce AI visibility. Bazaarvoice case studies and Klaviyo’s commerce reporting show that ecommerce sites with comprehensive Product-plus-FAQPage stacks see substantially higher AI Overview product card appearances than sites with Product schema alone. Agentic commerce tooling – covered in agentic commerce coverage of AI agents – adds another extraction layer that rewards the same schema discipline.
SaaS prioritizes LLMO over GEO and AEO because SaaS buying cycles run long and rely on brand recall. A buyer evaluating CRM platforms will ask ChatGPT for recommendations weeks before clicking a vendor link. SaaS LLMO depends on consistent entity representation across G2, Capterra, Crunchbase, and Wikipedia, comprehensive Person schema for founders and key executives, and content depth that survives extraction across long-form research queries. The SaaS pattern emphasizes thought leadership content – definitive guides, original research, named frameworks – that AI training pipelines treat as authoritative. Schema App’s enterprise case studies in 2026 show SaaS clients producing 40-plus percent ChatGPT mention growth within two quarters when LLMO investment combines content production with entity graph work.
The cross-vertical lesson is layer prioritization, not exclusion. Every vertical benefits from all three layers. The investment ratio differs. Lead gen runs roughly 50-30-20 across GEO-AEO-LLMO. Ecommerce runs roughly 30-50-20. SaaS runs roughly 30-20-50. The exact ratios are operator-specific, but the pattern holds: pick the layer where your buyer makes decisions and weight investment accordingly, then layer the others on top of the shared schema foundation.
| Vertical | Primary layer | Secondary layer | Tertiary layer | Why |
|---|---|---|---|---|
| Lead generation | GEO | AEO | LLMO | High-intent vertical queries on Perplexity and AI Overviews drive trackable conversions |
| Ecommerce | AEO | LLMO | GEO | Direct-answer extraction on product comparisons drives purchase decisions |
| SaaS | LLMO | GEO | AEO | Long buying cycles reward training-data brand presence over single-query extraction |
| Local services | AEO | GEO | LLMO | Voice and AI Overview answer extraction dominate local intent |
| B2B services | LLMO | GEO | AEO | Multi-touch research patterns reward training-data presence and Perplexity citations |
The framework breaks down at the edges. Hyper-local businesses depend on Google Business Profile signals more than any of the three layers. Pure direct-response advertisers serving short-cycle conversions still rely on paid search. Enterprise sales with named-account motions use AI search as a brand-awareness layer rather than an acquisition channel. Operators evaluating layer investment should start with where buyers make decisions, not with the framework taxonomy.
Measurement – how to tell if any of this is working
Measurement is where most AI search programs fail. Citation frequency does not appear in Google Analytics. AI-referred traffic shows up as direct traffic in most attribution systems. Featured-answer appearances produce zero-click outcomes that traditional dashboards undercount. The mechanical reality is that AI search measurement requires dedicated tooling, and the tooling matured rapidly between 2024 and 2026 – fast enough that the operators who invested early own measurement infrastructure their competitors do not.
Profound dominates the enterprise tier. The platform raised a 96-million-dollar Series C on February 24, 2026 at a billion-dollar valuation, led by Lightspeed Venture Partners with continued participation from Sequoia Capital, Kleiner Perkins, Evantic Capital, Saga VC, and South Park Commons; the round brought total funding to 155 million dollars. Profound’s coverage spans ChatGPT, Claude, Gemini, Perplexity, and Google AI Overviews, with citation tracking, sentiment analysis, and competitive share-of-voice reporting. Pricing starts near 99 dollars monthly for the Starter tier – limited to ChatGPT only – and scales meaningfully for enterprise plans with full multi-platform coverage and content recommendations.
Peec.ai dominates the agency and mid-market tier. The platform serves over 2,000 marketing teams across 80-plus countries and starts pricing near 89 euros monthly. Peec tracks ChatGPT, Perplexity, and Google AI Overviews by default across all paid plans, with Claude, Gemini, Grok, DeepSeek, and Llama available as paid add-ons. The tool’s strength is purpose-built GEO measurement at affordable price points; the limitation is narrower default platform coverage than Profound and less sophisticated competitive intelligence.
Ahrefs Brand Radar entered the market in late 2025 and shifted the competitive landscape immediately. Tim Soulo, Ahrefs’ CMO, published competitive positioning content in March 2026 arguing that Brand Radar maps the full AI funnel across six AI tools with breadth from 210-million-plus search-backed prompts. Pricing combines Ahrefs’ 129-dollar base plan with a 699-dollar Brand Radar add-on for full coverage – meaningfully more expensive than Peec but bundled with the broader Ahrefs SEO toolkit that most agencies already use.
BrightEdge maintains the LLMO module inside its enterprise SEO platform, tracking AI Overview presence, citation frequency, and competitive share-of-voice for clients running BrightEdge as their primary SEO platform. BrightEdge’s strength is integration depth with traditional SEO reporting; the limitation is that AI search reporting sits inside a broader product rather than as a standalone tool. Enterprise clients running BrightEdge get LLMO measurement effectively bundled; smaller operators usually find the standalone tools more cost-effective.
The proxy metrics that work even without dedicated tooling include direct traffic patterns, branded search volume, and unattributed conversion patterns. Direct traffic spikes that correlate with citation event timestamps indicate AI-mediated discovery. Branded search volume increases without paid media or PR spikes suggest AI assistant exposure. Conversion-rate increases on direct traffic compared to organic traffic suggest the 4.4-times-higher AI conversion premium Adobe Analytics documented. Operators triangulating these proxies often arrive at directionally correct conclusions even without standalone tools, though the precision is meaningfully worse.
The measurement gap that no current tool fully closes is multi-touch attribution across AI surfaces. A buyer might encounter a brand in ChatGPT, research it on Perplexity, land via Google AI Overview, and convert through direct traffic. Profound and Peec capture each surface independently. Stitching the journey together requires server-side analytics work that most operators have not built. The 2026 industry consensus is that AI attribution will follow the same maturation arc as paid social attribution did between 2014 and 2018 – fragmented at first, then consolidated through dedicated tooling, then standardized through platform-level reporting.
The honest assessment for operators evaluating measurement spend is that any tooling beats no tooling. A 99-dollar Profound Starter plan or an 89-euro Peec plan produces directional citation visibility that justifies LLMO and GEO investment to finance teams in ways no proxy-only approach achieves. The cost of measurement is meaningfully smaller than the cost of investing in AI search optimization without measurement – which is what most of the industry did between 2023 and 2025, and which is why most LLMO and GEO programs failed to demonstrate ROI internally before tooling matured.
Key Takeaways
-
LLMO, GEO, and AEO solve three different AI-search problems. LLMO targets training-data citation in models like ChatGPT and Claude. GEO targets retrieval-augmented engines like Perplexity and Google AI Overviews. AEO targets direct extraction into answer surfaces. Sites that conflate the three optimize for none of them effectively.
-
The Princeton GEO paper from November 2023 produced the only peer-reviewed framework of the three. Aggarwal et al. demonstrated that nine specific tactics – quotation inclusion, statistics addition, citing sources, and others – can boost generative engine visibility by up to 40 percent. The 40 percent number has held up in practitioner testing through 2026.
-
FAQPage schema produces the highest single citation lift in vendor-published tests. Practitioner testing surfaced through frase.io put FAQPage citation rates near 67 percent on queries with structured Q-and-A content. Pages with FAQPage schema appear in AI Overviews and ChatGPT outputs at substantially higher rates than equivalent unstructured content.
-
The five-schema stack – Article plus FAQPage plus BreadcrumbList plus DefinedTerm plus HowTo – roughly doubles citation rates compared to Article alone. Each schema type unlocks a different query category, and the lift compounds non-linearly.
-
Wikidata sameAs links produce LLMO and GEO lift that on-page optimization cannot replicate. Entity disambiguation through Q-number references gives AI systems unambiguous anchors that multiply citation confidence across all subsequent queries.
-
Vertical layer weighting matters. Lead generation prioritizes GEO and AEO. Ecommerce prioritizes AEO. SaaS prioritizes LLMO. Operators investing across all three layers should weight by where their buyers make decisions, not by framework taxonomy.
-
April 2026 marked AEO’s inflection point as a standalone service category, with eight agencies launching AEO-as-a-service offerings. Direct-extraction formatting – 40-to-60-word answers immediately after questions – drives most AEO citation lift.
-
AI search measurement matured through Profound, Peec.ai, Ahrefs Brand Radar, and BrightEdge LLMO modules between 2024 and 2026. Profound’s 96-million-dollar Series C on February 24, 2026, at a 1-billion-dollar valuation, marked the category’s maturation. Operators without dedicated tooling rely on direct traffic patterns, branded search volume, and unattributed conversion proxies that produce directional but imprecise visibility.
Frequently Asked Questions
What is the difference between LLMO, GEO, and AEO?
LLMO targets citation inside trained models like ChatGPT and Claude that draw on pre-training data. GEO, defined in a November 2023 Princeton paper by Aggarwal et al., targets retrieval-augmented systems like Perplexity and Google AI Overviews that synthesize answers from live sources. AEO targets direct extraction into answer boxes, voice replies, and zero-click panels. The three overlap on schema and entity discipline but diverge on tactics, measurement, and where authority signals matter most.
Where did Generative Engine Optimization come from?
Pranjal Aggarwal and co-authors at Princeton, Georgia Tech, the Allen Institute for AI, and IIT Delhi published GEO: Generative Engine Optimization on arXiv in November 2023 (paper 2311.09735) and presented it at KDD 2024. The paper introduced GEO-bench, a benchmark of diverse user queries, and demonstrated that black-box optimization tactics can boost source visibility by up to 40 percent inside generative engine responses.
Does FAQPage schema actually drive AI citations?
Practitioner testing reported by frase.io and a widely circulated Medium analysis put FAQPage schema citation rates at roughly 67 percent for queries where structured Q-and-A content existed. The mechanism is mechanical, not magical. AI assistants present information in question-and-answer format, and content already structured that way is cheaper to extract verbatim than a paragraph buried in long-form prose.
Should every site implement all three layers?
Most should. The shared infrastructure – Article schema, FAQPage schema, BreadcrumbList, entity graph with Wikidata sameAs links, author bios – covers all three layers at once. Layer-specific tactics diverge. LLMO depends on cross-platform mentions in sources AI vendors actually trained on. GEO depends on quoted statistics, citations, and clean structure that retrieval models reward. AEO depends on direct-extraction formatting like 40-to-60-word answers and explicit Q-and-A blocks.
How is AI search visibility measured in 2026?
Profound, Peec.ai, and Ahrefs Brand Radar dominate citation tracking. Profound raised a 96-million-dollar Series C on February 24, 2026 at a billion-dollar valuation, led by Lightspeed Venture Partners. Peec.ai entry plans start near 89 euros monthly and track ChatGPT, Perplexity, and Google AI Overviews by default, with Claude, Gemini, Grok, DeepSeek, and Llama available as paid add-ons. Ahrefs Brand Radar combines a 129-dollar base plan with a 699-dollar Brand Radar add-on for full coverage. BrightEdge tracks AI Overview presence inside enterprise SEO dashboards. Most operators triangulate at least two tools because no single platform sees every AI surface.
Is AEO just rebranded SEO?
AEO inherits structural tactics from SEO – featured snippets, FAQ blocks, schema – but optimizes for a different end state. SEO ends when the user clicks a blue link. AEO ends when the user receives an answer and never clicks. Open PR coverage in April 2026 marked the inflection point at which AEO transitioned from experimental practice to a formally defined service category, with eight agencies launching AEO-as-a-service offerings.
What schema stack drives the highest citation lift?
The five-stack pattern that recurs across vendor case studies is Article plus FAQPage plus BreadcrumbList plus DefinedTerm plus HowTo, anchored by Organization and Person on every page. Article and BreadcrumbList establish provenance. FAQPage and DefinedTerm give AI extractable answer units. HowTo wins step-extraction queries. Stacking all five with consistent at-id references roughly doubles citation appearance rates compared to Article alone in vendor-published tests.
How does this framework apply to lead generation specifically?
Lead-gen sites that win in AI search treat citation as a top-of-funnel acquisition channel, not a vanity metric. The pattern is to rank for high-intent vertical queries (auto insurance leads, Medicare advantage, solar leads), publish 5,000-plus-word definitive guides with FAQPage and DefinedTerm schema, build entity graphs that link author bios to Wikidata, and measure share-of-voice in ChatGPT and Perplexity instead of organic position alone. The Profound and Peec.ai dashboards make this trackable; most lead buyers do not yet.
Sources
- GEO: Generative Engine Optimization (Aggarwal, Murahari, Rajpurohit, Kalyan, Narasimhan, Deshpande, arXiv 2311.09735, November 2023)
- GEO: Generative Engine Optimization, Proceedings of KDD 2024 (ACM)
- What Is Answer Engine Optimization, Conductor (2026)
- Are FAQ Schemas Important for AI Search, GEO and AEO (Frase.io)
- Answer Engine Optimization Complete AEO Guide 2026 (Frase.io)
- What Is Generative Engine Optimization GEO 2026 Guide (Frase.io)
- What 2025 Revealed About AI Search and the Future of Schema Markup, Schema App
- April 2026 AEO-as-a-Service Inflection Point, Open PR
- Ahrefs Brand Radar Product Page
- Best AI Visibility Monitoring Tools 2026 (AIVO Blog)