Cloudflare moved AI Crawl Control to general availability in August 2025 and used Agents Week 2026 (April 13-17) to consolidate the surface across every plan tier. Cloudflare’s AI Crawl Control launch and product material discloses that publishers are now sending more than one billion HTTP 402 Payment Required responses to AI crawlers every day across its network – the published figure scopes the count to AI-crawler 402 responses, not to all 402s of any kind. For lead-generation publishers running owned-media funnels, the GA event is not a security upgrade. It is a re-pricing of the substrate that connects content production to lead capture.
A Network-Scale Re-Pricing of the AI Crawler Layer
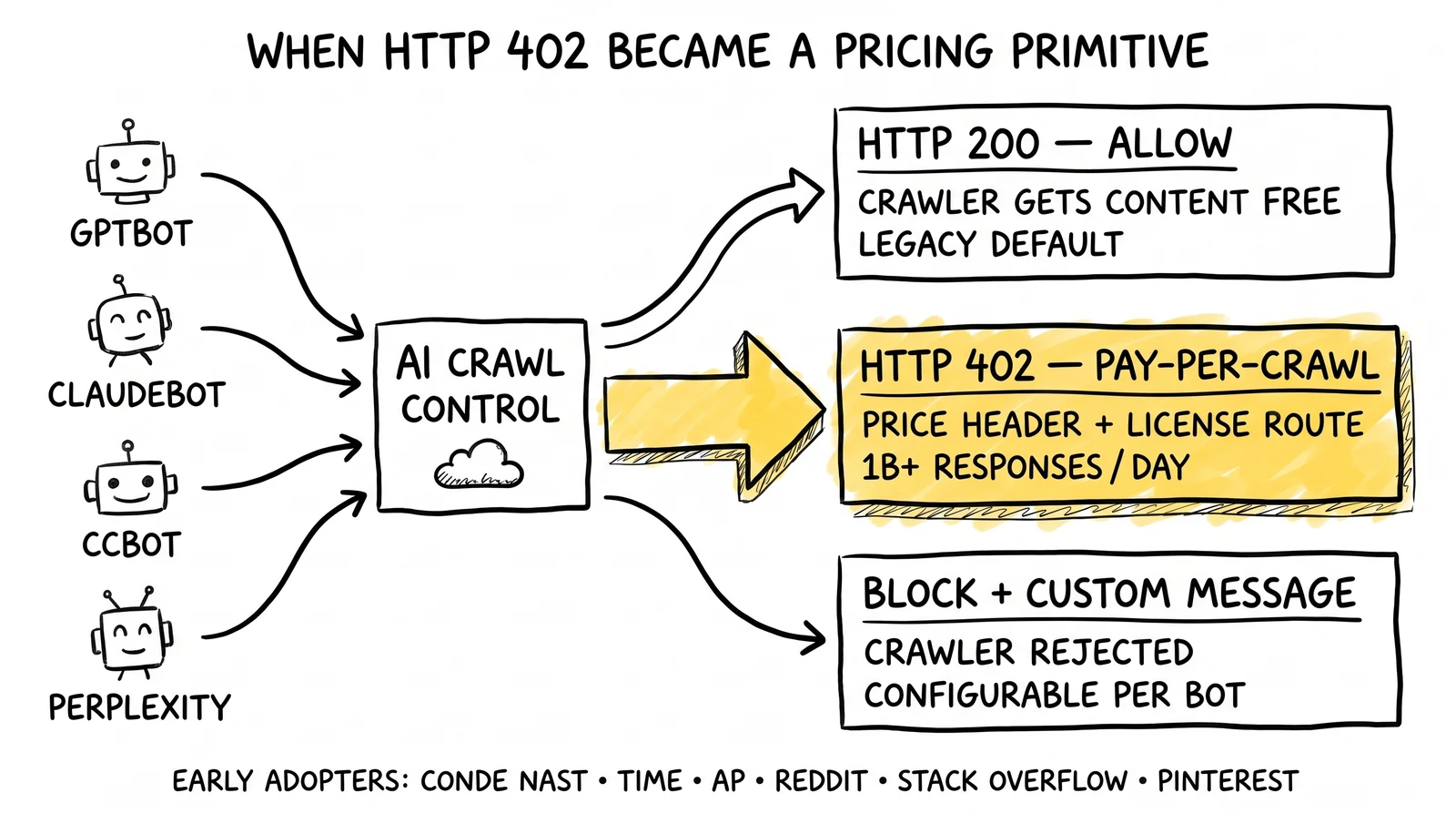
AI Crawl Control reached general availability in August 2025. During Agents Week 2026 (April 13-17), Cloudflare folded the pay-per-crawl framework into a single operator console available across every plan tier. The headline statistic, attributable directly to Cloudflare’s AI Crawl Control launch and developer-docs material rather than to a generic Agents Week recap, is unambiguous: customers across Cloudflare’s network are sending more than one billion HTTP 402 Payment Required responses to AI crawlers per day. The scope of that figure, as published by Cloudflare, is AI-crawler 402 responses across AI Crawl Control deployments – not all 402 responses of any type, and broader than the Pay Per Crawl subset alone. The early adopter list was equally clear: Condé Nast, Time, the Associated Press, BuzzFeed, Reddit, Pinterest, and Stack Overflow had all moved into the program. AI Crawl Control became free on every Cloudflare plan the same week.
For most observers, this read as a publisher-rights story. Major media companies were charging AI labs to access content, the framework had matured, and the long-running argument between scraping and licensing had moved one step closer to resolution. For lead-generation publishers – the operators who run owned-media properties whose entire economic value flows from converting search and social traffic into form-fill leads – the GA event reads differently. It is the first time the marginal cost of an AI crawler request, the marginal value of an AI referral session, and the per-crawler control surface to manage both have been brought into a single operator-controllable layer at network scale.
This analysis covers what changed across August 2025 and Agents Week 2026, why the 402-as-pricing-signal framing matters more than the blocking framing, how lead-gen publishers should think about the crawl-to-refer ratio as a unit economic, and what the next ninety days of operator decisions look like for owned-media lead funnels in light of the consolidation event.
What Changed Across August 2025 and Agents Week 2026 – and Why the 402 Is the Real Story
The headline event was the GA announcement. The actual disruption is more layered.
Cloudflare’s AI Crawl Control existed in beta form for the first half of 2025, originally branded as AI Audit and gradually accumulating the per-crawler verification, robots.txt management, and pay-per-crawl features that defined the GA package. The product reached general availability in August 2025. What the Agents Week 2026 release did was consolidate those features into one operator-facing surface, ship them free across every plan tier, and confirm operationally that the 402 response had moved from a curiosity into a network-scale pricing primitive. According to Cloudflare’s AI Crawl Control launch post and the AI Crawl Control developer docs, the system now produces over one billion 402 responses per day to AI crawlers across the customer base. AI Crawl Control allows publishers to block individual bots with a configurable message and to send 402 Payment Required responses pointing to a licensing page or contact endpoint.
The early-adopter list reinforces what kind of publisher saw the GA framing as commercially significant first. Condé Nast and Time anchor the premium-news end of the cohort. The Associated Press anchors the wire-service tier. BuzzFeed, Reddit, and Pinterest cover the user-generated and social-media tier. Stack Overflow – which published a joint case study with Cloudflare in February 2026 – covers the technical Q&A vertical. Each of those participants chose to issue 402 responses against AI crawlers rather than continue absorbing the bandwidth and content-extraction cost as a fixed overhead.
The price war that did not happen, and the price floor that did
Unlike the credit-bureau price war that played out in seventy-two hours after the FHFA’s April 22 mortgage-credit-score decision, the AI Crawl Control GA event has not produced an immediate visible bidding war among AI labs to pay publisher 402 prices. What it has produced instead is a price floor – the implicit minimum at which content access becomes commercially negotiable. Cloudflare’s framework lets publishers set a flat per-request price domain-wide. The crawler operator then either presents payment intent and receives an HTTP 200, or receives a 402 with the price header and a route to a licensing endpoint. The pricing signal has gone live; the negotiation behavior on the AI-lab side will accumulate over the next two to four quarters.
What matters for lead-gen publishers is not that any specific lab has yet paid a specific price. What matters is that the 402 response has become a standardized communication channel between content producers and AI crawler operators, and that the channel’s volume – over one billion responses per day – is now large enough that no AI lab can credibly ignore it as a fringe behavior. For a lead-generation publisher whose owned-media property feeds a trust-signaled organic funnel, the implication is that content has acquired a directly priceable adjacent revenue stream that did not exist as an operator-controllable lever twelve months ago.
Why the timing aligned with the AI search inflection
The GA announcement landed at a particular moment in the AI-search adoption cycle. Cloudflare’s 2025 Year in Review documented AI bot traffic growing fifteen-fold over the prior year on the user-driven crawler axis specifically, with overall AI and search-crawler traffic up 18 percent comparing May 2024 to May 2025 and 48 percent when including newly onboarded Cloudflare customers. ChatGPT-User – OpenAI’s user-initiated retrieval bot – saw requests surge by 2,825 percent on a comparable period, reaching 1.3 percent of crawler share by mid-2025. Cloudflare Radar’s late-March 2025 data captured Perplexity’s PerplexityBot crawl-to-refer ratio spiking above 700:1, with OpenAI’s ratios reaching as much as 3,700:1 in the same window.
What those numbers describe is an AI-crawl economy that grew faster in twelve months than human web traffic has grown in any comparable period. Against that backdrop, the GA timing is not coincidental. Cloudflare needed a network-scale pricing primitive in operator hands before the AI labs solidified their content-acquisition contracts. Publishers needed a unified operational surface before the next twelve months of AI-search adoption locked in path dependencies. The August 2025 GA, paired with the Agents Week 2026 consolidation, accomplished both, and turned the 402 response from a beta-stage signal into the dominant cross-network message between publishers and AI crawlers.
For lead-generation publishers who built funnels on the assumption that organic search traffic would flow predictably through Google’s crawler-to-clicks pipeline, that assumption is no longer load-bearing. The pipeline now has a parallel branch – AI-search crawler in, AI-search referral out – and the parallel branch has its own pricing layer.
The Three Dimensions of the Lead-Gen Publisher Reset
Beneath the surface of the GA announcement sit three distinct shifts, each of which independently affects the unit economics of an owned-media lead-generation property. Operators who treat the GA event as a single change miss the compound effect.
Dimension one: crawler taxonomy becomes a pricing decision, not a compliance toggle
The first shift is the most direct. Until 2026, most lead-gen publishers ran a single all-or-nothing AI crawler policy: either block GPTBot, ClaudeBot, CCBot, and Google-Extended in robots.txt, or accept all of them. The compliance framing was binary because the operational tooling was binary. AI Crawl Control’s GA package separates that decision across at least nine distinct crawler agents and gives operators the control surface to allow, charge, or block each one independently.
The crawler taxonomy that lead-gen operators now need to internalize splits into two functional categories. The first is the AI-search-and-retrieval category, which includes OAI-SearchBot (OpenAI’s ChatGPT Search indexer), Claude-SearchBot (Anthropic’s search indexer), PerplexityBot (Perplexity’s index crawler), ChatGPT-User (OpenAI’s user-initiated fetcher), Claude-User (Anthropic’s user-initiated fetcher), and Perplexity-User (Perplexity’s real-time retriever). Crawlers in this category exist to bring content into AI-search results that then refer human readers back to the source. Blocking them removes the publisher from AI-search citation eligibility.
The second category is the foundation-model-training category, which includes GPTBot (OpenAI training), ClaudeBot (Anthropic training), CCBot (Common Crawl, which feeds many open training datasets), and Google-Extended (Google’s training opt-out token). Crawlers in this category exist to acquire content for model training. Blocking them removes the publisher’s content from training data sets but does not affect whether the published model surfaces the publisher’s URLs in retrieval. According to Cloudflare’s own blog, OpenAI’s search-crawler coverage grew from 4.7 percent to over 55 percent of sites during the same period its training-crawler coverage dropped from 84 percent to 12 percent – the strongest evidence in the public record that publishers are actively differentiating the two crawler types in robots.txt and access decisions.
For a lead-gen publisher running an AI-visibility schema and entity-graph strategy, the operational implication of the dimension-one shift is that allow-list and price-list decisions now need to be made per-crawler, with explicit reasoning about whether each crawler contributes to AI-search visibility or only to model training. A flat block-everything robots.txt that worked as a defensible default in 2024 is now a structural disadvantage in 2026.
Dimension two: the crawl-to-refer ratio becomes the primary unit economic
The second shift is structural. The metric that lead-gen publishers need to monitor is not AI crawler volume in the abstract, and not AI-referred session volume in the abstract. It is the ratio between the two on a per-crawler basis.
Cloudflare Radar’s 2025 Year in Review made this metric visible for the first time at network scale. Perplexity’s crawl-to-refer ratio spiked above 700:1 in late March 2025, fell back to peak values below 400:1 through the summer, and stabilized below 200:1 from September onward. OpenAI’s ratios hit 3,700:1 at the same March peak. The headline numbers are visceral, and the directional message is unambiguous: in early 2025, certain AI labs were issuing hundreds or thousands of crawl requests per single referral they sent back. By late 2025 and into 2026, those ratios moderated as the AI labs built more retrieval-aware caching layers.
For a lead-gen publisher the ratio is a unit economic, not a vanity stat. If a publisher’s AI-search referral volume is, say, two thousand sessions per month, and the publisher’s PerplexityBot crawl volume against the same site is four hundred thousand requests per month, the ratio is 200:1. If those two thousand sessions convert at a content-to-lead funnel rate consistent with industry benchmarks – say, two percent – the publisher captures forty leads per month from Perplexity-driven traffic. The marginal bandwidth and content-extraction cost of admitting four hundred thousand crawler requests is the unit-economic input that has to be priced against those forty leads.
What changes after AI Crawl Control GA is that the publisher now has the operational lever to set a 402 price on Perplexity that recovers the marginal cost (or any chosen margin layer above marginal cost), without giving up the forty referrals. The framework allows publishers to charge selectively. A publisher whose Perplexity ratio is 200:1 may find that a per-request price of a fraction of a cent recovers cost. A publisher whose ratio is 700:1 needs a larger per-request price or needs to block until the ratio improves. The decision is now operator-controllable rather than externally imposed.
Dimension three: AI-referred session quality is materially different from organic-search session quality
The third shift is the most subtle and the most important. Independent research has established consistently that AI-referred sessions convert at meaningfully higher rates than traditional organic-search sessions. Industry estimates from late 2025 and early 2026 vary in the precise multiple – some place AI-referred conversion at roughly 22 percent above traditional organic, others report AI-search referral converting near 3.49 percent against 2.86 percent for traditional organic, and Conductor’s 2026 AEO/GEO Benchmarks Report tracked 35.7 million AI-driven sessions across 1,215 enterprise domains as part of the broader study. The specific numbers depend on the cohort and the methodology, but the directional message is consistent: an AI-search referral arriving at a publisher’s lead form is a higher-intent visitor than the average organic-search referral.
Why that is the case has a specific causal explanation. AI-search retrieval includes a pre-filter step that traditional organic search does not. The user asked the AI a question; the AI synthesized an answer; the answer cited the publisher’s URL; the user clicked through specifically because they wanted more depth on what the AI already summarized. By the time the visitor arrives at the publisher’s page, the visitor has already been pre-qualified through the AI’s retrieval logic. That pre-qualification is what produces the higher conversion rate observed across studies.
For a lead-gen publisher, the dimension-three implication is that the value of an AI-referred session is materially higher than the value of an organic-search session. A publisher pricing 402 responses needs to set the price low enough that the AI lab continues to crawl and continues to refer, because each refer-back has higher unit economic value than the publisher would otherwise realize from generic organic traffic. The pricing logic is not “extract maximum revenue from the AI crawler” but “set the lowest price that recovers marginal cost while preserving the higher-value referral stream.” That is a different optimization than the publisher-licensing framing that dominated 2024-2025 coverage of the AI-content debate.
The compounding effect across the three dimensions: per-crawler taxonomy decisions allow the publisher to admit the high-referral crawlers cheaply or freely while pricing the high-crawl-to-refer ratio crawlers; crawl-to-refer ratio monitoring quantifies which is which; and the pre-qualified nature of AI-referred traffic ensures that admitting search-and-retrieval bots produces higher per-session economic value than admitting them was producing in 2024.
The Approaches That Will Underperform This Cycle
Three responses to the GA announcement are visible in the early industry chatter. Each will produce worse outcomes than its proponents expect, and the reasons are worth being explicit about.
The first is the block-everything posture. The argument runs that AI crawlers extract content, AI-search referrals are too small to matter, and the cleanest defensive response is to deny all AI access via a comprehensive robots.txt block plus a network-edge rule. The argument was defensible in mid-2024 when AI-referred traffic was a rounding error. It is wrong in 2026 for two reasons. First, AI-search referrals are no longer a rounding error – Conductor’s enterprise tracking captured tens of millions of AI-driven sessions across the publishers in its panel, and the volumes are growing faster than human search. Second, the conversion-rate uplift on AI-referred sessions means that even a small number of admitted referrals carries meaningful funnel value. A lead-gen publisher who blocks OAI-SearchBot, Claude-SearchBot, and PerplexityBot indiscriminately removes the publisher from the citation pool that drives the AI-referred traffic with the highest marginal funnel value. The defensive response is not free; it has a measurable funnel-side cost.
The second is the allow-everything posture. This is the response of operators who interpret AI Crawl Control as too operationally complex to configure thoughtfully and conclude that the right move is to leave robots.txt permissive and absorb the crawl load. The argument was defensible in 2023 when AI crawlers were a small fraction of total bot traffic and bandwidth costs were trivial. It is wrong in 2026 because the crawl-to-refer ratios on the worst-performing crawlers have, by Cloudflare’s own data, hit 700:1 and 3,700:1 at peak. A publisher absorbing all AI-crawler load at zero pricing is paying bandwidth and content-extraction cost for crawler types whose referral economics do not justify free admission. The 402 response framework exists precisely because the all-permissive default produces a margin transfer from publishers to AI labs that the GA tooling now allows publishers to recover.
The third is the static-pricing posture. Some operators read the GA announcement, configure a single domain-wide flat price for AI Crawl Control, and consider the implementation complete. The argument is that one price across all crawlers is operationally simpler and that the pricing signal is what matters more than per-crawler tuning. The argument misses the asymmetry between crawler types. A flat price applied to OAI-SearchBot at the same level as a flat price applied to GPTBot misallocates: it underprices the training crawler, whose economic value to the AI lab is high but whose referral value to the publisher is zero, and it overprices the search crawler, whose economic value to the AI lab includes the value of bringing referrals back to the publisher. A static-pricing publisher leaves margin on the table on both sides – too cheap for training, too expensive for search – and ends up with a configuration that no sophisticated buyer in the market would have chosen for them.
The common pattern across the three approaches is the same: each underestimates the speed at which the AI-search side of the market will repay differentiated handling, and each fails to recognize that the 402-as-pricing-signal architecture is already live regardless of how slowly any specific AI lab responds to it.
The Strategic Reframe: Three Principles for the Re-Priced Owned-Media Funnel
The right response to the AI Crawl Control GA event starts from a different premise. The AI-crawler layer of the lead-gen publisher’s stack is no longer a fixed cost block to be optimized around. It is a variable revenue and cost block to be designed against. Three principles flow from that premise.
Principle one: tier crawlers like ping-post buyers, not like security threats
In the legacy framing, AI crawlers were security or compliance objects: they either complied with robots.txt or they did not, and the response was either to allow or to block. In the re-priced framework, AI crawlers are economic counterparties whose value to the publisher varies by crawler type, by referral track record, and by current crawl-to-refer ratio. The right operational analog is a ping-post buyer waterfall.
In a lead-buyer waterfall, an operator routes leads to buyers in tiers based on bid price, fit, and exclusivity terms. Top-tier buyers receive the highest-value leads at the highest prices. Mid-tier buyers receive the qualified-but-shared inventory. Bottom-tier buyers receive open-marketplace overflow. The same logic applies to AI crawlers. Top-tier crawlers (OAI-SearchBot, Claude-SearchBot, PerplexityBot when the crawl-to-refer ratio is reasonable) receive free or below-cost access in exchange for the referral stream. Mid-tier crawlers (training crawlers from labs that maintain referral-positive search products) receive moderate per-request pricing. Bottom-tier crawlers (training-only with no associated retrieval product) receive cost-recovery pricing or block-list status.
What this requires operationally is per-crawler analytics – request volume, referral volume, conversion rate of referred sessions – and a per-crawler pricing decision framework. AI Crawl Control’s GA package provides the request-volume side. Publisher analytics platforms provide the referral and conversion side. Connecting the two through a unified per-crawler dashboard is the build that captures the principle-one margin.
Principle two: monitor crawl-to-refer ratio as a leading indicator, not a lagging one
The legacy publisher analytics stack monitored organic-search referral as a flow metric and AI-crawler activity as a server-load metric. The two were on different dashboards because they appeared to be different problems. In the re-priced framework, they are the same problem expressed from opposite sides.
The crawl-to-refer ratio, monitored daily and disaggregated per crawler, is a leading indicator of AI-search visibility. A ratio that is rising against a fixed referral baseline means the AI lab is increasing its crawl rate against the publisher’s content without proportionally increasing its citations of that content – a sign of either an indexing rebuild or a deprioritization. A ratio that is falling means the lab is referencing the publisher more efficiently per crawl, which typically correlates with rising citation share. A publisher monitoring the ratio in real time can identify shifts in AI-search visibility before they show up in AI-referred-session counts.
The principle-two operational requirement is a daily per-crawler ratio dashboard with anomaly detection. The principle-two strategic requirement is to treat the dashboard as input to content production: when a specific crawler’s ratio is rising, the publisher’s response is to investigate which content categories the crawler is now hitting more frequently and to ensure those categories are well-structured for citation. The connection between AI search ROI measurement and operational content decisions becomes a tight feedback loop rather than a quarterly retrospective.
Principle three: re-price the content-to-lead funnel against the AI-referred conversion premium
The legacy content-to-lead funnel was tiered against organic-search assumptions. Top-of-funnel content captured search intent broadly, mid-funnel content qualified visitors against vertical fit, and bottom-of-funnel content drove the form-fill conversion. The conversion-rate assumptions baked into the funnel design reflected organic-search behavior – visitors arriving from a SERP, evaluating the page against alternatives in a tabbed browser, making a low-intent comparison decision before any form interaction.
AI-referred visitors arrive at the page in a different state. They have already received an AI-synthesized answer to their question. They are clicking through specifically to validate, deepen, or take action on what the AI summarized. The funnel architecture that captures the highest conversion from this cohort is structurally different: the page should anticipate that the visitor knows the topline answer, present the validating depth quickly, and route to the form-fill or conversational AI lead-qualification interaction faster than the equivalent organic-search visitor would expect.
What this requires operationally is content variants that detect the referral source – the HTTP referer header, AI-search-specific query parameters where present, or the session metadata that AI-search platforms increasingly attach to outbound clicks – and serve a funnel layout calibrated to AI-referred intent. A publisher running a single funnel layout for both organic and AI traffic underperforms a publisher running two variants because the conversion-rate assumptions diverge across the two cohorts. The implementation cost of dual-variant content is non-trivial, but the conversion-rate premium that AI-referred sessions carry is large enough to justify the build for any owned-media property above a minimum traffic threshold.
The combined effect of the three principles is a publisher operation that prices crawlers per their referral economics, monitors crawl-to-refer ratios as leading indicators of visibility, and serves AI-referred visitors a funnel calibrated to their distinct intent profile. None of the three principles is technologically difficult. All three require organizational decisions that most owned-media operations have not made.
Evidence and Early Movers: Reddit, Stack Overflow, and the Publisher Cohort
The decision did not arrive in a vacuum. Three named publisher activities in late 2025 and early 2026 give early evidence about how the market will reprice.
Reddit’s role on the early-adopter list reflects a specific commercial calculus. Reddit has, by multiple research accounts including the Profound study cited across late-2025 SEO trade press, become one of the dominant citation sources in ChatGPT – together with Wikipedia and TechRadar accounting for roughly 22 percent of all ChatGPT citations after OpenAI’s mid-2025 retrieval reweight. Reddit’s pay-per-crawl participation is not about restricting access; it is about establishing that access is a priced good even when the access is currently being granted at a reference price. For lead-gen publishers operating in verticals where Reddit threads compete for the same AI-citation share – particularly consumer finance, home services, and software comparison categories – Reddit’s framework participation is a market-structure signal that the citation pool is becoming a commercially negotiated layer.
Stack Overflow’s joint case study with Cloudflare, published in February 2026, is the most operationally instructive of the early-mover signals. Stack Overflow’s content corpus – Q&A pairs covering software development across two decades – is among the most valuable training data on the open web for code-capable language models. The joint case study explained that Stack Overflow’s pay-per-crawl decision was not framed defensively. The framing was that AI labs that build on Stack Overflow content should pay proportionally to the content’s contribution to model capability, and that the 402 response framework gives Stack Overflow the operator surface to enforce that proportional pricing. For lead-gen publishers in technical or specialty verticals – wherever the published content has unusually high training-data value – the Stack Overflow framing is the template. The 402 price is not a punitive block; it is a proportional value-recovery layer.
The Condé Nast, Time, AP, and BuzzFeed cohort represents the news-publisher template. Their participation reflects a different commercial calculus: AI-search citation share is currently dominated by user-generated and reference content (Reddit, Wikipedia), and traditional news publishers are using the 402 framework to push their content back into the negotiated-licensing track. The longer-term equilibrium for news publishers will look more like the music industry’s licensing structure than the open-web’s citation pattern, and the GA-stage AI Crawl Control framework is the mechanism through which the equilibrium gets negotiated. For lead-gen publishers running owned-media news-adjacent verticals – finance, insurance, mortgage, legal services – the news cohort’s pricing decisions establish the reference rates against which the lead-gen publisher’s own pricing will be benchmarked.
The data-quality consideration most operators are missing
The Cloudflare Radar 2025 Year in Review documented a related metric that has not received proportionate trade-press coverage: by January 2026, Googlebot reached 1.70 times more unique URLs than ClaudeBot, 1.76 times more than GPTBot, 2.99 times more than Meta-ExternalAgent, and 167 times more than PerplexityBot. The implication is that the AI-crawler ecosystem is concentrated by orders of magnitude. A publisher’s per-crawler pricing decisions therefore matter unequally – the GPTBot, ClaudeBot, and Google-Extended decisions affect the bulk of training-crawler traffic, while the OAI-SearchBot, Claude-SearchBot, and PerplexityBot decisions affect the bulk of search-crawler traffic. Operator attention should follow the volume distribution rather than treating all named crawlers as similarly weighted.
What this means in practice is that an operator who configures AI Crawl Control with thoughtful pricing on the four or five highest-volume crawlers and a default policy for the long tail captures most of the available margin. The pareto distribution of crawler volume is the operator’s friend; the configuration cost of full per-crawler tuning across every named user-agent is not justified, and the operator who tries to tune everything underperforms the operator who tunes the critical few.
The broader pattern: the GA event is not a single change but a layered change. Each layer compounds with the others. Operators who model only one layer will systematically understate the opportunity.
Implementation Reality: What It Actually Takes to Capture the Re-Priced Publisher Funnel
The strategic reframe is straightforward. The implementation is not.
Resource requirements
Building a per-crawler pricing and analytics stack against the new framework requires three types of investment that most owned-media operations have not budgeted for. The first is the crawler-analytics integration. AI Crawl Control’s GA console exposes per-crawler request data, but mapping that data against referral analytics – Google Analytics or a server-side analytics layer that captures AI-referred sessions – requires a join across two systems that are not natively connected. For a publisher running on a typical content stack (CMS plus analytics plus Cloudflare), expect twenty to forty engineering days to build the join, the daily ratio dashboard, and the anomaly-detection alerts that make the crawl-to-refer ratio an actionable metric.
The second is the per-crawler pricing decision framework. Setting a 402 price requires operator judgment about marginal cost recovery, target referral preservation, and crawler-specific bargaining position. Most publishers have not defined those parameters explicitly. The decision framework should be documented as an internal policy with named decision-makers, review cadence, and explicit pricing rationale. The build for the framework is operational rather than technical, but the discipline takes longer than expected. Plan for thirty to sixty calendar days of policy work – including stakeholder review across editorial, revenue, and engineering – to land a defensible per-crawler price list.
The third is the funnel-variant infrastructure. Serving a different funnel layout to AI-referred visitors versus organic-search visitors requires either a server-side rendering decision based on the referer header, an edge-side rule in Cloudflare Workers, or a client-side personalization layer. Each approach has tradeoffs. Edge rules are fast and SEO-neutral but require Workers-tier infrastructure. Server-side rendering is durable but slower to iterate. Client-side personalization is iterable but introduces page-load latency that can hurt the very conversion premium the variant is trying to capture. A typical implementation runs forty to eighty engineering days for the edge-rule approach including the variant content production. For owned-media operations that already run structured CRO testing on lead forms, the marginal cost is lower because the variant testing infrastructure is already in place.
Timeline expectations
A realistic implementation timeline for a mid-sized owned-media lead-gen publisher:
| Phase | Duration | Key Activities |
|---|---|---|
| Crawler analytics integration | 20–40 days | Connect AI Crawl Control console data to publisher analytics; build per-crawler ratio dashboard |
| Per-crawler pricing framework | 30–60 days | Define marginal cost recovery, target referral preservation, and pricing tiers; document and approve policy |
| AI Crawl Control configuration | 5–10 days | Set per-crawler allow/charge/block rules; configure 402 response messaging and licensing endpoints |
| Funnel variant build | 40–80 days | Detect AI-referred sessions; serve calibrated funnel variant; A/B test against control |
| Compliance and disclosure review | 10–15 days | Validate that 402 pricing terms, AI-content licensing, and visitor-routing comply with applicable disclosure requirements |
| Total elapsed time | 3–4 months | Conservative estimate for a publisher without prior edge-compute infrastructure |
Source: Composite of Cloudflare AI Crawl Control documentation and analysis of early-adopter implementation patterns
Common obstacles
Three obstacles consistently slow these implementations beyond the nominal timeline. The first is editorial-revenue alignment. The pricing decisions affect editorial reach (because aggressive pricing reduces AI-search citation eligibility) and revenue (because conservative pricing leaves margin on the table). The two stakeholder groups optimize against different metrics, and the alignment process takes longer than the engineering work. Publishers who start the alignment conversation before the engineering work is complete tend to compress the overall timeline.
The second is the referral-analytics gap. Most publisher analytics stacks identify AI-referred sessions through partial heuristics – referer header parsing, query-parameter detection, user-agent inspection – that produce a substantial false-negative rate. A meaningful fraction of AI-search referrals arrive with sparse or absent referer data, and those sessions get classified as direct or organic rather than as AI-referred. Resolving the classification gap requires either platform-specific tagging cooperation from the AI labs (limited as of April 2026) or a fingerprinting approach that combines multiple weak signals into a probabilistic classification. Both approaches produce noisy data, and operators should plan for the noise rather than expect clean classification.
The third is the pricing-tier negotiation with AI labs. The 402 response framework establishes a price floor, but actual transactions between publishers and AI labs at scale will involve direct negotiation. Publishers who treat the 402 price as a take-it-or-leave-it list price are leaving negotiating room unused. Publishers who treat the 402 price as the opening bid in a longer negotiation cycle position themselves for the licensing-deal volume that will accumulate over the next twenty-four months as the AI labs solidify their content-acquisition strategies.
The implementation is hard. The publishers who complete it before the rest of the market reprices will run a six-to-twelve-month structural advantage on both the crawler-revenue and the AI-referral-conversion sides.
Future Implications: The Five-Year Trajectory of Publisher AI Economics
The GA announcement is the first event in a multi-year sequence. The shape of the sequence is reasonably predictable from the structure of the market.
In the next twelve months, the 402-as-pricing-signal volume will continue to grow. Cloudflare’s reported one billion responses per day will likely double or triple as more publishers move into AI Crawl Control configurations and as AI-crawler volume itself continues its 2025 growth trajectory. Expect competing CDN and edge providers – Akamai, Fastly, Imperva – to ship feature parity packages to keep their publisher customers from migrating to Cloudflare for the AI-control surface specifically. Fastly’s existing TollBit integration is the closest current alternative, and the commercial competition will compress the operator-side price of the control framework toward zero.
In the next twenty-four months, AI-lab-to-publisher direct licensing will scale. The 402 response is the negotiation primitive; the licensing deal is the negotiated contract. Expect a handful of marquee deals during 2026 – likely OpenAI-Reuters, Anthropic-Bloomberg, Perplexity-Wall Street Journal or equivalents – that establish per-vertical reference rates. Lead-gen publishers in those verticals will benchmark against the marquee rates. Lead-gen publishers in adjacent verticals (insurance, legal services, home services, mortgage) will see the rates extended on a vertical-by-vertical basis.
In the next thirty-six months, the AI-referred-session conversion premium will compress. Currently, AI-referred sessions convert at materially higher rates than organic-search sessions because AI-search is a small fraction of total search and the cohort is self-selecting for high-intent users. As AI-search adoption broadens, the conversion premium will narrow toward the organic-search baseline. Publishers who built funnel architectures that depended on the premium will face margin compression in 2028-2029. Publishers who built architectures that captured the premium during the 2026-2027 window will have generated the cumulative funnel volume to amortize the build over the lower-premium tail.
The longer-term shift is more interesting. The GA event is a precedent for what happens when an infrastructure provider standardizes a pricing primitive at network scale. Other layers of the publisher stack – comment moderation, video transcoding, image rights – operate under similar fragmented or implicit-cost conditions. The case for shipping similar pricing primitives in those layers will be made by reference to the success of AI Crawl Control. Publishers who build infrastructure flexibility now will be positioned to capture the next round of standardized pricing primitives as they arrive.
For lead-gen publishers, the strategic implication is to design the owned-media funnel for the world after the next pricing-primitive event, not just the world after this one. A funnel architecture that abstracts the crawler-pricing layer so that any future per-crawler price change can be deployed without funnel-layout changes is a more durable architecture than one optimized specifically for the April 2026 GA configuration.
Key Takeaways
Cloudflare’s August 2025 AI Crawl Control GA, consolidated across every plan tier during Agents Week 2026 and now producing more than one billion HTTP 402 responses per day across its network, reset the unit economics of owned-media lead-generation publishing in ways that compound across multiple layers. Treating the change as a publisher-rights story underestimates what happened.
The 402 response has become a network-scale pricing primitive that gives publishers operator-controllable economics over a crawler ecosystem that grew 15-fold on the user-driven axis and surged across multiple AI-lab agents through 2025.
The crawler taxonomy now splits into search-and-retrieval (OAI-SearchBot, Claude-SearchBot, PerplexityBot, ChatGPT-User, Claude-User, Perplexity-User) and training (GPTBot, ClaudeBot, CCBot, Google-Extended), and the operator decisions diverge across the two – search crawlers feed AI-referral conversion, training crawlers do not.
The crawl-to-refer ratio, made visible at network scale by Cloudflare Radar’s 2025 Year in Review with Perplexity peaking above 700:1 and OpenAI peaking at 3,700:1 in late March 2025, is now the load-bearing unit economic for publisher pricing decisions and for AI-search visibility monitoring.
AI-referred sessions convert at materially higher rates than organic-search sessions across multiple independent studies, a premium driven by the pre-qualification effect of AI-synthesized answers, which means the value of preserving search-crawler access exceeds the headline crawl-cost burden for most owned-media properties.
Three approaches will underperform: the block-everything posture (sacrifices the high-conversion AI-referral stream), the allow-everything posture (absorbs marginal cost without margin recovery on the worst-performing crawlers), and the static-pricing posture (misallocates pricing across crawler types whose economic value to the publisher diverges sharply).
Reddit, Stack Overflow, Condé Nast, Time, the Associated Press, BuzzFeed, and Pinterest represent the early-mover cohort whose pricing decisions will set vertical reference rates over the next twenty-four months; lead-gen publishers in adjacent verticals should benchmark against the cohort’s emerging rate sheet.
The implementation is non-trivial. A mid-sized owned-media lead-gen publisher should plan three to four months of engineering, policy, and editorial-revenue alignment work to capture the re-priced framework, with crawler analytics integration, per-crawler pricing policy, and funnel-variant infrastructure as the three critical-path items.
The five-year trajectory points toward continued 402 volume growth, marquee AI-lab-to-publisher licensing deals during 2026-2027, AI-referred conversion premium compression by 2029 as AI-search broadens, and additional standardized pricing primitives in adjacent infrastructure layers that will reward publishers with flexible owned-media architectures.
For lead-gen publishers currently running flat-rate or block-everything AI crawler configurations, the next ninety days are the planning window. The next one hundred and eighty days are the build window. The first AI labs to negotiate licensing deals against the new architecture are doing it in the back half of 2026; the publishers who arrive at those conversations with per-crawler analytics, documented pricing policy, and AI-referral-calibrated funnels capture the structural margin opportunity. The publishers who arrive later compete for what is left.
Frequently Asked Questions
What did Cloudflare actually announce during Agents Week 2026?
AI Crawl Control reached general availability in August 2025. What Agents Week 2026 (April 13-17) added was consolidation: per-crawler verification, robots.txt management, and pay-per-crawl pricing folded into a single operator console available free across every Cloudflare plan tier, with the disclosure that customers across the Cloudflare network are now sending more than one billion HTTP 402 Payment Required responses to AI crawlers per day. The early-adopter list included Condé Nast, Time, the Associated Press, BuzzFeed, Reddit, Pinterest, and Stack Overflow. The Agents Week consolidation turned the 402 response from a beta-stage signal into a network-scale pricing primitive that publishers can configure on a per-crawler basis to allow, charge, or block individual AI crawler agents.
Why does the 402 framing matter more than the blocking framing for lead-gen publishers?
The blocking framing treats AI crawlers as a binary security or compliance decision – allow or deny. The 402 framing treats them as economic counterparties whose access is priced. For lead-generation publishers running owned-media properties, the distinction is operationally significant because AI-search referrals (the visitors that AI platforms route back to publisher pages after citing them in answers) carry materially higher conversion rates than traditional organic-search referrals, according to multiple independent studies including Conductor’s 2026 AEO/GEO Benchmarks Report and various 2025-2026 trade-press analyses. A blocking-only response sacrifices that referral stream. A 402-based pricing response preserves the referral stream while recovering the marginal cost of admitting the crawler. The pricing framing aligns the operator’s decision logic with the funnel economics rather than with a security-team default.
How does the AI search crawler taxonomy work – what’s the difference between OAI-SearchBot and GPTBot?
OpenAI runs at least three named user-agents serving different functions: GPTBot is the foundation-model training crawler whose primary purpose is to acquire content for model training; OAI-SearchBot is the search-and-retrieval indexer that supports ChatGPT Search retrieval; and ChatGPT-User is the user-initiated fetcher that pulls a specific URL when a ChatGPT user asks the model to read it. Anthropic operates a parallel three-bot taxonomy with ClaudeBot (training), Claude-SearchBot (search indexing), and Claude-User (real-time fetch). Perplexity runs PerplexityBot (indexing) and Perplexity-User (real-time retrieval). Google’s Google-Extended is a training opt-out token rather than a separate crawler. The practical implication for publishers is that search-and-retrieval crawlers feed the AI-referral stream that returns visitors to the publisher’s page, while training crawlers do not. The two categories therefore warrant different access and pricing decisions, and AI Crawl Control’s GA package gives publishers per-crawler configuration to act on the distinction.
What is the crawl-to-refer ratio and why does it matter as a unit economic?
The crawl-to-refer ratio is the number of crawler requests an AI platform issues against a publisher’s site for each human referral the same platform sends back. Cloudflare Radar’s 2025 Year in Review made the metric visible at network scale, reporting that Perplexity’s PerplexityBot crawl-to-refer ratio spiked above 700:1 in late March 2025, peaked below 400:1 through the summer, and stabilized below 200:1 from September onward, while OpenAI’s ratios reached as much as 3,700:1 at the same March 2025 peak. The metric matters because it quantifies how much crawler volume a publisher absorbs per unit of referral traffic the publisher receives in return. A high ratio means the AI lab is heavily extracting content without proportionally returning visitors; a low ratio means the lab’s crawler is efficient and the relationship is more reciprocal. Per-crawler pricing decisions in AI Crawl Control should be calibrated against the ratio: low-ratio crawlers warrant cheap or free admission, high-ratio crawlers warrant cost-recovery pricing.
Which publishers are in the early-adopter cohort and what does that mean for vertical reference pricing?
Cloudflare’s announcement named Condé Nast, Time, the Associated Press, BuzzFeed, Reddit, Pinterest, and Stack Overflow among the early adopters of the pay-per-crawl framework. The cohort spans premium news (Condé Nast, Time, AP), social and user-generated platforms (Reddit, Pinterest), and technical Q&A (Stack Overflow). Their participation in the early phase means that vertical-specific pricing reference rates will be established by these participants over the next twenty-four months as the AI labs solidify content-acquisition strategies. Lead-gen publishers in adjacent verticals – finance, insurance, mortgage, legal services, home services, software comparison – should benchmark their per-crawler pricing decisions against the rates that emerge from the early-adopter cohort, because AI-lab procurement teams will reference those rates when negotiating across the longer tail of the publisher market.
What does the AI-referred session conversion premium actually look like?
Independent research from late 2025 and early 2026 has consistently documented that AI-referred sessions convert at higher rates than traditional organic-search sessions, though the precise multiple varies by study and cohort. Industry estimates suggest AI-referred traffic converts approximately 22 percent higher than traditional organic on average, with some 2026 conversion-benchmark data showing AI-search referrals at 3.49 percent versus 2.86 percent for traditional organic. Conductor’s 2026 AEO/GEO Benchmarks Report tracked 35.7 million AI-driven sessions across 1,215 enterprise domains as part of the broader benchmark study. The directional message across studies is consistent: an AI-referred visitor arriving at a lead form has been pre-qualified by the AI’s retrieval logic in a way that organic-search visitors have not, and the pre-qualification produces a measurable conversion uplift. The specific premium is expected to compress over time as AI-search adoption broadens, but the premium is currently large enough that preserving search-crawler access produces meaningful funnel value.
How should a lead-gen publisher think about training crawlers like GPTBot, ClaudeBot, CCBot, and Google-Extended?
Training crawlers acquire content for foundation-model training. They do not directly produce AI-referred traffic back to the publisher. The publisher’s value proposition for admitting them is therefore different from the value proposition for admitting search crawlers. Training crawlers warrant pricing that reflects the publisher’s content’s contribution to model capability rather than pricing that reflects expected referral traffic. Stack Overflow’s February 2026 case study with Cloudflare framed the decision explicitly: AI labs that build on publisher content for training should pay proportionally to that content’s contribution to model capability, and the 402 response framework gives the publisher the operator surface to enforce proportional pricing. For lead-gen publishers in technical or specialty verticals where published content has unusually high training-data value, the Stack Overflow framing is the appropriate template. Publishers in vertical content categories where the marginal training value is lower should set training-crawler prices closer to bandwidth-recovery levels.
What are the compliance considerations for setting 402 prices and AI-content licensing terms?
Setting per-crawler prices and 402 response messages introduces commercial terms that interact with applicable disclosure, copyright, and licensing frameworks. Publishers should validate that the 402 message language, the linked licensing endpoint, and the per-crawler price terms are consistent with the publisher’s existing copyright notices, terms of service, and any vertical-specific compliance requirements (FTC disclosures, state-level data-broker registrations, sector-specific advertising rules). A typical compliance review of an AI Crawl Control configuration is a one- to two-week external counsel engagement and is recommended before the first paid-crawl transaction. The legal framework around crawler pricing is still developing; publishers should expect to revisit terms as case law and regulatory guidance accumulate over the next twelve to twenty-four months.
How does this affect the lead-gen publisher’s funnel architecture?
AI-referred visitors arrive at the publisher’s page in a different cognitive state from organic-search visitors. They have already received an AI-synthesized answer to their question and are clicking through specifically to validate, deepen, or take action. The funnel architecture that captures the highest conversion from this cohort is structurally different: the page should anticipate that the visitor knows the topline answer, present validating depth quickly, and route to the form-fill or conversational lead-qualification interaction faster than the equivalent organic-search visitor would expect. Implementing this requires either edge-side rules (Cloudflare Workers or equivalent) that detect the referral source and serve a calibrated funnel variant, server-side rendering decisions, or client-side personalization. Publishers running a single funnel layout for both traffic cohorts underperform publishers who serve calibrated variants, because the conversion-rate assumptions diverge across the two cohorts.
What is the realistic timeline for a mid-sized lead-gen publisher to capture the re-priced framework opportunity?
A typical implementation timeline runs three to four months end-to-end, broken into parallel work streams. Crawler analytics integration takes twenty to forty days for connecting AI Crawl Control console data to publisher analytics and building the per-crawler ratio dashboard. Per-crawler pricing framework definition takes thirty to sixty days for stakeholder alignment and policy documentation. AI Crawl Control configuration itself is a five-to-ten-day engineering task once the policy is approved. Funnel variant infrastructure takes forty to eighty days for edge-rule detection and variant content production. Compliance and disclosure review runs in parallel for ten to fifteen days. The publishers who finish ahead of the three-to-four-month timeline are those who started editorial-revenue stakeholder alignment in parallel with engineering work rather than sequentially.
How will this evolve through 2029?
The five-year trajectory points to four sequential shifts. In the next twelve months, expect 402 response volume to continue growing as more publishers configure AI Crawl Control and AI crawler volume itself continues its 2025 trajectory; expect competing CDN and edge providers to ship feature parity. In the next twenty-four months, expect marquee AI-lab-to-publisher licensing deals – likely in news, financial information, and specialty technical content – to establish per-vertical reference rates that lead-gen publishers benchmark against. In the next thirty-six months, expect the AI-referred-session conversion premium to compress as AI-search adoption broadens beyond the current high-intent early-adopter cohort. By 2029, expect the precedent set by AI Crawl Control to extend into adjacent infrastructure layers – comment moderation, video transcoding, image rights – where similar pricing primitives have not yet been standardized, creating additional rounds of operator opportunity for publishers with flexible architectures.
What about lead-gen publishers who do not run their own owned-media properties and rely on paid acquisition instead?
Lead-gen operators who run paid-acquisition-dominant funnels rather than owned-media properties face an indirect version of the same shift. The AI-search ecosystem affects the paid-acquisition cost base because AI-search is increasingly intermediating the discovery journey that previously routed through paid search. As AI-search referrals grow and as AI-search platforms either monetize their own ad inventory or refer downstream to publishers who do, the paid-acquisition keyword-bid landscape will redistribute. Operators who rely entirely on paid acquisition without complementary owned-media coverage will see acquisition costs migrate as the discovery layer migrates. The defensive response is to build at least a baseline owned-media presence specifically for AI-search citation, even if the primary acquisition channel remains paid. The 402 framework is less directly relevant for paid-only operators, but the broader shift in AI-search-driven lead generation economics is highly relevant. Operators who treat AI-search as a future problem rather than a current one will face the cost migration without the owned-media offset.
Sources
Tier 1: Primary Cloudflare Sources
-
Cloudflare, “The next step for content creators in working with AI bots: Introducing AI Crawl Control,” Cloudflare Blog – https://blog.cloudflare.com/introducing-ai-crawl-control/
-
Cloudflare, “Building the agentic cloud: everything we launched during Agents Week 2026,” Cloudflare Blog, April 2026 – https://blog.cloudflare.com/agents-week-in-review/
-
Cloudflare, “Introducing pay per crawl: Enabling content owners to charge AI crawlers for access,” Cloudflare Blog – https://blog.cloudflare.com/introducing-pay-per-crawl/
-
Cloudflare, “AI Crawl Control Documentation: Overview,” Cloudflare Developer Docs, accessed April 28, 2026 – https://developers.cloudflare.com/ai-crawl-control/
-
Cloudflare, “Manage AI crawlers – AI Crawl Control docs,” accessed April 28, 2026 – https://developers.cloudflare.com/ai-crawl-control/features/manage-ai-crawlers/
-
Cloudflare, “Verify your AI crawler – Pay-per-crawl docs,” accessed April 28, 2026 – https://developers.cloudflare.com/ai-crawl-control/features/pay-per-crawl/use-pay-per-crawl-as-ai-owner/verify-ai-crawler/
-
Cloudflare Press Release, “Cloudflare Just Changed How AI Crawlers Scrape the Internet-at-Large; Permission-Based Approach Makes Way for A New Business Model,” 2025 – https://www.cloudflare.com/press/press-releases/2025/cloudflare-just-changed-how-ai-crawlers-scrape-the-internet-at-large/
-
Cloudflare Radar, “2025 Year in Review,” accessed April 28, 2026 – https://radar.cloudflare.com/year-in-review/2025
-
Cloudflare Blog, “The 2025 Cloudflare Radar Year in Review: The rise of AI, post-quantum, and record-breaking DDoS attacks” – https://blog.cloudflare.com/radar-2025-year-in-review/
-
Cloudflare Blog, “From Googlebot to GPTBot: who’s crawling your site in 2025” – https://blog.cloudflare.com/from-googlebot-to-gptbot-whos-crawling-your-site-in-2025/
-
Cloudflare Press, “Cloudflare expands its Agent Cloud to power the next generation of agents,” 2026 – https://www.cloudflare.com/press/press-releases/2026/cloudflare-expands-its-agent-cloud-to-power-the-next-generation-of-agents/
Tier 2: Established Trade Press and Industry Research
-
AdMonsters, “Cloudflare’s AI Crawl Control Gives Publishers The Power To Choose. Now What?” – https://www.admonsters.com/cloudflares-ai-crawl-control-gives-publishers-the-power-to-choose-now-what/
-
AdMonsters, “Pay to Crawl: Cloudflare Sparks a New AI Monetization Model for Publishers” – https://www.admonsters.com/pay-to-crawl-cloudflare-sparks-a-new-ai-monetization-model-for-publishers/
-
Stack Overflow Blog, “Why Stack Overflow and Cloudflare launched a pay-per-crawl model,” February 19, 2026 – https://stackoverflow.blog/2026/02/19/stack-overflow-cloudflare-pay-per-crawl/
-
MediaPost, “Cloudflare Confronts AI Content Scrapers With ‘402’ Pay Code” – https://www.mediapost.com/publications/article/407093/cloudflare-confronts-ai-content-scrapers-with-402.html
-
MediaPost, “Brand Websites See Less Traffic, Reddit And Wikipedia Lead ChatGPT Citations” – https://www.mediapost.com/publications/article/408353/brand-websites-see-less-traffic-reddit-and-wikipe.html
-
Search Engine Journal, “Cloudflare Sparks SEO Debate With New AI Crawler Payment System” – https://www.searchenginejournal.com/cloudflare-sparks-seo-debate-with-new-ai-crawler-payment-system/550328/
-
Search Engine Journal, “Anthropic’s Claude Bots Make Robots.txt Decisions More Granular” – https://www.searchenginejournal.com/anthropics-claude-bots-make-robots-txt-decisions-more-granular/568253/
-
Search Engine Land, “Googlebot dominates web crawling in 2025 as AI bots surge: Report” – https://searchengineland.com/googlebot-crawling-ai-bots-2025-report-466402
-
Search Engine Land, “ChatGPT is sending less traffic to websites – down 52% in a month” – https://searchengineland.com/chatgpt-traffic-referrals-plummet-461027
-
TechRadar, “Cloudflare report reveals global internet traffic grew 19% in 2025 – but a lot of it was just bots” – https://www.techradar.com/pro/security/cloudflare-report-reveals-global-internet-internet-traffic-grew-19-percent-in-2025-but-a-lot-of-it-was-just-bots
-
The Register, “Cloudflare report shows mobile, bot traffic growing,” December 15, 2025 – https://www.theregister.com/2025/12/15/cloudflare_report_bot_traffic/
-
InfoQ, “Cloudflare Year in Review: AI Bots Crawl Aggressively, Post-Quantum Encryption Hits 50%, Go Doubles,” December 2025 – https://www.infoq.com/news/2025/12/cloudflare-2025-ai-bots/
-
Stan Ventures, “Cloudflare Launches AI Crawl Control with 402 Payment Required” – https://www.stanventures.com/news/cloudflare-launches-ai-crawl-control-to-give-content-creators-power-over-ai-bots-4182/
-
Press Gazette, “News publishers back Cloudflare blocking of all AI scrapers” – https://pressgazette.co.uk/news/major-uk-and-us-publishers-join-forces-to-block-ai-scrapers/
Tier 3: Industry Research and Analytics
-
Conductor, “2026 AEO/GEO Benchmarks Report: How AI Shapes Brand Visibility in a Zero-Click World,” BusinessWire – https://www.businesswire.com/news/home/20251113364791/en/Conductor-Unveils-2026-AEO-GEO-Benchmarks-Report-How-AI-Shapes-Brand-Visibility-in-a-Zero-Click-World
-
Conductor Academy, “How to Increase AI Referral Traffic & Drive Conversions” – https://www.conductor.com/academy/ai-referral-traffic/
-
Digiday, “In Graphic Detail: The state of AI referral traffic in 2025” – https://digiday.com/media/in-graphic-detail-the-state-of-ai-referral-traffic-in-2025/
-
Search Engine Roundtable, “ChatGPT Sources Mostly From Wikipedia While Google AI Overviews Sources Mostly From Reddit” – https://www.seroundtable.com/chatgpt-google-aio-sources-39578.html
-
BuzzStream, “Top Sites Showing Up in ChatGPT (Across Multiple Studies)” – https://www.buzzstream.com/blog/top-sites-chatgpt/
-
BuzzStream, “Which News Sites Block AI Crawlers in 2025? [New Data]” – https://www.buzzstream.com/blog/publishers-block-ai-study/
-
PPC Land, “AI traffic converts at 3x higher rates than traditional channels” – https://ppc.land/ai-traffic-converts-at-3x-higher-rates-than-traditional-channels/
-
PPC Land, “Cloudflare expands 402 payment protocol for AI crawler communication” – https://ppc.land/cloudflare-expands-402-payment-protocol-for-ai-crawler-communication/
Tier 4: Supporting Industry Commentary
-
ALM Corp, “ClaudeBot, Claude-User & Claude-SearchBot: Anthropic’s Three-Bot Framework and What It Means for Your robots.txt Strategy” – https://almcorp.com/blog/anthropic-claude-bots-robots-txt-strategy/
-
Momentic Marketing, “List of Top AI Search Crawlers + User Agents (Winter 2025)” – https://momenticmarketing.com/blog/ai-search-crawlers-bots
-
Scrunch, “Guide to AI User Agents” – https://scrunch.com/resources/guides/guide-to-ai-user-agents/
-
NAV43, “AI Crawlers vs Search Crawlers: What Technical SEO Teams Need to Know in 2026” – https://nav43.com/blog/ai-crawlers-vs-search-crawlers-technical-seo-guide/
-
No Hacks, “The AI User-Agent Landscape in 2026: A Complete Reference” – https://nohacks.co/blog/ai-user-agents-landscape-2026
-
Playwire, “The Complete Publisher’s Guide to AI Crawlers: Block, Allow, or Optimize for Maximum Revenue” – https://www.playwire.com/block-ai
-
Fastly, “How to Control and Monetize AI Bot Traffic Using Fastly and TollBit” – https://www.fastly.com/blog/how-to-control-and-monetize-ai-bot-traffic-using-fastly-and-tollbit
-
ContentGrip, “How publishers are getting paid for AI use of their content” – https://www.contentgrip.com/ai-publishers-crawl-fees/
-
The Pepper Guild on Medium, “The Rise of Reddit: How the Forum Giant is Surpassing Wikipedia in AI Model Citations,” August 2025 – https://thepepperguild.medium.com/the-rise-of-reddit-how-the-forum-giant-is-surpassing-wikipedia-in-ai-model-citations-3e7234cc9f8d
-
Revel Interactive, “One in Five ChatGPT Citations Go to Reddit and Wikipedia, What Does That Mean for SEO?” – https://www.revelinteractive.com/blogposts/2025/10/3/one-in-five-chatgpt-citations-go-to-reddit-and-wikipedia-what-does-that-mean-for-seo
Closing
The August 2025 GA and Agents Week 2026 consolidation will be remembered for the wrong reason. The headlines treated it as the moment Cloudflare made AI scraping commercially negotiable – a publisher-rights milestone in a multi-year scraping debate. That framing misses what actually happened. The structural event was the consolidation of per-crawler economics into a single operator-controllable surface at network scale, and the operational event was the emergence of the crawl-to-refer ratio as a load-bearing unit economic that ties content production to lead capture in a way that did not exist twelve months ago. The lead-gen publishers who treat April 2026 as a security-tooling upgrade will spend the next two years operating AI-crawler configurations that no sophisticated buyer would have chosen. The publishers who treat it as a unit-economic reset will run per-crawler pricing, ratio-based visibility monitoring, and AI-referral-calibrated funnels into the margin window that closes when the rest of the market catches up. The decision about which group to be in is being made now, in the next ninety days of planning and the next one hundred and eighty days of build. There is no comfortable third option.
Market data, AI crawler activity statistics, and publisher pricing reflect publicly reported conditions through April 28, 2026. AI Crawl Control features, per-crawler pricing terms, and AI-search referral analytics change continuously; verify current configurations through Cloudflare’s official documentation before making operational decisions. This article provides general industry analysis and does not constitute legal, financial, or compliance advice. Consult qualified counsel for specific compliance questions related to AI-content licensing terms, 402 response messaging, and visitor-routing disclosure requirements.