Schema markup spent its first decade earning star ratings; it will spend its second decade deciding which brands AI systems can name.
The 14-Year Evolution from Rich Snippets to AI Infrastructure
Schema.org launched on June 2, 2011, when Google, Bing, and Yahoo announced a joint vocabulary for structured data on the web. Yandex joined five months later, making the alliance the closest thing the search industry has ever produced to a standards body. The initial pitch was modest: webmasters mark up products, reviews, recipes, and events; search engines render richer SERP results in return. By 2024, the Schema.org vocabulary had been adopted by more than 45 million domains, marking up over 450 billion objects.
For most of the first decade, the return on that markup was straightforward and tactical. Food Network reported a 35% increase in website visits after enabling schema-driven search features. Rotten Tomatoes saw 25% higher click-through rates on pages with schema markup compared to those without. FAQ accordions, star ratings, and product cards earned measurable lift in click-through rates, and SEO teams treated structured data as one optimization among many – useful, sometimes mandatory for specific verticals, rarely existential.
That framing collapsed in 2024 when Google AI Overviews moved from limited Search Generative Experience tests to general availability across the United States. The same vocabulary that produced rich snippets started producing something far more consequential: machine-readable signals that AI systems use to decide whose content to cite in synthesized answers. Pages without structured data still rank in classical search results – for now. Industry research from BrightEdge and others suggests pages without structured data appear substantially less often in the AI-generated summaries that increasingly sit above those classical results.
The shift was foreshadowed by a quieter trend that operators only noticed in retrospect. Common Crawl – the nonprofit web archive that supplies the bulk of training data for GPT-3, GPT-4, LLaMA, Claude, Mistral, and most other foundation models – preserves JSON-LD blocks intact when it captures pages. When AI labs filter Common Crawl snapshots into pretraining corpora, structured data serves as both a quality signal and a grounding mechanism. A page that asserts entity identity through @type and sameAs properties enters the corpus with disambiguation already attached. Unstructured text requires the model to infer those connections at training time, and inference at scale produces hallucinations.
The economic argument has flipped accordingly. Schema markup is no longer a tactical optimization aimed at click-through rates. It is the data layer that determines whether a brand exists in the world that AI systems perceive. The companies that internalized this earliest – Schema App, BrightEdge, Yext, and a handful of in-house teams at large publishers – moved from treating structured data as marketing operations work to treating it as data engineering work. The reframing shows up in budgets, ownership, and outcomes.
Why JSON-LD Won the Format War
Schema.org technically supports three carrier formats: Microdata, RDFa, and JSON-LD. All three encode the same underlying vocabulary. All three remain valid for Google’s consumption. Only one became the standard, and the reasons are operational rather than theoretical.
Microdata, introduced in HTML5, embeds structured data directly into HTML attributes. A product page expresses its price by adding itemprop="price" to a span tag, and the structured representation lives interleaved with the visible markup. RDFa works similarly, using a slightly different attribute syntax inherited from RDF traditions. Both approaches couple structured data tightly to the visible DOM. Templates change, attributes get lost, redesigns silently break entire schema implementations.
JSON-LD takes the opposite approach. Structured data lives in a single <script type="application/ld+json"> block, typically in the page head, completely independent of visible HTML. The block can be generated server-side from any data source, injected via tag managers (with caveats), or rendered statically at build time. When a CMS team rebuilds a template, the JSON-LD block survives untouched. When marketing operations adds a new schema type, no front-end developer has to touch a Handlebars partial.
Google made its preference explicit. The official Google Search Central documentation states that Google recommends JSON-LD for structured data because it is the easiest format to implement and maintain at scale. The recommendation has held consistently from 2017 through current 2026 guidance. Bing, DuckDuckGo, and AI crawlers including GPTBot, ClaudeBot, and PerplexityBot all parse JSON-LD reliably. Microdata still works, but it works under conditions that increasingly fail.
The format choice has second-order consequences for AI visibility. JSON-LD’s separation from visible HTML makes it easier to maintain @id consistency across pages – the mechanism that allows AI systems to recognize that the CEO mentioned in a press release is the same person authoring blog posts and listed on the team page. Microdata implementations rarely maintain @id discipline because the developer cost of doing so is higher. JSON-LD makes entity continuity cheap, which makes knowledge graph construction practical at the scale most marketing organizations actually operate at.
The tooling ecosystem followed the format. Yoast SEO, Rank Math, Schema App, and every modern CMS plugin generates JSON-LD by default. Headless platforms like Contentful and Sanity emit JSON-LD through serialization helpers. Static site generators including Astro, Next.js, and Hugo support JSON-LD as a first-class output. Operators evaluating schema implementation in 2026 face essentially no rational case for Microdata or RDFa unless they inherit a legacy implementation that already works. The hands-on JSON-LD deployment patterns – Organization, Article, FAQPage, Service, and @id referencing – are detailed in the schema markup implementation guide.
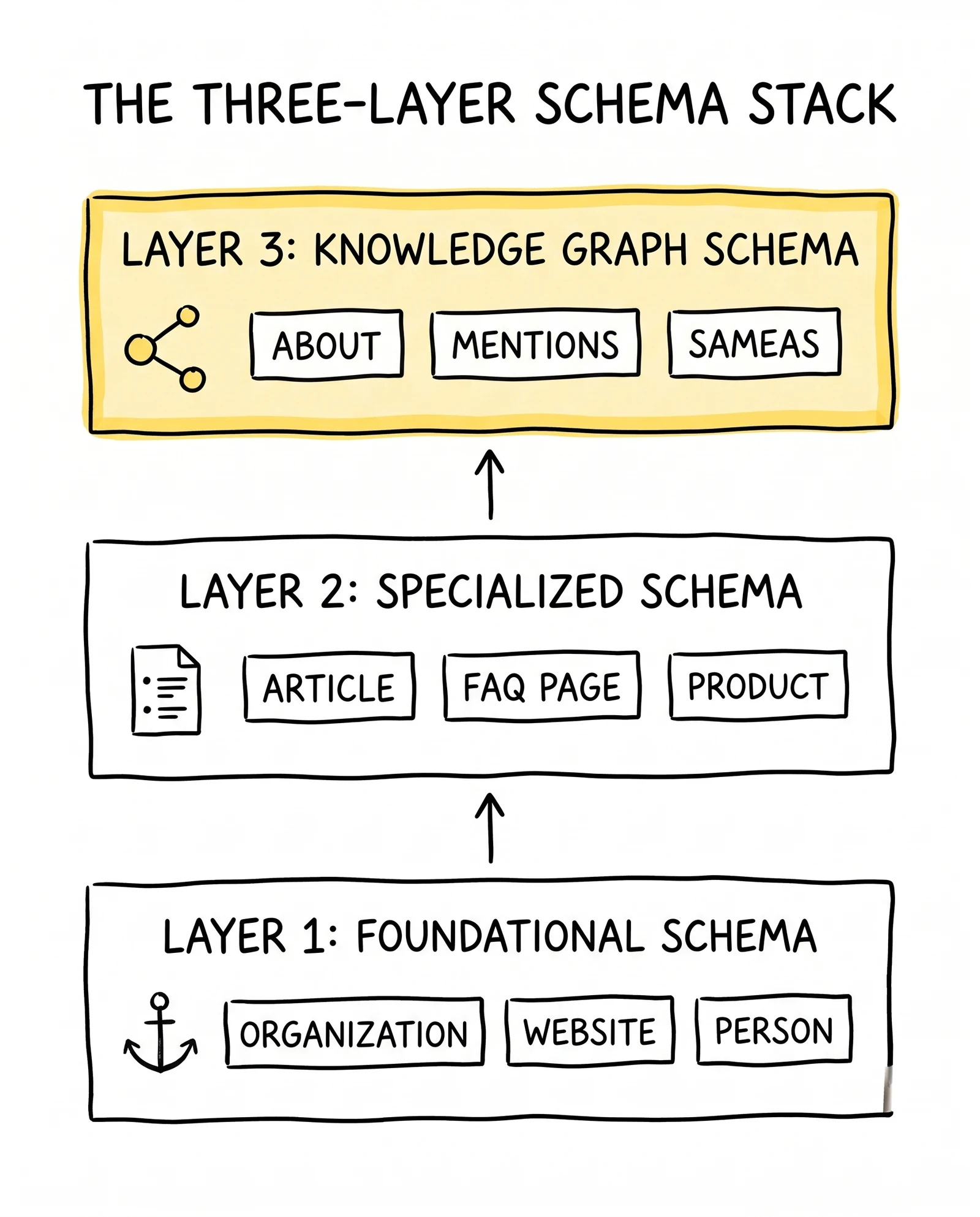
The Three-Layer Schema Stack
Effective schema implementation in the AI era follows a three-layer architecture rather than a flat catalog of types. Each layer serves a different purpose and addresses a different audience among the machines reading the markup.
Layer 1 – Foundational schema establishes site-wide identity. Organization or LocalBusiness schema on the homepage with a stable @id, comprehensive sameAs links to LinkedIn, Crunchbase, and (when applicable) Wikipedia and Wikidata. WebSite schema with optional SearchAction. Person schema for the founder or primary author. This layer rarely changes after initial implementation. It functions as the anchor that all other schemas reference, and it is the first thing AI systems retrieve when trying to ground claims about the brand.
Layer 2 – Specialized schema marks up specific content types. Article and BlogPosting on editorial content. Product on commerce pages. Service on offering pages. FAQPage on Q&A sections. HowTo on procedural content. BreadcrumbList on every category page. Each specialized schema type maps to a Google rich result feature and to a question pattern AI systems decompose user prompts into. The specialized layer is where most marketing teams concentrate effort, and it is where most schema mistakes happen – typically because content evolves faster than schema templates.
Layer 3 – Knowledge graph schema describes relationships between entities. The about, mentions, isPartOf, author, publisher, and sameAs properties that connect pages into a coherent semantic web. This layer is where comprehensive schema implementations differentiate from baseline ones. A Product page that asserts only its own name and price exists in isolation. A Product page that connects via about to a topic concept, via manufacturer to the Organization, via mentions to related guide articles, and via sameAs to a category-specific external database creates a network the AI system can traverse.
The layered architecture matters because AI retrieval is graph-shaped, not page-shaped. When a user asks ChatGPT or Perplexity a question, the system decomposes the prompt into entity queries, retrieves candidate sources, and synthesizes an answer from the highest-confidence matches. Pages with foundational identity, specialized content type markup, and explicit relationship properties win that retrieval contest more often than pages with only a single schema type, even when the underlying content is comparable.
The schema stack also dictates ownership inside the organization. Foundational schema belongs to brand and IT. Specialized schema belongs to content operations. Knowledge graph schema belongs to whoever is closest to topic strategy – typically a senior SEO or content strategist with the authority to maintain shared @id patterns across the site. Implementations that fail usually fail because no single role owns the relationship layer, and relationships drift as content scales.
The Five-Schema Citation Lift
Industry research from frase.io, Soar Agency, Am I Cited, and ZipTie has converged on a consistent finding: pages combining specific schema types get cited in AI Overviews and answer engines at roughly twice the rate of pages with a single schema type. The combination that produces the lift is consistent enough to operationalize.
| Schema type | Primary function | AI citation contribution |
|---|---|---|
| Article / BlogPosting | Headline, author, publication date | Establishes content type and authorship; required for most editorial citations |
| FAQPage | Question-answer pairs | Maps directly to AI’s question-decomposition pattern; among the highest single-schema citation rates in vendor-published testing |
| BreadcrumbList | Topical hierarchy | Anchors page within site taxonomy; supports topic-cluster recognition |
| DefinedTerm | Glossary entries, acronyms | Surfaces jargon for definitional queries; underused outside compliance content |
| HowTo | Procedural steps | Captures procedural queries that account for ~12% of AI prompts |
Frase.io’s testing found that FAQPage schema alone drives a 28% to 40% higher citation probability compared to unstructured content, and pages with FAQPage markup are roughly 3.2x more likely to appear in Google AI Overviews than pages without. Vendor-published testing reports FAQPage among the highest single-schema citation rates for relevant queries, though the specific magnitudes vary by methodology and have not been independently replicated. The mechanism is straightforward: large language models construct answers in question-answer format, and pages that already structure content that way require less transformation at retrieval time.
The compound effect comes from coverage. Each schema type maps to a different sub-query AI systems generate when decomposing a user prompt. Article handles “who said this and when.” FAQPage handles “what is the answer to X.” BreadcrumbList handles “where does this fit in the topic.” DefinedTerm handles “what does this term mean.” HowTo handles “how do I do this.” A page with all five schema types serves more sub-queries than a page with only one, and the cumulative retrieval probability compounds.
The lift table below summarizes the citation rate research, with the caveat that all numbers come from studies conducted by SEO platforms with commercial interest in promoting structured data. The directional finding – that schema combinations drive measurably better AI citation rates than isolated schemas – is consistent across independent sources. The exact magnitudes vary by vertical and query type.
| Schema combination | Citation lift vs. unstructured | Source |
|---|---|---|
| Article only | 1.4x baseline | Soar Agency, 2026 |
| FAQPage only | 1.6x baseline (28-40% higher) | frase.io, 2026 |
| Article + FAQPage | 1.8x baseline | Am I Cited, 2026 |
| Article + FAQPage + BreadcrumbList | 2.0x baseline | Soar Agency / Am I Cited, 2026 |
| Five-schema stack | 2.2-2.5x baseline (estimated) | Cross-source synthesis |
The five-schema stack is not a maximalist recommendation. It is a floor for content-heavy sites optimizing for AI retrieval. Operators in commerce add Product and Offer. Operators in lead generation add Service and LocalBusiness. Operators in B2B SaaS add SoftwareApplication and DefinedTerm for glossary content. The principle holds: stack matters more than any single schema type, and coverage of question patterns matters more than perfection within any one type.
A complementary discipline is described in the schema markup AI visibility implementation guide, which covers the technical mechanics of deploying these schemas without breaking page performance.
sameAs and the Wikidata Disambiguation Layer
The single most underused schema property is sameAs. Most implementations populate it with LinkedIn and Crunchbase URLs and stop there. The implementations that drive measurable AI citation gains push further into Wikidata, Wikipedia, and category-specific authoritative databases.
The mechanism deserves precise description. AI systems – both retrieval-time answer engines and pretraining-time corpus filters – operate on entity graphs derived from authoritative sources. Wikidata is the canonical example: it is the structured-data sibling of Wikipedia, every Wikidata entity has a stable Q-identifier (Q-ID), and Google’s Knowledge Graph reads Wikidata as a primary input. When a piece of content asserts sameAs: "https://www.wikidata.org/wiki/Q12345", it is telling the AI system: the entity I am describing is the same entity you already know from your training data.
That linkage solves the disambiguation problem that otherwise plagues entity recognition. “Apple” is a fruit, a record label, a former Beatles holding company, and the world’s most valuable consumer electronics brand. Without disambiguation, an AI system has to infer which Apple is meant from surrounding context, and inference fails at scale. With sameAs: "https://www.wikidata.org/wiki/Q312", the answer engine knows immediately that the page refers to Apple Inc. – the Q-ID for the company specifically.
Operators serious about AI visibility build a Wikidata audit into their schema implementation. The audit involves three steps: identify Wikidata Q-IDs for the organization, key personnel, named products, and core topic concepts; add corresponding sameAs properties to schema across the site; and, for entities notable enough to qualify, create or improve Wikidata entries that lack them. The third step is the highest-leverage and most under-resourced. Wikidata creation requires neutral-tone documentation backed by independent sources, and the time investment pays off across every AI system that ingests Wikidata as a knowledge backbone.
The asymmetry is worth noting. Adding sameAs to existing Wikidata entries costs minutes per page and produces immediate disambiguation benefits. Creating a Wikidata entry for an organization that lacks one costs hours of editing work plus weeks of community review, but produces a permanent anchor in the canonical knowledge base behind Google, ChatGPT, Claude, Perplexity, and every future AI system that uses Wikidata as a grounding source. The investment compounds for years.
The entity graph schema architecture guide walks through the full Wikidata integration workflow, including how to prioritize which entities to anchor and how to maintain consistency between site schema and external knowledge bases.
AI Training vs. AI Retrieval: When Schema Matters for Each
Schema markup influences AI visibility through two distinct mechanisms operating on different timescales. Conflating them produces wasted effort and missed opportunities.
AI training is the offline process by which foundation model labs construct pretraining corpora. Common Crawl snapshots – released roughly every two months – get filtered through quality classifiers, deduplicated, and assembled into datasets that drive multi-month training runs. GPT-4, Claude 3, LLaMA 3, Mistral Large, and similar models all draw from filtered Common Crawl variants. When labs filter the raw crawl, structured data acts as a quality and grounding signal. JSON-LD blocks survive Common Crawl capture intact. Pages with consistent schema across multiple snapshots build entity-level recognition that future model releases inherit.
AI retrieval is the live process by which answer engines fetch current pages to ground responses. Perplexity, ChatGPT Search, Google AI Overviews, You.com, and similar systems index the live web continuously and select sources at query time. Schema influences retrieval through visibility in indexes (the same way it influences classical SEO), through entity disambiguation via sameAs, and through content-type matching where FAQPage and HowTo schema fit certain query patterns better than unstructured prose.
The strategic implication is that schema serves both timescales but the leverage point differs. For training, the priorities are stability over time, comprehensive sameAs coverage to Wikidata, and consistent @id patterns that survive site redesigns. A page whose JSON-LD changed three times in a year contributes less to entity recognition in the next training run than a page whose schema has been stable for two years. For retrieval, the priorities are coverage of question patterns through the five-schema stack, accurate alignment between schema and visible content, and rapid validation of any schema changes through Google Rich Results Test before deployment.
The dual-timescale framing also clarifies why operators should not chase every emerging “AI optimization” tactic. Schema markup demonstrably influences both training-time and retrieval-time AI behavior through documented mechanisms. Many tactics promoted as “GEO best practices” influence neither and exist primarily as content marketing for SEO platforms. A useful filter: if a tactic does not change either what AI crawlers see at retrieval time or what gets preserved in Common Crawl snapshots, its effect on AI visibility is speculative.
The LLMO lead generation guide treats this distinction in detail and provides a citation-rate measurement framework for tracking both training-corpus inclusion and live retrieval citations.
Lead Gen, Ecommerce, and B2B SaaS Schema Playbooks
The five-schema stack is a baseline. Different business models extend it differently, and the extensions matter because vertical-specific schema types map to vertical-specific query patterns.
Lead generation websites – particularly in regulated verticals like insurance, Medicare, solar, mortgage, and home services – face a specific set of AI query patterns. Users ask answer engines about coverage requirements, qualification criteria, regulatory constraints, and pricing structures. Schema priorities for lead gen sites:
- Organization with
sameAsto LinkedIn, BBB, and any state licensing databases - Service schema on each offering page with
serviceType,areaServed, andprovider - LocalBusiness when geographic targeting applies, with consistent NAP (name, address, phone) data
- FAQPage on objection-handling content with TCPA, PEWC, and consent-related questions
- DefinedTerm for compliance acronyms – TCPA, FCC, PEWC, HPPA, MODPA – anchored to
sameAsWikidata Q-IDs for the underlying regulations - Person schema for licensed agents with
jobTitle,worksFor, and (when applicable)hasCredential - Article and BlogPosting on educational content with explicit
aboutproperties pointing to topic concepts
The DefinedTerm and Wikidata-anchored regulation schema is what differentiates compliance-heavy lead gen from generic content sites. AI systems answering questions about TCPA exposure or PEWC requirements ground their answers in the underlying statutes; pages that anchor their schema to those same statutes get cited.
Ecommerce sites face product-discovery and comparison queries. Schema priorities:
- Product with
name,description,brand,offers, andaggregateRating(only when reviews exist) - Offer with
price,priceCurrency,availability, andpriceValidUntil - Review schema on individual review content, never standalone
- BreadcrumbList on category pages with the full hierarchy
- FAQPage on product detail pages with shipping, returns, and compatibility questions
- Organization with
sameAsto social profiles and Trustpilot - VideoObject on pages with product video content
The discipline most ecommerce implementations miss is keeping price and availability in JSON-LD synchronized with what users see. Stale prices in schema produce penalties from Google and degrade citation rates from AI systems that cross-reference visible content.
B2B SaaS sites answer evaluation and how-to queries. Schema priorities:
- SoftwareApplication with
applicationCategory,operatingSystem, andoffers - Organization with comprehensive
sameAsincluding G2, Capterra, Trustpilot, and Crunchbase - Article and BlogPosting on thought-leadership content with
authorreferencing Person schemas - HowTo on documentation and tutorial content
- DefinedTerm on glossary pages – typically the single highest-leverage addition for SaaS sites
- FAQPage on pricing and feature pages
- Person on author bios with
knowsAboutproperties listing expertise areas
SaaS sites with comprehensive DefinedTerm glossaries become reference points for AI systems answering definitional queries in their category, which converts into branded mentions during higher-funnel evaluation queries. The leverage is high relative to the implementation cost.
The generative engine optimization guide covers the broader content strategy questions these schema priorities support, including how to structure pages so the schema-content alignment holds at scale.
Implementation, Validation, and Monitoring
Schema implementation without validation is implementation without results. The discipline that separates production-grade schema from invisible markup is operational rather than conceptual.
Validation pre-deployment. Every schema change should pass three checks before reaching production. Google Rich Results Test confirms eligibility for specific rich result features and shows previews of how the schema will render. Schema.org Validator checks generic Schema.org compliance independent of any search engine and catches issues like incorrect property types or invalid enumeration values. A JSON syntax validator – built into modern editors or available as a command-line tool – catches the trailing commas and unescaped quotes that silently break entire JSON-LD blocks.
Validation post-deployment. Google Search Console’s Enhancements report shows how Google processes schema across the live site and surfaces errors that pre-deployment testing misses. JavaScript timing issues, CDN caching problems, and template logic errors typically appear here first. Production-grade implementations also add a postbuild verification step: a script that fetches rendered HTML after every deploy and confirms JSON-LD blocks parse without errors. This catches the silent failures that occur when build pipelines update without anyone noticing the schema regressed.
Ongoing monitoring. Schema validity degrades over time as templates change, content evolves, and tools get updated. Quarterly audits using a structured-data crawler (Sitebulb, Screaming Frog with custom extraction, or commercial tools like Schema App) identify drift before it affects citation rates. The audit should check four dimensions: syntactic validity (does the JSON parse), Schema.org compliance (do properties match the vocabulary), schema-content alignment (does schema accurately describe visible content), and entity consistency (do @id values stay stable across pages).
Performance considerations. Large JSON-LD blocks add HTML payload and parsing overhead. The mitigation is strategic prioritization. Foundational schema (Organization, primary Article or Product) should render server-side in the initial HTML response. Secondary schema (supplementary FAQs, related entities, breadcrumbs) can render server-side as well – the marginal cost is small for most sites – but should be ordered after critical-path content. Avoid using JavaScript to inject schema after page load; AI crawlers like CCBot and GPTBot do not reliably wait for JavaScript execution before extracting structured data.
Governance. Schema implementations break when no one owns them. The functional pattern that works at scale assigns one role to maintain @id patterns, one role to validate schema in pull requests, and one role to monitor production health. Smaller organizations collapse those roles into a single owner. Larger organizations distribute them but document the ownership map. Without explicit governance, plugin updates and template changes silently break schema, and the team only finds out when AI citations drop.
The llms.txt implementation guide covers the complementary discipline of explicit AI crawler signaling, which works in concert with schema markup to control what AI systems see and how they attribute content.
Key Takeaways
- Schema.org’s 14-year evolution moved structured data from rich snippet tactic to AI infrastructure; industry research from BrightEdge and others suggests pages with comprehensive schema appear in Google AI Overviews substantially more often than pages without, and peer-reviewed work on knowledge-graph-grounded reasoning (arXiv 2502.13247) reports up to 26.5% accuracy gains over chain-of-thought baselines – a measurable hallucination reduction, not the inflated 300% figure repeated in marketing posts.
- JSON-LD won the format war on operational ergonomics: separation from visible HTML, easy server-side generation, stable
@idcontinuity, and explicit Google preference. Microdata and RDFa remain valid but offer no rational case for new implementations. - The three-layer schema stack (foundational identity, specialized content type, knowledge graph relationships) is more useful than a flat schema catalog because each layer serves a different machine audience and a different timescale.
- The five-schema citation lift (Article + FAQPage + BreadcrumbList + DefinedTerm + HowTo) produces roughly 2x AI citation rates compared to single-schema pages, with FAQPage alone driving 28-40% higher citation probability.
- The
sameAsproperty is the most underused high-leverage schema element; linking entities to Wikidata Q-IDs anchors them in the canonical knowledge base behind Google, ChatGPT, Claude, and Perplexity, and the investment compounds across every future AI system that uses Wikidata as a grounding source. - Schema influences both AI training (offline corpus selection in pretraining runs) and AI retrieval (live citation in answer engines); the leverage points differ – stability and Wikidata coverage for training, question-pattern coverage for retrieval – and operators should optimize for both.
- Vertical-specific schema priorities matter: lead gen sites need DefinedTerm for compliance acronyms anchored to regulation Q-IDs; ecommerce needs synchronized Product and Offer data; B2B SaaS needs comprehensive glossary DefinedTerm coverage and SoftwareApplication.
- Implementation discipline is operational, not conceptual: pre-deployment validation through Google Rich Results Test and Schema.org Validator, post-deployment monitoring through Search Console Enhancements, postbuild verification scripts, quarterly audits, explicit ownership.
Sources
- Schema.org – About (Schema.org, 2026)
- Schema.org: Evolution of Structured Data on the Web (R.V. Guha, ACM Queue, 2016)
- Schema.org Wikipedia entry – founding history and adoption statistics (Wikipedia, 2026)
- Intro to How Structured Data Markup Works (Google Search Central, 2026)
- Are FAQ Schemas Important for AI Search, GEO & AEO? (frase.io, 2026)
- Schema Markup for AI Citations: What Matters in 2026 (Soar Agency, 2026)
- FAQPage Schema: The Most Cited Structured Data for AI Answers (Am I Cited, 2026)
- What is Generative Engine Optimization (GEO)? (frase.io, 2026)
- Wikidata Main Page – canonical knowledge base for Google Knowledge Graph (Wikidata, 2026)
- Common Crawl – public web archive used as LLM training corpus (Common Crawl Foundation, 2026)
- Grounding LLM Reasoning with Knowledge Graphs (Amayuelas, Sain, Kaur, Smiley – arXiv 2502.13247, 2025)