The hardest decision in experimentation is not which variant wins – it is which question the test is allowed to answer.
The fundamental trade-off – clean inference versus revenue optimization
Two methodologies dominate online experimentation, and they answer different questions. A/B testing splits traffic evenly across variants for a fixed duration and produces a defensible estimate of which variant performed better and by how much. Multi-armed bandit testing dynamically reallocates traffic toward better-performing variants while the test runs, prioritizing cumulative reward over clean inference. Operators who treat these as interchangeable tools – or as ideological camps – make worse decisions than those who recognize they were designed to solve different problems.
The naming itself comes from a 1952 paper by Herbert Robbins, who formalized what Allied scientists during World War II had already noticed: a gambler facing a row of slot machines – bandits, in casino slang – must decide how to allocate pulls between machines whose payout rates are unknown. According to Peter Whittle, the problem proved so intractable in wartime that researchers half-joked about dropping the problem on Germany so Axis scientists could waste time on it too. Robbins’ contribution was framing the problem statistically as a sequential allocation task rather than a fixed-design experiment, which had been the dominant statistical paradigm since R.A. Fisher’s work in the 1920s and 1930s.
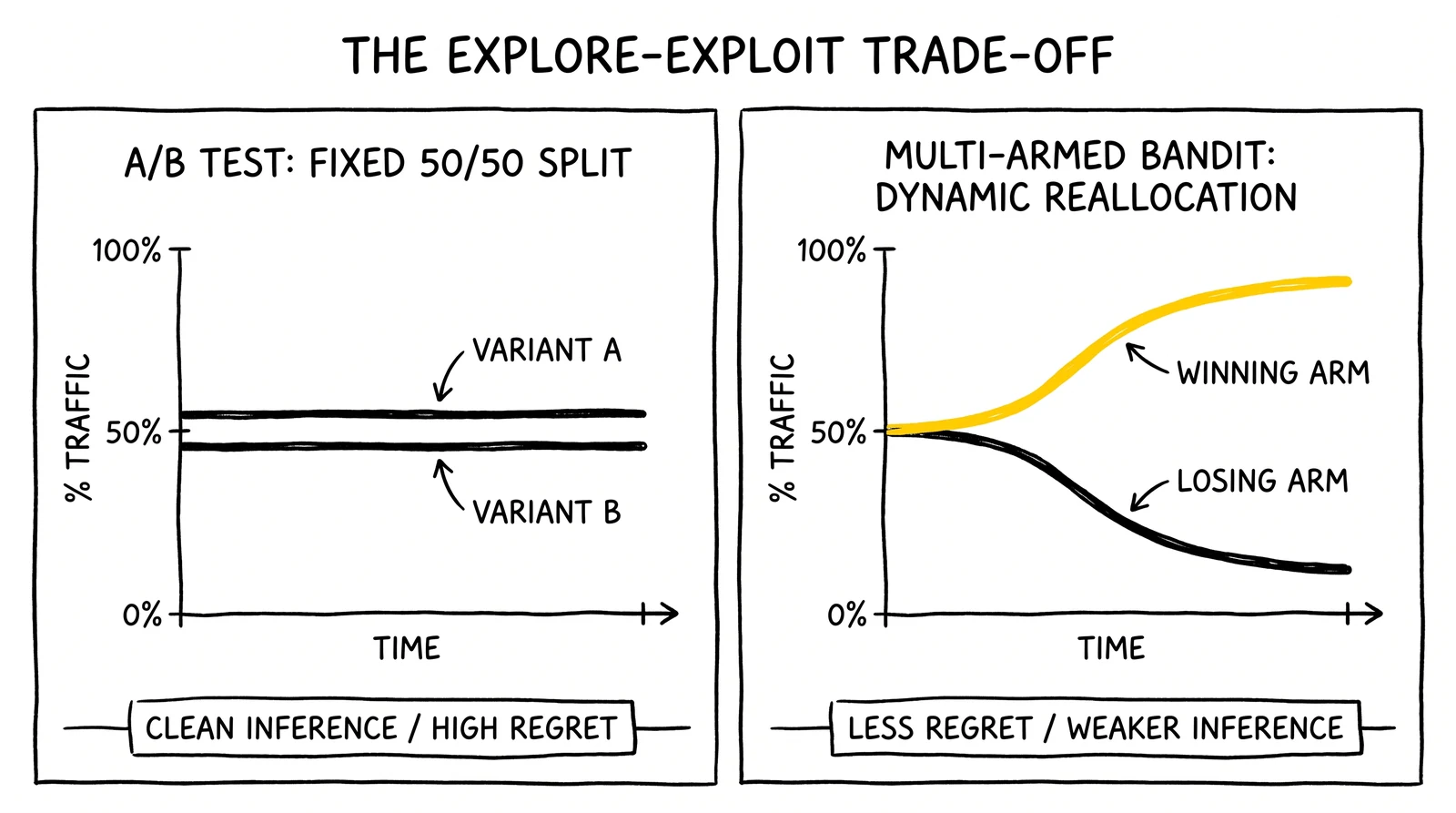
The trade-off Robbins identified has not changed in seven decades. A pure exploration strategy – equal-split A/B testing – produces the cleanest causal estimate but pays a regret cost: every visitor sent to the losing variant during the test represents revenue left on the table. A pure exploitation strategy – always serve the current best – minimizes short-term regret but never learns whether a different variant might be better. Bandit algorithms attempt to balance the two; A/B tests choose exploration explicitly and accept the regret cost in exchange for a defensible answer.
The right question for any operator is not which methodology is better in the abstract. It is which trade-off the current decision can absorb. A pricing change on a checkout page where 30 percent of revenue flows through one variant during the test is a regret-sensitive decision. A long-term redesign that will run for two years is an inference-sensitive decision. The first wants bandits; the second wants A/B tests. Conflating them produces tests that fail to deliver the answer stakeholders actually needed.
A/B testing – the statistical foundation
A/B testing rests on a hypothesis-testing framework Fisher and Neyman-Pearson developed nearly a century ago. Operators define a null hypothesis (the variants are equivalent), choose a significance level (conventionally 5 percent type I error), choose a power level (conventionally 80 percent), specify a minimum detectable effect, and calculate the sample size required before launching the test. The test runs for a fixed duration determined by the sample-size calculation, and at the end, a p-value or confidence interval determines whether the observed difference is statistically distinguishable from zero.
The mathematics behind sample size are unforgiving. Detecting half the effect requires roughly four times the sample size – the relationship is quadratic. An operator who wants to detect a 5 percent lift on a baseline 3 percent conversion rate at 80 percent power and 95 percent confidence needs approximately 30,000 visitors per variant. Halving the minimum detectable effect to 2.5 percent pushes that to roughly 120,000 visitors per variant. Sites with limited traffic – most lead generation operations sit in this category – face a hard constraint: many tests cannot reach statistical power within a commercially reasonable window. The site’s deeper framework on statistical significance for lead generation covers this constraint in detail.
The peeking problem is the failure mode that makes naive A/B testing unreliable. Operators who check results during the test and stop early when a variant looks ahead inflate the false discovery rate from a nominal 5 percent to roughly 30 percent – a six-fold increase in false positives. The temptation is structural: stakeholders ask about results before the test has reached its predetermined sample size, and stopping early when a variant is “winning” feels like good judgment. It is not. Stopping based on observed outcomes is the textbook definition of optional stopping, and the inflated error rate it produces means a meaningful share of declared winners are noise.
Two responses to peeking have emerged. The frequentist response is sequential testing – methods that produce always-valid p-values regardless of when results are checked. Optimizely’s Stats Engine, developed in conjunction with Stanford statisticians, implements sequential testing and false discovery rate controls and reports a reduction in incorrect winner declarations from 30 percent to 5 percent. The Bayesian response is to report posterior probabilities rather than p-values, which intuitively feels immune to peeking. It is not. Recent work by Alex Molas (2025) and others demonstrates that Bayesian A/B testing inflates false positives under optional stopping in essentially the same way frequentist tests do – Bayesian methods are more careful about what they promise, but they do not magically solve the multiple-comparisons problem.
The result is that competent A/B testing in 2026 looks very different from the textbook version. Modern platforms run sequential tests with continuous monitoring, control false discovery rates explicitly when many tests run in parallel, and report effect-size estimates with confidence intervals rather than binary significance verdicts. The methodology is mature; the operational discipline required to use it correctly is still rare.
The bandit algorithm zoo
Bandit algorithms differ in how they balance exploration and exploitation, and the differences matter. Three algorithms dominate production deployments, and a fourth – contextual bandits – represents the leading edge.
Epsilon-Greedy is the simplest. With probability epsilon (commonly 0.1), the algorithm explores by picking a random variant. With probability 1 minus epsilon, it exploits by picking the current best. The exploration rate is a fixed parameter, which is both the strength and the weakness. The algorithm is trivial to implement and reason about, but it explores uniformly even when some variants are clearly inferior – wasting traffic on losers long after their loserness has been established. Epsilon-decreasing variants reduce the exploration rate over time, mitigating but not eliminating the inefficiency.
Upper Confidence Bound (UCB) uses an explicit uncertainty estimate. The algorithm computes a confidence bound around each variant’s estimated reward and serves the variant with the highest upper bound. The intuition is that variants tested less have wider confidence intervals and therefore higher upper bounds, naturally encouraging exploration of uncertain options. UCB is parameter-free in its basic form and provides theoretical regret bounds – UCB1’s expected regret grows logarithmically with the number of trials, which is asymptotically optimal. The downside is that UCB tends to be over-aggressive in exploration during the early phase of a test and computationally heavier than Epsilon-Greedy.
Thompson Sampling has emerged as the dominant production algorithm. The mechanic is Bayesian: the algorithm maintains a probability distribution over each variant’s true conversion rate (typically a Beta distribution updated from observed successes and failures), draws a sample from each distribution, and serves the variant whose sample is highest. Thompson Sampling requires no tuning parameter, naturally allocates more exploration to uncertain variants and less to confidently inferior ones, and tends to outperform Epsilon-Greedy and UCB on real marketing data. The lack of tuning is a significant operational advantage; the cost is computational, since every decision requires sampling from posterior distributions, which adds up at high QPS. Some teams use UCB instead because it delivers approximately 90 percent of the benefit at 10 percent of the computational cost.
Contextual bandits condition variant selection on user features rather than serving the same winner to everyone. LinUCB, introduced by Lihong Li and collaborators in 2010, is the canonical contextual bandit. It models reward as a linear function of context features (device, geography, time of day, prior behavior) and uses an upper confidence bound to balance exploration and exploitation in the feature space. Yahoo’s deployment of LinUCB on the Front Page Today Module – 33 million events – delivered a 12.5 percent click lift over a non-contextual bandit. Contextual bandits are computationally heavier than scalar bandits and require careful feature engineering, but they are the algorithmic backbone of modern personalization at scale.
The table below summarizes the trade-offs operators actually face when choosing among algorithms.
A/B testing versus bandit comparison matrix
| Dimension | A/B Testing (Frequentist) | A/B Testing (Bayesian) | Epsilon-Greedy | UCB | Thompson Sampling | Contextual Bandit (LinUCB) |
|---|---|---|---|---|---|---|
| Primary output | p-value, effect size | Posterior probability | Best variant | Best variant | Best variant | Best variant per context |
| Tuning required | Sample size, MDE | Prior, threshold | Epsilon | Confidence width | None | Feature engineering, regularization |
| Regret behavior | Constant during test | Constant during test | Linear in epsilon | Logarithmic | Logarithmic | Logarithmic in feature space |
| Continuous traffic reallocation | No | No | Yes | Yes | Yes | Yes (per context) |
| Statistical inference | Strong | Strong (with caveats) | Weak | Weak | Weak | Weak |
| Best for | Big-bet decisions | Big-bet decisions | Simple use cases | Stationary problems | Most production cases | Personalization |
| Computational cost | Low | Low | Lowest | Low | Medium | High |
The pattern across deployments is consistent: Thompson Sampling is the default for most production bandit deployments, UCB is chosen when computational cost dominates, Epsilon-Greedy persists in legacy systems, and contextual bandits are reserved for problems where context features genuinely predict reward.
Where bandits beat A/B tests
Five categories of problems favor bandits, and the pattern is consistent: short-lived variants, continuous decisioning, scarce traffic, high regret cost, and cumulative-reward objectives.
Email subject lines and push notifications are the canonical bandit use case. Subject lines have a half-life measured in hours; by the time an A/B test reaches statistical power, the campaign has ended. Bandits handle this naturally – they reallocate traffic to the leading subject line within the first few thousand sends and continue exploring the long tail. The cost of running an equal-split A/B test on a one-day campaign is paid in opens and clicks that the loser variant consumed; bandits minimize that cost by definition.
Display and social ad creative rotation sits in the same category. A retailer running 12 creative variants for a holiday campaign cannot afford to send equal traffic to all 12 for the test duration – by the time statistical power is reached on a 12-arm test, the season is over. Meta’s Advantage+ and Google’s PMax operate as black-box bandits at this layer; the platform never offers an equal-split option, and the practical question for operators becomes how to feed the algorithm enough creatives and signal that its allocation decisions are good ones. The site’s creative testing frameworks for lead-gen ads covers this in operational detail.
Landing page optimization with limited traffic favors bandits when the site cannot generate the volume needed for a fixed-design A/B test within the campaign window. Dolead, the lead generation platform, documented an automation built around the bandit algorithm specifically because their portfolio of campaigns produced too many small tests for traditional A/B testing to be operationally viable. The bandit handled exploration-exploitation across hundreds of landing pages without per-test sample-size calculations.
News headline and content recommendation is a contextual bandit problem at scale. Yahoo’s LinUCB deployment is the academic reference; the production reality is that nearly every major content platform – newspapers, video sites, social feeds – runs some flavor of contextual bandit over headlines, thumbnails, and ranking. The contextualization matters because headline performance varies enormously by user segment; a non-contextual bandit treats all users as identical and underperforms by double-digit percentages versus the contextual version.
Product recommendations and personalization push contextual bandits further. Each user-product pair is effectively its own arm, with contexts numbering in the thousands or millions. The algorithm cannot run a clean A/B test on every pair; it must learn from sparse observations. Bandits, especially LinUCB and its successors, are the only viable approach. The Springer 2023 review of bandits for performance marketing reports parametric bandits gain more conversions on average than the standard alternatives across both synthetic and real-world data.
The unifying logic is that bandits dominate when the cost of exploration during testing exceeds the value of clean inference at the end. If the test will run continuously and the operator never plans to “freeze” the winner, the inference question is moot – what matters is cumulative reward, which is exactly what bandits optimize.
Where A/B testing beats bandits
Five categories favor A/B testing, and the pattern is also consistent: big-bet decisions, regulatory requirements, causal inference for stakeholders, big sample-size requirements that bandits would distort, and tests where the variants will persist long after the experiment ends.
Pricing and packaging changes are the archetypal A/B-only test. A SaaS company changing its pricing tiers needs a defensible answer to how the new pricing affected revenue, churn, and unit economics. A bandit would reallocate traffic toward whichever pricing produced more short-term revenue, but the long-term effect of pricing on churn and LTV requires waiting and observing – the exact behavior bandits are designed to avoid. The decision is also one-time and irreversible, which means the value of a clean effect-size estimate is high and the regret cost during the test is low (the test runs once). A/B testing dominates.
Regulated industries that must document the basis for marketing changes – financial services, healthcare, insurance – face a related constraint. Regulators want to see what was tested, what the effect was, and how confidence in the result was established. A bandit’s traffic allocation changes mid-test, which means the conversion rate observed for any given variant is a confounded estimate of the variant’s true rate plus the algorithm’s behavior – fine for revenue optimization, awkward for documentation. Compliance counsel tends to prefer fixed-design A/B tests with documented power calculations.
Checkout flows and onboarding redesigns sit in the big-bet category. A redesign affects every user for years; the cost of a wrong call compounds. Operators want to see the full experimental data – variance, effect size, confidence interval, segment-level breakdowns – before committing. Bandits suppress this analysis by design; the algorithm shows you the winner without showing you what you would have seen under equal split. For decisions with multi-year consequences, A/B testing’s transparency is worth the regret cost.
Incrementality testing on advertising is a related case. Operators measuring whether a paid channel is incrementally driving conversions need clean holdout groups – a percentage of users who could have seen the ad but were withheld – and a clean comparison of converted-with-treatment versus converted-without. Bandits cannot run this test because they will allocate traffic toward whichever group is converting, breaking the holdout. The site’s incrementality testing guide treats this in detail; the methodology is fundamentally A/B and cannot be replaced with bandits without losing the causal claim.
Tests where stakeholders need to understand the loss rather than only the winner are a final A/B-favored case. Bandit reports tend to look like “Variant B won.” A/B reports look like “Variant B converted 4.2 percent versus 3.8 percent baseline, +10.5 percent lift, 95 percent CI [+4 percent, +17 percent], p = 0.003.” When the marketing team, the engineering team, and the finance team all need to understand the magnitude and confidence of the change before committing to roll it out, the second report is what they need. Bandit dashboards can produce something resembling this, but the underlying data is contaminated by the allocation history in ways the report does not show.
The pattern: A/B testing wins when inference matters more than incremental optimization, when the test is a one-time decision with long consequences, and when stakeholders need a defensible answer rather than a black-box winner.
The platform reality – what operators actually run
Most operators in 2026 do not directly choose between bandits and A/B tests at the algorithm level. They choose a platform, and the platform has already chosen for them. The vendor capability map below summarizes the dominant tools.
Vendor capability map
| Platform | A/B Testing Engine | Bandit Mode | Algorithm | Personalization |
|---|---|---|---|---|
| Optimizely | Stats Engine (sequential, FDR-controlled) | Stats Accelerator | Multi-armed bandit | Optimizely Personalization |
| VWO | Frequentist + Bayesian | Bandit Mode | Thompson sampling + epsilon-greedy hybrid | VWO Personalize |
| AB Tasty | Frequentist | Dynamic Allocation | Thompson sampling | AB Tasty Personalization |
| Adobe Target | Manual A/B | Auto-Allocate | Thompson sampling | Auto-Target (Thompson + Random Forest) |
| Google Ads | Experiments (campaign-level) | Performance Max | Proprietary RL/bandit | Built into PMax |
| Meta Ads | A/B testing (campaign-level) | Advantage+ | Proprietary | Built into Advantage+ |
| Statsig | Frequentist + Bayesian | Multi-armed bandit | Thompson sampling | Targeting rules |
| GrowthBook | Frequentist + Bayesian | Bandits (beta/preview) | Thompson sampling | Feature flags |
Optimizely sits at the inference end of the spectrum. Its Stats Engine is the most academically credentialed sequential testing engine in production, developed with Stanford collaborators. Stats Accelerator, the bandit overlay, is genuinely a bandit implementation but the platform’s center of gravity is rigorous A/B testing. Operators who choose Optimizely typically do so because they want defensible experimental results.
VWO offers both modes explicitly and uses a hybrid Thompson Sampling plus epsilon-greedy approach in its Bandit Mode. The platform documentation describes a content-weight model that handles multivariate cases – the algorithm reasons about how individual variant elements combine, not just which whole-page variant is winning. VWO is one of the few platforms that exposes both methodologies at parity, letting operators choose per-test.
AB Tasty’s Dynamic Allocation is a Thompson Sampling implementation focused on minimizing loss from underperforming variants. The platform positions itself as predictive – claiming to identify winners faster than traditional statistical approaches – and its AI engine handles the optimization without manual intervention. AB Tasty is the type-case of “bandits-as-default” platforms.
Adobe Target offers the most differentiated bandit toolkit. Auto-Allocate runs a Thompson Sampling bandit at the population level – it finds the best non-personalized variant and reallocates traffic toward it. Auto-Target adds personalization: a Random Forest model determines which variant to show each individual visitor, retrained every 24 hours, with Thompson Sampling driving the exploration. This is one of the few production deployments of contextual bandits operators can configure without building their own ML stack.
Google Performance Max and Meta Advantage+ are functionally bandits at the campaign level, even though neither markets the term. Both platforms allocate budget across audiences, placements, and creatives based on conversion probability and reduce operator control to creative inputs and budget envelope. Performance Max analyzes billions of signals in real time – device, location, time of day, search intent, contextual relevance – and routes spend to the highest-probability conversions. The operational consequence is that the methodology debate is moot at this layer; operators get bandit allocation whether they want it or not, and the remaining experimental control sits in account structure (separate PMax campaigns to compare strategies, geographic experiments, holdout markets).
Statsig and GrowthBook represent the modern stack. Both platforms ship frequentist and Bayesian A/B testing engines and bandit modes in the same product, optimized for product teams running hundreds or thousands of experiments per quarter. The architectural pattern is unified: experimentation infrastructure handles both methodologies and operators choose per-test without switching tools.
The lesson for operators is that the methodology choice is downstream of the platform choice. Optimizely operators run A/B-leaning workflows even when they have access to bandits; AB Tasty operators run bandit-leaning workflows even when they have A/B engines available; Google Ads operators run bandits because Google has decided for them. Picking the platform consciously matters more than picking the algorithm.
Lead generation, ecommerce, and B2B SaaS – playbook by vertical
The right methodology choice varies by vertical because traffic volumes, decision horizons, and stakes differ.
Lead generation operations typically have constrained traffic per campaign and a portfolio structure – many landing pages, many creatives, many traffic sources, all running concurrently. The portfolio structure favors bandits at the variant-selection layer (which landing page version, which creative, which form length) and A/B tests at the strategic layer (whether to add a step to the form, whether to swap the entire offer, whether to change pricing). The Dolead case study is representative – bandits handled the dynamic landing-page allocation across hundreds of campaigns, freeing the team to run rigorous A/B tests on the bigger structural questions. Operators running multi-step forms can layer this further; the site’s A/B testing for lead forms and CRO metrics that matter for lead generation frame the decision-by-decision choices.
The economic logic in lead gen is also distinctive: lead generators sell to multiple buyers at different prices, so the cost of showing a losing variant is high – every wasted impression is a lead-purchase opportunity foregone. This pushes bandits further into the default position for tactical optimization. Strategic decisions (which vertical to enter, which buyer mix to chase, which compliance regime to operate under) remain A/B or non-experimental.
Ecommerce operations sit on the high-traffic end of the spectrum. A retailer doing $100 million in annual revenue can typically reach statistical power on most A/B tests within two weeks. The methodology choice is more open: A/B tests are operationally feasible, bandits provide additional optimization. The pattern that has emerged is hybrid – A/B testing for site-wide changes (checkout redesigns, navigation overhauls, pricing changes) and bandits for high-volume tactical decisions (product recommendations, search ranking, email subject lines, banner creative). Adobe Target’s Auto-Allocate and Auto-Target dominate the enterprise side; Statsig and GrowthBook capture the modern direct-to-consumer brands.
B2B SaaS operations are the most A/B-leaning of the three. Traffic is low, decision horizons are long, and stakeholders need to understand effect sizes for go-to-market planning. A pricing-page A/B test in B2B SaaS might run for six weeks to reach power; the team would not accept a bandit’s “Variant B won” in lieu of an effect-size estimate that informs the next year’s revenue plan. Bandits do creep in at the email and ad-creative layer, but the core conversion-funnel testing remains A/B-dominated. Statsig has positioned itself well in this segment by offering rigorous Bayesian A/B testing alongside bandits, letting product teams choose per test.
The vertical-by-vertical pattern reinforces the central principle: choose the methodology to match the question, and choose the platform to make the methodology cheap to run. Operators who try to run A/B tests on bandit-shaped problems waste traffic and miss windows; operators who run bandits on inference-shaped problems ship changes they cannot defend.
Implementation decision framework
The decision framework below collapses to four questions. Operators who answer them honestly tend to converge on the right methodology without prolonged debate.
The first question is whether the test horizon is bounded or continuous. A pricing test that will inform a once-a-year decision is bounded; an email subject line test for a daily campaign is continuous. Bounded tests favor A/B; continuous tests favor bandits. Continuous tests almost always favor bandits because the value of clean inference vanishes when no one will ever look at the final report.
The second question is whether stakeholders need a defensible effect-size estimate. If finance, legal, or product leadership will use the test result to plan revenue, defend a change to regulators, or justify investment, A/B testing is the right choice. If only the marketing team will see the result and the goal is simply to ship the winner, bandits are fine. The presence of cross-functional stakeholders is a strong signal for A/B.
The third question is the variant count and turnover. Two or three variants tested for weeks favor A/B; ten or more variants tested for days or hours favor bandits. The crossover point sits around five variants and one week – beyond that, A/B sample-size requirements compound, and bandits become operationally easier despite their inference weaknesses.
The fourth question is the regret cost during testing. If the difference between variants represents 1 percent of revenue, an equal-split A/B test that runs for two weeks costs roughly 0.5 percent of revenue during the test – usually acceptable. If the difference represents 30 percent of revenue (think aggressive pricing tests, major creative refreshes), the regret cost is unacceptable and bandits are the only viable choice.
Operators who fail this framework tend to fail in one of two ways. The first is treating every test as A/B because A/B is what they learned in school – they accumulate regret on every short-cycle test and miss windows where bandits would have captured most of the upside. The second is treating every test as bandit because their platform defaults to it – they ship changes without understanding the magnitude or confidence of the lift, and discover months later that what looked like a winner was within sample-size noise. The framework above is meant to short-circuit both failure modes.
A final implementation note: the methodologies are not mutually exclusive within a program. Mature experimentation organizations run both – bandits for the high-volume tactical layer, A/B for the strategic layer, and a small number of contextual bandits for personalization. The unifying constraint is operational rigor: documented hypotheses, pre-registered metrics, controlled rollouts, and post-test analysis regardless of which methodology produced the answer.
Key Takeaways
- A/B testing optimizes for clean causal inference; multi-armed bandits optimize for cumulative reward. The methodologies are not interchangeable, and treating them as such produces tests that fail to answer the question stakeholders actually asked.
- Thompson Sampling has emerged as the dominant bandit algorithm because it requires no tuning parameter, allocates exploration intelligently, and tends to outperform Epsilon-Greedy and UCB on real marketing data. Adobe Target, AB Tasty, and VWO all use it as their primary bandit engine.
- The peeking problem inflates A/B testing’s false discovery rate from 5 percent to roughly 30 percent under naive optional stopping. Modern platforms address this with sequential testing (Optimizely Stats Engine) or always-valid Bayesian methods, but neither is automatic – operational discipline is required.
- Contextual bandits like LinUCB are the algorithmic backbone of modern personalization. Yahoo’s Front Page deployment delivered a 12.5 percent click lift over a non-contextual bandit on 33 million events; production deployments at content platforms now span recommendations, search, and ranking.
- Bandits beat A/B tests on email subject lines, push notifications, ad creative rotation, news headlines, product recommendations, and any context where variants are short-lived or traffic is scarce. The unifying logic: when no one will look at a final report, inference is moot.
- A/B testing beats bandits on pricing changes, regulated marketing decisions, checkout redesigns, incrementality testing, and any case where stakeholders need a defensible effect-size estimate. Bandits suppress the analytical detail these decisions require.
- Google Performance Max and Meta Advantage+ are functionally bandits at the campaign level. Operators do not choose methodology at this layer; the platform has chosen for them. Remaining experimental control sits in account structure, geographic experiments, and budget splits.
- The implementation decision framework reduces to four questions: bounded versus continuous horizon, defensible-effect-size requirement, variant count and turnover, and regret cost during testing. Mature programs run both methodologies – bandits for tactical layer, A/B for strategic layer.
Frequently Asked Questions
What is the core difference between A/B testing and multi-armed bandit testing?
A/B testing splits traffic evenly across variants for a fixed duration to deliver a clean causal estimate of which variant won. Multi-armed bandit testing dynamically reallocates traffic toward better-performing variants during the test, optimizing cumulative reward rather than producing a clean inference. A/B testing answers which variant is statistically better; bandits maximize revenue while learning.
When do multi-armed bandits beat A/B testing?
Bandits beat A/B testing when traffic is scarce, the cost of showing the loser is high, the test must run continuously, the variants are short-lived (creative rotation, news headlines, email subject lines), or the operator cares more about cumulative outcomes than a clean p-value. Empirical studies show bandits typically reduce regret 30 to 60 percent versus equal-split A/B tests on stationary problems.
When does A/B testing still win?
A/B testing wins for big-bet decisions where causal inference matters more than incremental optimization: regulated industries requiring documented effect sizes, pricing changes, checkout redesigns, large infrastructure swaps, and any test where stakeholders need a defensible answer to which variant won and by how much. Bandits make this question harder to answer because traffic allocation is correlated with outcome history.
What is Thompson Sampling and why is it the dominant bandit algorithm?
Thompson Sampling maintains a probability distribution over each variant’s true conversion rate, samples from each distribution, and serves the variant with the highest sampled value. It requires no tuning parameter, naturally explores uncertain variants more, and tends to outperform Epsilon-Greedy and UCB on real marketing data. Adobe Target, AB Tasty, and VWO all use Thompson Sampling as their default bandit engine.
What is a contextual bandit and how does it differ from a standard bandit?
A contextual bandit conditions its variant selection on user features (device, geography, time of day, prior behavior) rather than serving the same winner to everyone. LinUCB, the canonical contextual bandit, models reward as a linear function of context features. Yahoo’s Front Page deployment of LinUCB delivered a 12.5 percent click lift over a non-contextual bandit on 33 million events. Contextual bandits are the algorithmic backbone of modern personalization.
How does Optimizely Stats Engine handle the peeking problem?
Optimizely Stats Engine uses sequential testing with always-valid p-values that remain statistically valid regardless of when results are checked. It also applies false discovery rate controls. The engine reduces the chance of incorrectly declaring a winner from approximately 30 percent under naive peeking to 5 percent without sacrificing decision speed, allowing operators to monitor results continuously without inflating type I error.
Are Google Performance Max and Meta Advantage+ multi-armed bandits?
Functionally yes. Both platforms use machine learning to allocate budget across audiences, placements, and creatives based on conversion probability – the same exploration-exploitation trade-off that defines bandit problems. Operators do not directly choose between A/B testing and bandits at the campaign level on PMax or Advantage+; the platform has already chosen bandit-style allocation. The remaining experimental control sits in account structure, budget splits, and Google’s experiments framework.
What is the implementation decision framework for choosing between methodologies?
Choose A/B testing when the test is a one-time strategic decision, the variant pool is small (two or three), causal inference is required for stakeholders, and traffic is sufficient to reach statistical power within a reasonable window. Choose bandits when variants are numerous, short-lived, or continuously refreshed, traffic is constrained, the cost of underperformance during testing is high, and the operator cares about cumulative outcomes more than a clean effect-size estimate.
Sources
- Multi-armed bandit – Wikipedia (history and Robbins 1952 formulation)
- A Contextual-Bandit Approach to Personalized News Article Recommendation – Li, Chu, Langford, Schapire (2010)
- Optimizely Stats Engine whitepaper – sequential testing and false discovery rate controls
- Understanding the Working of Multi-Armed Bandit in VWO – Thompson sampling and epsilon-greedy hybrid
- AB Tasty Dynamic Allocation – Thompson algorithm implementation
- Adobe Target Auto-Allocate – Thompson Sampling for traffic allocation
- Adobe Target Auto-Target – Random Forest plus Thompson Sampling for personalization
- Bayesian A/B testing is not immune to peeking – Alex Molas (2025)
- Multi-armed bandits for performance marketing – Springer International Journal of Data Science and Analytics (2023)
- Dolead – Multi-armed Bandit landing-page automation case study