
Privacy Sandbox is dead. Cookies are degraded. The stack that replaces them has three layers – and most operators are running fewer than two.
The 2026 Attribution Reality
This article is the orchestration layer. The site already covers each cookieless component as a standalone deep-dive – Marketing Mix Modeling for lead generation, multi-touch attribution mechanics, server-side tracking implementation, Facebook CAPI setup, and incrementality testing methodology. What follows is for operators trying to decide HOW to combine those layers into a coherent stack: which tool answers which question, where each layer breaks down, and what to add at which budget threshold. Each section points to the relevant deep-dive where readers want more depth on a specific component.
On October 17, 2025, Google announced it would retire most of the Privacy Sandbox APIs, including Topics, Protected Audience, and the attribution-related components. Topics API is scheduled for deprecation in Chrome 144 and full removal in Chrome 150. Google retained CHIPS, FedCM, and Private State Tokens but ended the Privacy Sandbox branding entirely. Six years of industry preparation for a Chrome-led replacement to third-party cookies ended in a wind-down notice.
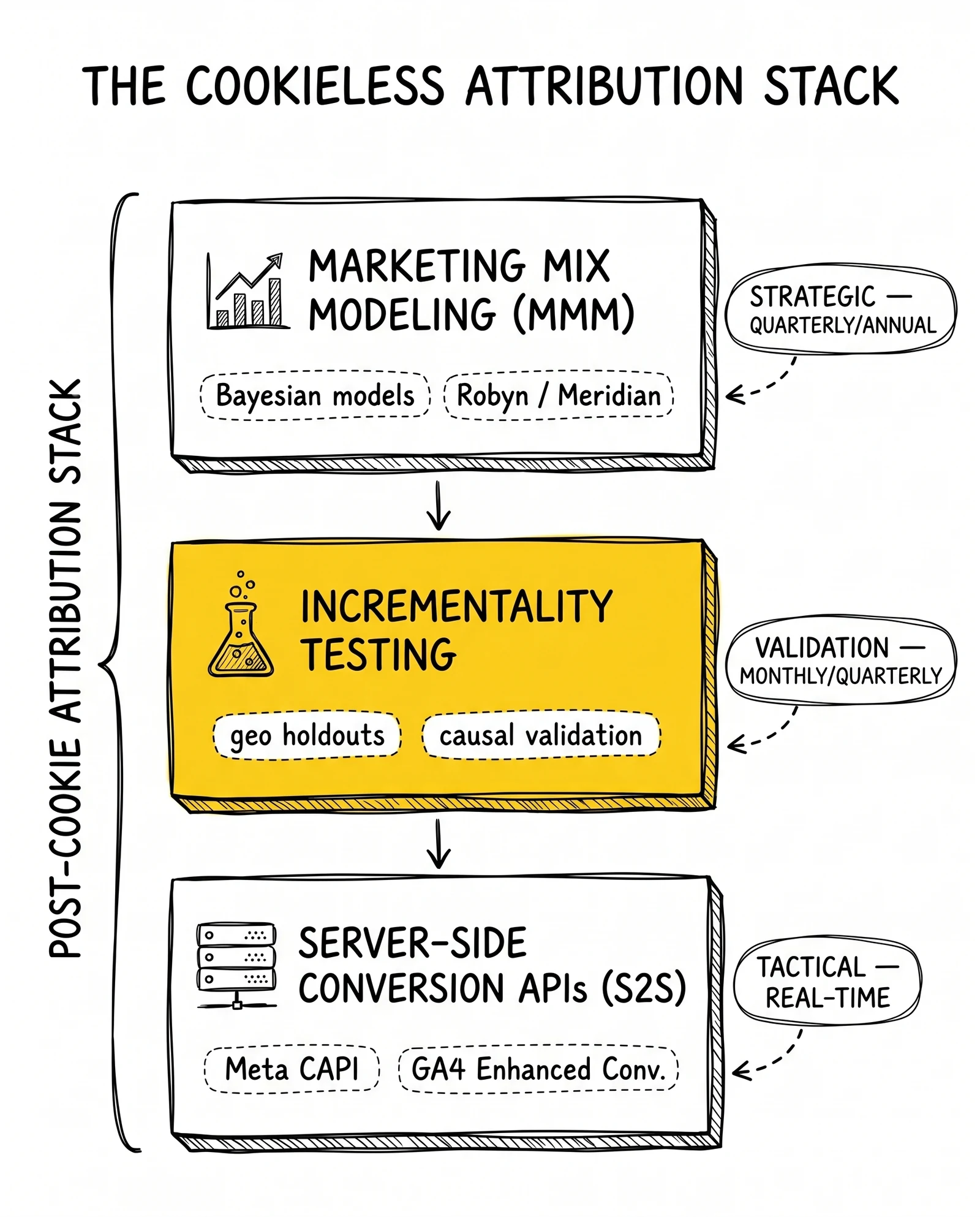
Third-party cookies still exist in Chrome. That part survived. What did not survive was the deterministic attribution model that the digital advertising industry assumed it could rebuild on top of Privacy Sandbox primitives. The replacement is not a single API. It is a stack of three complementary measurement layers – Marketing Mix Modeling for strategic allocation, incrementality testing for causal validation, and server-side conversion APIs (which recover roughly 20-30% of pixel-lost signal) for tactical recovery – none of which alone provides the granular path-level attribution that marketers used between 2010 and 2020. The decision operators face is not which layer to buy but in what order to assemble them.
The decay had been visible for years. Safari blocked third-party cookies by default in 2017 and added Intelligent Tracking Prevention. Firefox enabled Enhanced Tracking Protection in 2019 and Total Cookie Protection by default in 2022. Apple shipped iOS 14.5 in April 2021 with App Tracking Transparency, which gated the Identifier for Advertisers behind an explicit user prompt that 75-85% of users decline. By the time Privacy Sandbox formally retired, addressable audiences via third-party cookies had already shrunk to roughly 60% of US users – the share who use Chrome on desktop or mobile and have not blocked or cleared cookies.
For lead generation operators, ecommerce brands, and B2B SaaS marketers, the practical problem is this: the ad platforms now see between 50% and 70% of actual conversions on a typical campaign. Multi-touch attribution coverage, which used to sit at 90%+ in a logged-in, cross-device deterministic world, fell to 30-60% by 2026. Last-click attribution, never accurate, is now actively misleading because the touches it does see are not a representative sample of the touches that occurred.
The replacement stack is well understood at this point and the vendors have stabilized. What separates operators who run profitable paid media in 2026 from operators who do not is whether they have assembled the three layers in the right order and at the right spend threshold. The rest of this analysis covers what each layer measures, which platforms compete in each, how the layers interact, and what to add at which budget cutoff. Operators currently relying on a single GA4 last-click view or a Meta pixel-only setup can recover 20-40% of lost conversion signal with server-side tracking alone before any larger investment.
Why Multi-Touch Attribution Broke
Multi-touch attribution was a regression on a complete, deterministic dataset. The model required three things: an identifier persistent across the customer journey, visibility into every touchpoint, and a closed-loop tie from the final conversion back to every prior touch. Cookies, mobile advertising IDs, and CRM email matches together delivered all three for roughly a decade.
Each of those three foundations cracked in different ways between 2017 and 2025. Safari ITP started capping client-set cookies at seven days, then one day under tracker-detected conditions. Firefox blocked cross-site cookies entirely. iOS 14.5 ATT eliminated 75-85% of mobile advertising ID matches at the source. Email matching survived but only for users who logged in or converted, which is a self-selecting sample.
The math broke in a specific way. MTA models require complete journeys to assign weighted credit. When journeys are incomplete – when 40% of touches are invisible – the model still assigns 100% of credit, but it assigns it to whichever touches the model can see. The result is not 60% accurate attribution. It is systematically biased attribution that overweights channels with better tracking infrastructure (typically the walled gardens) and underweights channels with weaker tracking (typically upper-funnel and offline channels).
A second-order problem emerged. Marketers who used MTA to optimize budgets toward channels the model credited got worse results year over year, because they were optimizing toward the channels with the best tracking rather than the channels with the best incremental impact. Several large advertisers ran controlled holdout tests in 2023-2024 and found that MTA-optimized budget allocations underperformed flat allocations by 15-30% on incremental revenue.
That is not the death of MTA. The consensus among 2026 measurement practitioners is that MTA still has a useful role for tactical optimization within a single channel – comparing creative variants on Meta, comparing keyword groups on Google – where the platform’s first-party data covers most of the journey. What MTA stopped being is a single source of truth for cross-channel budget allocation. That role moved to MMM. Operators looking at the broader comparison of attribution models for lead generation will find that multi-touch and last-click both now sit inside a larger stack rather than serving as the primary view.
The implication for stack assembly: do not buy a multi-touch attribution platform first. Buy server-side tracking first to fix the input data, then add MMM for budget allocation, then add incrementality testing for causal validation. MTA fits in as a tactical optimization layer once those three foundations exist.
Marketing Mix Modeling – The Bayesian Resurgence
Marketing Mix Modeling predates digital advertising. It originated in CPG measurement in the 1960s, regressing weekly sales against weekly media spend across TV, radio, print, and promotions. MMM faded during the deterministic-attribution era because user-level tracking was more granular and faster to act on. It returned because user-level tracking broke and because Bayesian methods made MMM faster to implement and more useful for tactical decisions.
The mechanics are straightforward. MMM regresses an outcome variable (revenue, leads, signups) against weekly or daily marketing spend by channel, plus controls for seasonality, promotions, distribution changes, competitive activity, and macroeconomic factors. The output is a saturation curve and adstock parameter for each channel, which together describe diminishing returns and carryover effects. From those, the model produces budget recommendations: shift X% from channel A to channel B to maximize forecast revenue.
Two things changed in MMM between 2020 and 2026. First, Bayesian methods replaced ordinary least squares regression as the dominant approach. Bayesian MMM models include prior beliefs explicitly, handle uncertainty through posterior distributions rather than point estimates, and naturally incorporate experimental data from lift tests as priors on channel coefficients. Second, two major platforms released open-source MMM packages, dropping the cost of entry from a six-figure consulting engagement to a data engineer’s time.
Meta Robyn launched in 2021 as an open-source ridge regression MMM, originally written in R and later ported to Python. Robyn automates hyperparameter search, multi-objective optimization, and the saturation/adstock transformation grid. Meta uses Robyn internally and the open-source version mirrors the production tooling. Robyn works well when Meta is the largest spend channel because Meta’s spend data integrates cleanly and the model’s prior structures align with paid social patterns.
Google Meridian launched in 2024 as the open-source successor to LightweightMMM. Meridian uses a Bayesian framework rather than ridge regression and supports geo-level hierarchical modeling natively. The geo-level support is the key differentiator: rather than modeling national spend against national outcomes, Meridian can model spend in 50 US states (or 20 European markets) against outcomes in those geos, producing both a national result and per-geo decomposition. The geo support also makes Meridian a natural complement to geo-incrementality experiments, where the experiment results can be fed back into the model as priors on the relevant channel coefficients.
The practical guideline is to pick Meridian if Google Ads is the largest spend channel or if the team plans to run geo-experiments. Pick Robyn if Meta is dominant or if the team’s data infrastructure is already in R. Either tool produces production-ready budget recommendations. Below them sit a tier of commercial MMM platforms – Recast, LiftLab, Mass Analytics, Funnel – that wrap similar Bayesian methods in managed software with weekly model refreshes, pre-built data connectors, and confidence-interval visualization. Recast publicly targets the $500K-$10M annual ad spend segment with weekly refresh cadence, which is the band where managed MMM begins to make economic sense.
When MMM Becomes Worth the Effort
MMM requires two to three years of historical weekly spend data across channels and a clean outcome variable. For a lead generation operator running across Meta, Google, TikTok, email, affiliates, and call center campaigns, the model needs roughly 100-150 weekly observations per channel to produce coefficients with usable confidence intervals. Below that, the model fits but the uncertainty is wide enough that the recommendations are not actionable.
This rules out most operators below $1M annual ad spend. The data does not exist or it does not span enough channels to identify cross-channel effects. For those operators, the right MMM substitute is structured experimentation: rotating budget cuts across channels in 4-8 week windows and measuring outcome lift through holdout periods. That approach delivers similar insight to MMM at a fraction of the data requirement, though it sacrifices the cross-channel optimization view.
Above $5M annual ad spend, MMM is essentially required. The number of channels, the cross-channel interactions, and the cost of suboptimal allocation all scale into a range where leaving 5-15% efficiency on the table costs more than a Bayesian MMM platform.
Incrementality Testing – Causal Validation as Continuous Discipline
MMM produces correlational estimates dressed up with priors. Incrementality testing produces causal estimates from controlled experiments. Both belong in the stack because they answer different questions. MMM allocates budget across the existing channel set. Incrementality validates whether each channel actually drives causal lift relative to what the customer would have done without the marketing exposure.
The canonical incrementality method is geo-randomized controlled trials. The marketer divides the country into matched geo pairs based on baseline outcome similarity, exposes one geo in each pair to the campaign, holds the other dark, and measures the difference in outcomes. Done correctly, the result is a clean causal estimate of channel lift. Done sloppily, the geos are not matched, the holdout period is too short, or seasonal effects swamp the signal.
Haus specializes in geo-randomized controlled trials with Bayesian inference and rigorous experimental design. Haus emphasizes statistical rigor – pre-registration of test parameters, power analysis to size the holdout, and explicit treatment effects with credible intervals. Haus is the choice when the answer needs to defend itself in a CFO review or a board meeting.
INCRMNTAL takes a different approach. Rather than running discrete geo experiments, INCRMNTAL records natural budget fluctuations and ad platform changes as “micro-experiments” and uses causal AI to estimate continuous lift without explicit holdouts. The advantage is that it produces always-on estimates without sacrificing geo coverage to a holdout. The trade-off is that the causal claim depends on the model’s identification strategy rather than on randomization. For mobile-app marketers, gaming companies, and operators in small markets where geo-holdouts are infeasible, INCRMNTAL fills a real gap.
Lifesight positions as a privacy-first measurement platform using causal AI to infer incrementality from aggregated patterns without user-level tracking or cookies. Lifesight overlaps with both Haus and INCRMNTAL conceptually but differentiates on its broader measurement suite – combining MMM, incrementality, and unified reporting in one platform.
Northbeam added an incrementality module in Q1 2026 that integrates with its existing multi-touch and MMM products. Northbeam’s pitch is the unified platform: tactical MTA, strategic MMM, and causal incrementality from the same data foundation, so that the three views reconcile rather than contradict each other.
| Platform | Method | Best For | Key Trade-off |
|---|---|---|---|
| Haus | Geo-randomized RCT, Bayesian | Defending claims to CFO/board | Requires geo holdout, slower cadence |
| INCRMNTAL | Causal AI, continuous, no holdout | Mobile, small markets, always-on | Identification depends on model assumptions |
| Lifesight | Causal AI, aggregated data | Privacy-first ops, unified suite | Newer entrant, smaller benchmark base |
| Northbeam | Geo-experiments + MTA + MMM | DTC ecommerce, unified view | Best when full Northbeam stack adopted |
| LiftLab | Geo-experiments | Mid-market, structured testing cadence | Standalone – does not include MMM |
Geo Experiments in Practice
A geo-experiment for an insurance lead generator might pause Meta spend in 10 randomly selected DMAs for a 4-week period while maintaining spend in 10 matched control DMAs. The lift in form submissions in the test geos relative to control, after controlling for seasonal and competitive effects, is the incremental contribution of Meta to demand in those geos. For a brand spending $500K/month on Meta nationally, a 4-week 20% pause costs roughly $33K in foregone revenue for the test, which is a fraction of the value of knowing whether Meta drives 30% incremental lift or 5%.
The discipline that distinguishes operators who use incrementality well from those who do not is the cadence. One geo-test per year produces one data point. Quarterly geo-tests across 3-4 channels produce 12-16 data points, which is enough to inform the MMM priors and to catch channel performance drift. Always-on incrementality via INCRMNTAL or similar produces continuous estimates but requires more spend stability to interpret.
Server-Side Conversion APIs – Tactical Signal Recovery
The third layer is the most tactical and the highest ROI for most operators. Server-side conversion APIs recover the conversion data that browser-based pixels lose to ad blockers, browser privacy features, and iOS restrictions. The recovery rate is the highest-leverage single intervention in the cookieless stack.
Meta Conversions API (CAPI) sends conversion events from the advertiser’s server directly to Meta’s ingestion endpoint, bypassing the browser pixel entirely. When deployed alongside the browser pixel with proper event deduplication, CAPI recovers 20-30% of conversion data on a typical implementation. Some lead-gen and ecommerce operators report recovery in the 30-40% range, particularly on iOS-heavy traffic. Meta’s internal data shows advertisers running CAPI alongside the pixel achieve an average 17.8% lower cost per result. In April 2026, Meta released a “Meta-enabled” Conversions API setup that hosts the server-side connection on Meta’s infrastructure and removes the developer requirement entirely.
Google Enhanced Conversions uses hashed first-party customer data – email, phone, address – passed alongside conversion events to recover conversions that the browser tag missed. Google reports 5-15% additional conversion recovery on top of the standard Google tag. Implementation requires enabling enhanced conversions in Google Ads, accepting the customer data terms, and configuring the tag to pass hashed user data. The recovery is smaller than Meta’s CAPI primarily because Google Ads already benefits from Google’s logged-in user base for conversion stitching.
TikTok Events API sends conversion events server-side via the TikTok Events Manager. Setup runs through GTM Server with the official TikTok Events API community template, generating an access token from TikTok Ads Manager and configuring the pixel ID. Event deduplication via the event_id parameter prevents double-counting between the pixel and the API. TikTok’s ecosystem is younger and the recovery percentage is less consistent across operators, but the principle is the same and operators with significant TikTok spend should not skip it.
LinkedIn’s Conversions API addresses a B2B-specific problem. LinkedIn defaults to a 30-day attribution window but the B2B buying cycle averages 6-9 months. CAPI lets the advertiser send CRM events back to LinkedIn for opportunity creation, MQL conversion, and closed-won deals – events that occur far past the LinkedIn pixel’s attribution window but inform LinkedIn’s bidding algorithms. LinkedIn launched native CRM integration in June 2025; as of 2026, fewer than 15% of B2B SaaS advertisers have implemented full CRM integration with LinkedIn Ads.
Server-side Google Tag Manager (sGTM) is the infrastructure layer underneath most of these implementations. sGTM hosts on Google Cloud Run or Stape and routes events to all configured destinations from a single server-side container. Cost ranges from $40-$120/month for a Stape-hosted setup to $50-$300/month for self-hosted Cloud Run depending on event volume. The recurring cost is small relative to the conversion recovery value.
Implementation Order for Lead Generation
For a lead-gen operator running Meta, Google, and TikTok with $50K-$500K monthly spend, the implementation order is: deploy sGTM, implement Meta CAPI with deduplication, implement Google Enhanced Conversions, implement TikTok Events API, then layer in LinkedIn CAPI if running B2B campaigns. The full sequence takes 4-8 weeks for a competent agency or in-house data engineer. The conversion recovery alone typically pays for the implementation in the first 2-4 weeks of running, after which the recovered signal compounds via better algorithmic optimization in the ad platforms.
The Safari constraint matters even with server-side. Safari 16.4 caps server-set first-party cookies at seven days when the tracking server’s IP differs from the main site’s IP in the first two octets, which catches most basic sGTM setups. Aligning IPs via a custom subdomain pointing to the same hosting infrastructure preserves the longer cookie lifetime. Combining server events with hashed user data via CAPI sidesteps the cookie-lifetime problem entirely for users who provide email or phone at conversion. Lead generation operators looking at the full implementation playbook for Facebook CAPI and the broader server-side tracking architecture will find the technical details mapped end-to-end.
The CDP Layer – Clean Rooms and Identity Resolution
Above the conversion APIs sits a layer that most operators will not need but that increasingly defines competitive advantage at the enterprise tier: customer data platforms with clean room access. Data clean rooms enable two parties to combine first-party datasets for analysis without exposing raw PII to either side. Originally a Google Ads Data Hub feature, clean rooms have proliferated into a category dominated by LiveRamp, Snowflake, and the major cloud providers.
LiveRamp acquired Habu in 2024 for $200 million ($170M cash, $30M stock), consolidating two of the major independent clean room platforms. WPP acquired InfoSum the same year. Snowflake Data Clean Rooms launched as a native Snowflake product, integrating naturally with enterprise data warehouses. Decentriq, Optable, and AWS Clean Rooms compete in adjacent niches. The independent clean room provider landscape is now smaller than it was in 2023.
The use cases for lead generation are narrower than for ecommerce or CPG. Lead generators rarely have a publisher partnership that benefits from clean-room collaboration, and the buyer side of the lead-gen marketplace already runs its own attribution. Where clean rooms help lead-gen specifically is in audience expansion: appending B2B firmographic or intent signals from a clean-room partner without pulling raw PII across organizational boundaries.
Identity resolution is the more immediately applicable CDP feature for lead generation. LiveRamp’s RampID, Acxiom’s identity graph, and Experian’s persistent identifiers stitch user-level signals across devices and channels in a privacy-preserving manner. For lead generators running cross-channel attribution, identity resolution increases the share of journeys that can be reconstructed without third-party cookies. The cost – typically $50K-$200K annually for enterprise identity resolution – is justified at $10M+ annual marketing spend or where deterministic cross-device matching is mission-critical.
The honest assessment is that for operators below $5M ad spend, clean rooms and identity resolution are luxuries. The base layer of server-side tracking plus MMM plus incrementality testing covers 80% of the value. Clean rooms become economically interesting when the operator has a specific data partnership use case or when regulatory requirements (HIPAA, GDPR, MODPA) mandate that PII never cross organizational boundaries.
Lead Generation, Ecommerce, and B2B SaaS – Different Pain Points
The cookieless attribution stack is conceptually identical across verticals, but the pain points and the priority order differ.
Lead generation operators care most about call attribution, form-fill quality, and downstream conversion to closed sale. The journey often spans web, phone, and email across 30-90 days, and the conversion event that matters is not the form submission but the closed sale that may occur weeks later. Server-side CAPI implementations should pass the closed-sale event back to the ad platforms (using event matching on the original lead’s email or phone hash). MMM works well in lead-gen because the channels are diverse and the spend levels are typically high enough to support 100+ weekly observations. Incrementality testing is critical because the ratio of low-quality to high-quality leads varies dramatically by channel, and last-click MTA systematically credits low-quality channels that show conversions earlier in the funnel. Operators should review the broader GA4 lead generation tracking guide to ensure form events, call events, and CRM events flow into the same measurement substrate.
Ecommerce brands care most about checkout completion, return rate, and lifetime value. Journeys are shorter (days, not weeks), conversions are deterministic (the order ID), and LTV signals lag the initial conversion by 90-365 days. Meta CAPI and Google Enhanced Conversions deliver outsized value here because the conversion volume is high enough to feed algorithmic optimization quickly. Ecommerce was the canonical use case for Northbeam, Triple Whale, and similar unified attribution platforms, which still serve the segment well at $1M-$50M annual revenue.
B2B SaaS faces the opposite problem from ecommerce. Conversions are infrequent (10-100 deals per quarter, not 10,000 orders per day), the buying cycle averages 6-9 months, and LinkedIn dominates the upper-funnel mix. MTA and MMM both struggle with the data sparsity. The right stack is heavy on LinkedIn CAPI for closed-loop attribution back to LinkedIn’s bidding algorithms, plus G2 and review-site intent signals, plus aggressive use of UTM parameters and CRM-side journey reconstruction. Below $5M ARR, most B2B SaaS companies should not run formal MMM – the data is too thin. They should run quarterly incrementality tests on their largest channels and rely on LinkedIn-, Google-, and CRM-native attribution for tactical signal. Above $20M ARR, MMM becomes feasible if the company runs across LinkedIn, Google, content syndication, events, and partner channels with enough history.
Stack Assembly Playbook – What to Add When
The stack assembles in layers, with each layer worth more than the previous one, but only if the previous one is in place. Adding MMM on top of broken conversion data produces well-styled wrong answers.
| Annual Ad Spend | Add | Cost | Recovery / Value |
|---|---|---|---|
| < $250K | Server-side GTM + Meta CAPI + Google Enhanced Conversions | $100-300/mo | 15-30% conversion recovery |
| $250K-$1M | + TikTok/LinkedIn CAPI + structured channel holdout tests | $300-1,000/mo | 5-10% additional efficiency |
| $1M-$5M | + Open-source MMM (Robyn or Meridian) + 1-2 geo-experiments/year | Data engineer time + $0 software | 5-15% allocation efficiency |
| $5M-$20M | + Managed MMM (Recast, LiftLab) + quarterly geo-experiments via Haus or LiftLab | $5,000-25,000/mo | 10-20% allocation efficiency |
| $20M+ | + Continuous incrementality (INCRMNTAL or Northbeam) + identity resolution + clean room access where partner data exists | $50,000-200,000/mo | Defensive parity at scale |
The rule of thumb is that each layer should cost less than 5% of the value it unlocks. Server-side tracking at $300/month against $50K monthly ad spend recovers conversions worth far more than $300. MMM at $10K/month against $1M monthly ad spend pays for itself if it improves allocation by even 1%. Continuous incrementality at $50K/month against $5M monthly ad spend requires a 1% improvement to justify, which is achievable but not automatic.
The mistake operators make most often is buying the most expensive layer first. A $50K/month Northbeam contract on top of broken pixel data and no MMM produces dashboards but not insight. The cheaper foundation layers – sGTM, CAPI, Enhanced Conversions – create the data quality on which the expensive layers depend.
The second mistake is treating attribution as a one-time project. The stack works because the layers reconcile. MMM coefficients should match incrementality test results within reasonable confidence intervals. Conversion API recovery should be visible as improved cost per result in the ad platforms. When the layers diverge, that divergence is itself the signal – a channel where MMM and incrementality disagree is a channel that needs investigation, not a data quality complaint to ignore.
For lead generation operators specifically, the most underappreciated discipline is closing the loop from the closed sale back to the original lead source. Without that loop, MMM models the wrong outcome (form fills rather than closed sales), incrementality tests measure the wrong lift, and CAPI optimization steers the ad platforms toward channels that produce volume rather than revenue. The sales-stage event passed back through CAPI with the original lead’s email hash is the mechanism that makes the rest of the stack measure something that matters.
Key Takeaways
- Privacy Sandbox’s October 2025 retirement ended the assumption that a single Chrome-led standard would replace third-party cookies; the replacement is a three-layer stack, not a single API.
- Multi-touch attribution coverage fell from 90%+ to 30-60% by 2026 and now serves as a tactical layer rather than a single source of truth; MMM and incrementality replace it for cross-channel allocation.
- Meta Robyn (ridge regression, R/Python) and Google Meridian (Bayesian, native geo support) are the two open-source MMM packages worth evaluating; pick by largest spend channel and data team preference.
- Haus, INCRMNTAL, Lifesight, Northbeam, and LiftLab compete in incrementality testing; Haus excels at defensible RCTs while INCRMNTAL excels at always-on causal estimates without geo holdouts.
- Server-side conversion APIs recover a meaningful but bounded share of pixel-lost signal – Meta CAPI in the high teens to low thirties depending on iOS mix and ad-blocker prevalence, Google Enhanced Conversions adds 5-15% on top of standard Google tags, and advertisers running CAPI see 17.8% lower cost per result. The output is directional rather than deterministic; pair it with incrementality validation.
- Safari 16.4 caps server-set first-party cookies at 7 days under common sGTM configurations; IP alignment plus hashed user data via CAPI mitigates the constraint.
- Clean rooms (LiveRamp post-Habu, Snowflake, AWS) matter at enterprise scale or for specific partnership use cases; below $5M ad spend, clean rooms are usually a luxury rather than a foundation.
- Stack assembly order is server-side tracking, then MMM, then incrementality, then identity resolution and clean rooms; buying the expensive layer first produces dashboards without insight.
Frequently Asked Questions
Did Google really retire Privacy Sandbox in 2025?
Yes. Google announced on October 17, 2025 that it would retire Topics API, Protected Audience API, and most attribution-related Privacy Sandbox APIs after low industry adoption. Topics API is scheduled for deprecation in Chrome 144 with full removal in Chrome 150. Google retained CHIPS, FedCM, and Private State Tokens but ended the Privacy Sandbox branding. Third-party cookies persist in Chrome but Safari and Firefox continue to block them by default.
What conversion recovery rate does server-side tracking actually deliver?
Meta’s Conversions API recovers 20-30% of lost conversion data when paired with the browser pixel using event deduplication, with some implementations reporting 30-40%. Google Enhanced Conversions adds 5-15% on top of standard Google tag conversions. Advertisers running CAPI alongside the pixel see an average 17.8% lower cost per result according to Meta’s internal data. The recovery rate depends on browser mix, ad blocker prevalence, and the quality of customer data hashed and matched.
Why did multi-touch attribution break after the cookie deprecation?
MTA models depend on user-level cross-device tracking that requires persistent identifiers across browsers, apps, and sessions. Post-iOS 14.5 and Safari ITP enforcement, attribution coverage fell from 90%+ to 60-80%, and in some channels to 30-60%. MTA does not die outright in 2026 but it now operates as a tactical signal for digital channel optimization rather than a single source of truth. MMM handles strategic and offline allocation while incrementality tests validate causal claims.
Robyn or Meridian – which open-source MMM should an operator pick?
Meta released Robyn in 2021, written initially in R with a Python port, using ridge regression for cross-channel modeling. Google released Meridian in 2024 as a Bayesian successor to LightweightMMM with native geo-level data support. The practical guideline: pick Meridian if Google Ads is the largest spend channel and geo experiments are part of the measurement plan. Pick Robyn if Meta is dominant and the data team prefers the existing R ecosystem. Both produce production-ready budget recommendations.
What is incrementality testing and how does it differ from MMM?
Incrementality testing measures the causal lift of a specific channel or campaign by comparing exposed and holdout populations, typically using geo-randomized controlled trials. MMM models historical spend against outcome variables across all channels using regression. Incrementality answers “did this channel cause incremental conversions?” while MMM answers “how should the budget be allocated across channels?” Platforms like Haus, INCRMNTAL, and Lifesight specialize in continuous lift measurement using causal inference techniques.
How much does a clean room cost and when does it justify the spend?
LiveRamp acquired Habu in 2024 for $200 million, and Snowflake Data Clean Rooms are priced as part of Snowflake compute and storage consumption. Enterprise clean room engagements typically run six figures annually plus integration cost. The justification is usually a specific data partnership use case: a publisher and an advertiser combining audiences, a CPG brand and a retailer reconciling sales data, or a B2B SaaS company appending intent signals to a customer file without exposing PII to either side.
What does an attribution stack cost at different spend levels?
Below $500K annual ad spend, a server-side tagging container plus Meta CAPI plus Google Enhanced Conversions runs $100-500 per month and recovers most of the value. At $500K-$10M, adding a Bayesian MMM platform like Recast or open-source Robyn or Meridian costs $2,000-$15,000 per month. Above $10M, full stacks combining MMM, continuous incrementality, and clean room access run $20,000-$100,000+ per month. Lead generation operators should add layers in that order rather than buying an expensive platform first.
Does Safari ITP affect server-side tracking too?
Partially. Safari 16.4 caps server-set first-party cookies at seven days when it detects that the tracking server’s IP address differs from the main site’s IP address in the first two octets, which catches most basic server-side GTM setups. Safari also caps cookies on pages reached via gclid or fbclid parameters at 24 hours and purges all storage after 30 days of inactivity. Server-side tracking still recovers significant signal but practitioners must align IPs, use first-party domains, and combine server events with hashed user data via CAPI.
Where to Go Deeper
The orchestration view above is intentionally compressed. Each layer of the stack has its own implementation depth, vendor selection criteria, and operational tradeoffs that warrant a dedicated treatment. Operators ready to commit to a specific layer should follow these into the next level of detail:
- Marketing Mix Modeling for lead generation – the strategic allocation layer in depth, including data requirements, prior selection, saturation curves, and the tradeoffs between Robyn, Meridian, and managed platforms like Recast.
- Incrementality testing for lead marketing – geo experiment design, holdout sizing, statistical power calculations, and the cadence that turns one-off tests into a continuous causal validation discipline.
- Server-side tracking for lead generation – the foundational data-recovery layer covering sGTM architecture, IP alignment for Safari, and the implementation order that pays for itself in weeks.
- Facebook CAPI implementation guide – the platform-specific deep dive on event deduplication, customer information matching, and offline conversion upload for closed-loop lead-gen attribution.
- Multi-touch attribution models for lead gen – why MTA broke, where it still has tactical value within a single channel, and how it slots into the broader cookieless stack.
- Lead attribution models: first, last, multi-touch – the model-comparison primer for operators still deciding whether single-touch reporting is misleading their budget allocation.
Sources
- Google Privacy Sandbox: Update on Plans for Privacy Sandbox Technologies (October 2025)
- AdExchanger: Google Pulls The Plug On Topics, PAAPI And Other Major Privacy Sandbox APIs (2025)
- Apple WebKit: Intelligent Tracking Prevention
- Apple Developer: App Tracking Transparency Framework
- Meta Robyn: Open-Source Marketing Mix Modeling Package (GitHub)
- Google Meridian: Open-Source Bayesian MMM (GitHub)
- Meta Business: Conversions API Documentation
- Google Ads Help: Enhanced Conversions Setup
- TikTok for Business: Events API Documentation
- LiveRamp: LiveRamp Acquires Habu to Accelerate Data Collaboration (2024)