OpenAI shipped GPT-5.5 on April 23, 2026 at $5 per million input tokens and $30 per million output tokens - a clean doubling of the GPT-5.4 rate card. Voice agent operators panicked for a weekend. The math says they should not have.
The April 23 Reset
OpenAI released GPT-5.5 to the API on April 23, 2026, with availability extending to GPT-5.5 Pro the following day. Standard pricing landed at $5 per million input tokens and $30 per million output tokens, doubling the GPT-5.4 rate card of $2.50 input and $15 output. Cached input dropped to $0.50 per million; Batch and Flex tiers held at 50 percent of standard. GPT-5.5 Pro carried $30 input and $180 output for frontier reasoning workloads. The 1M token context window extended across the line.
The reaction inside lead generation operations was immediate and noisy. Slack channels at insurance lead aggregators, solar nationals, and AI SDR vendors filled with screenshots of the pricing page and questions about whether the AI voice qualification economics still worked. The press cycle reinforced the panic: a 2x rate card looks like a margin event when the model line was already winning over GPT-5 at $1.25 input and $10 output.
The actual exposure is smaller than the headline. Inside a typical AI voice qualification stack - speech-to-text, text-to-speech, LLM reasoning, telephony, platform fees - the LLM accounts for 10 to 20 percent of total per-minute cost. A doubling at the LLM layer translates to a 10 percent total cost increase when nothing else moves.
This analysis breaks down the new pricing landscape, the real per-call cost components, the verticals where the math still pencils against human SDRs at $1.20 to $2.10 per attempted contact, and the 90-day playbook for operators sitting on GPT-5.4 stacks.
What Actually Shipped on April 23
The GPT-5.5 rate card is the cleanest pricing comparison point in two years of LLM competition. Side-by-side with the predecessors and contemporaries, the doubling is unambiguous:
| Model | Input ($/M) | Output ($/M) | Cached Input | Context |
|---|---|---|---|---|
| GPT-5 | $1.25 | $10.00 | $0.125 | 200K |
| GPT-5.4 | $2.50 | $15.00 | $0.25 | 200K |
| GPT-5.5 | $5.00 | $30.00 | $0.50 | 1M |
| GPT-5.5 Pro | $30.00 | $180.00 | $3.00 | 1M |
| Claude Opus 4.7 | $5.00 | $25.00 | $0.50 | 1M |
| Claude Sonnet 4.6 | $3.00 | $15.00 | $0.30 | 1M |
| Claude Haiku 4.5 | $1.00 | $5.00 | $0.10 | 200K |
| Gemini 2.5 Pro | $1.25 | $10.00 | $0.125 | 1M |
| Gemini 2.5 Flash | $0.30 | $2.50 | $0.03 | 1M |
| Grok 4 Fast | $0.20 | $0.50 | n/a | 2M |
| DeepSeek V4 | $0.30 | $0.50 | $0.03 | 1M |
Source: OpenAI, Anthropic, Google, xAI, DeepSeek pricing pages as of April 24, 2026.
Three observations dominate the table. First, GPT-5.5 standard pricing now matches Claude Opus 4.7 on input and exceeds it by 20 percent on output - OpenAI explicitly priced above Anthropic’s frontier tier. Second, the cheap-and-fast layer (Haiku 4.5, Flash, Grok 4 Fast, DeepSeek V4) has separated into a distinct economic class an order of magnitude below the frontier; routing patterns no longer require fancy infrastructure to capture meaningful savings. Third, OpenAI’s 1M context window for GPT-5.5 is now table stakes rather than differentiation - Anthropic and Google match it on Sonnet 4.6, Opus 4.7, and Gemini Pro and Flash.
OpenAI framed the pricing reset around three claims: improved reasoning capability, the 1M context window, and a new tokenizer that allegedly produces fewer tokens per response on coding tasks. The token-efficiency claim is real for Codex workloads. It does not generalize to voice qualification or structured-output workflows. Independent benchmarks across function-calling pipelines and voice agent transcripts show 1.7 to 2x real cost increases versus GPT-5.4 on the same prompt corpus, because qualification dialogues are output-token-heavy rather than reasoning-token-heavy. The model produces JSON; the customer says “yes.”
For operators modeling the impact, the realistic case is the rate card. Treat the OpenAI efficiency narrative as Codex marketing.
The Per-Call Cost Stack, Decomposed
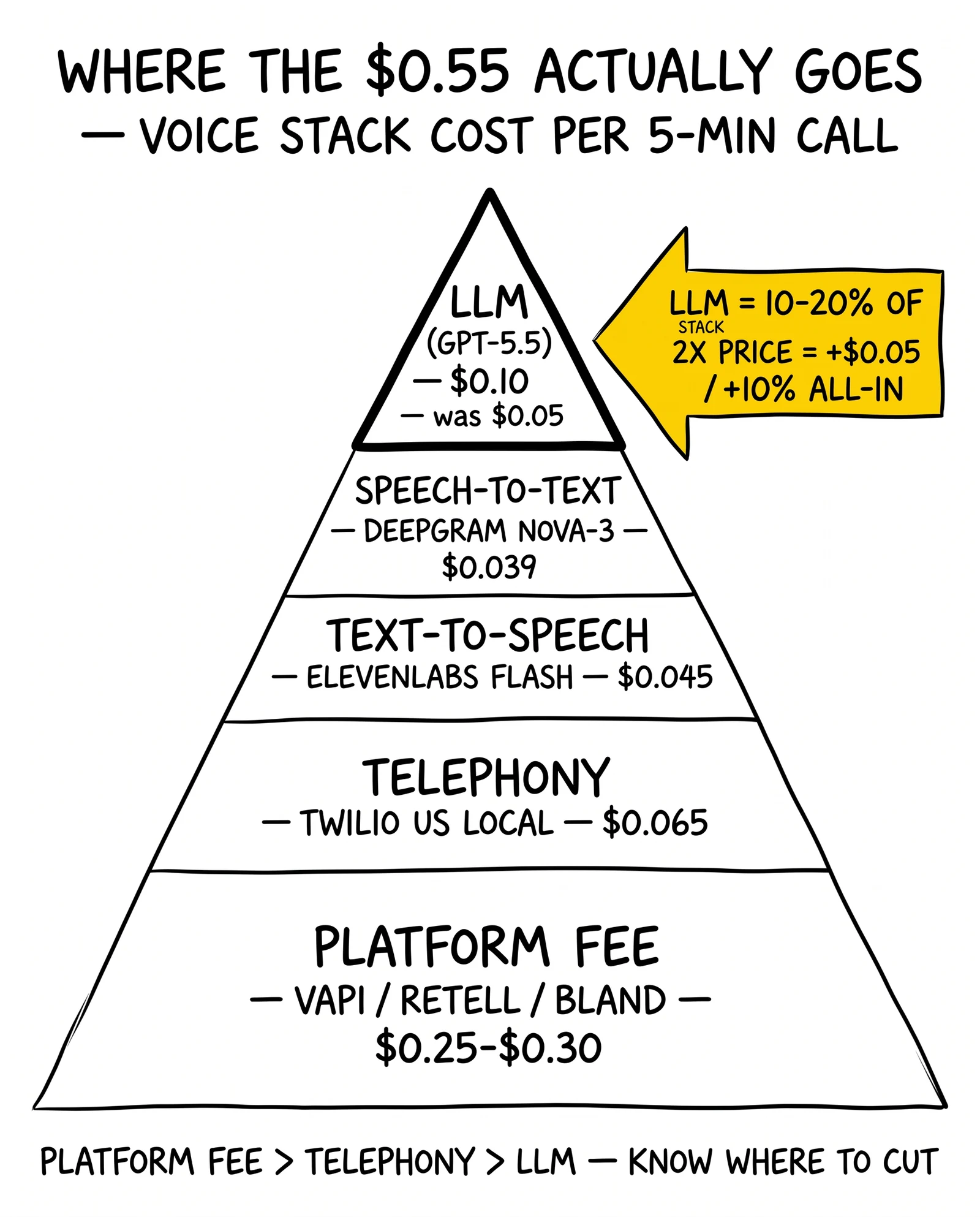
Voice qualification is not an LLM workload. It is a five-component pipeline where the LLM happens to be the most visible piece and the smallest cost line in most configurations. The stack components and their typical per-minute pricing as of April 2026:
| Component | Vendor | Per-Minute Cost | 5-Min Call Cost |
|---|---|---|---|
| Speech-to-Text | Deepgram Nova-3 | $0.0077 | $0.039 |
| Text-to-Speech | ElevenLabs Flash v2.5 | $0.05-$0.08 | $0.045 |
| LLM (GPT-5.4) | OpenAI | ~$0.010 | $0.050 |
| LLM (GPT-5.5) | OpenAI | ~$0.020 | $0.100 |
| Telephony | Twilio US local outbound | $0.014 | $0.065 (incl. inbound + recording) |
| Platform fee | Vapi / Retell / Bland | $0.05-$0.11 advertised | $0.25-$0.30 all-in |
| Total all-in (GPT-5.4) | ~$0.50 | ||
| Total all-in (GPT-5.5) | ~$0.55 | ||
| Total all-in (Haiku 4.5 router) | ~$0.51 |
Sources: Deepgram, ElevenLabs, Twilio, Vapi, Retell pricing pages as of April 24, 2026; LLM costs estimated at 1,500 input tokens and 500 output tokens per minute of conversation.
Three economic facts emerge from the stack. The platform fee dominates total cost: Vapi’s advertised $0.05 per minute resolves to $0.30 all-in once STT, TTS, LLM, and telephony pass through; Retell’s $0.07 base and Bland’s $0.11 follow the same pattern. The platform layer is where margin lives, not where buyers should look for savings unless they are willing to self-host. Telephony is the second-largest cost and the most stable - Twilio US local outbound at $0.014 per minute has not moved in three years. The LLM is the third-largest line, not the first, and its movement from $0.05 to $0.10 per call moves the all-in by a single dime.
The voice AI qualification guide on this site documented the prior cost trajectory of $0.15 to $0.25 per minute through 2024 dropping to $0.05 to $0.12 by 2026. GPT-5.5 nudges the floor of that range up by a penny per minute. Nothing about the structural economics changed.
Why the Output-Token Hike Hits Hardest
Voice qualification dialogues are output-heavy in a way most LLM workloads are not. The agent asks structured questions, produces JSON-formatted classification output for each turn, and emits TTS-ready prose - all output tokens. The customer says “yes,” “no,” or short factual answers - few input tokens. A typical five-minute qualification call runs 1,500 to 2,000 input tokens and 400 to 600 output tokens, biasing the cost mix toward the output rate.
Under GPT-5.4 pricing, that mix produced roughly $0.05 of LLM cost: 1,750 input tokens at $2.50 per million plus 500 output tokens at $15 per million yields $0.0044 plus $0.0075, or $0.012 - call it $0.05 across a five-minute conversation with multiple turns and overhead. Under GPT-5.5, the same call produces $0.10 because both rates doubled. The output-token doubling matters more than the input doubling because output tokens are 6x the rate; output growth dominates the cost line.
This dynamic explains why coding tasks see less impact than voice. Codex workloads can run input-heavy with cached prefixes for codebases and short structured outputs. Voice qualification cannot benefit from input caching at the same magnitude because each call has a unique customer context, and the output side carries most of the cost.
Where the Math Still Pencils
The relevant comparison for any AI voice qualification deployment is not GPT-5.4 versus GPT-5.5. It is AI voice versus a human SDR or call center agent answering the same lead. The fully loaded human SDR cost across US-based programs runs $1.20 to $2.10 per attempted contact: hourly wage of $22 to $32 plus benefits load of 35 percent plus floor space and management overhead of $4 to $6 per labor hour plus dialer and QA tooling at $0.30 per attempted contact, divided by 25 to 35 attempted contacts per labor hour.
AI voice at $0.50 to $0.55 per five-minute conversation runs roughly 60 to 70 percent below the loaded human SDR cost. The price hike from GPT-5.5 does not change the comparison meaningfully; it moves the AI advantage from 70 percent to 64 percent on the same conversation length.
The verticals where this comparison still favors AI voice qualification:
| Vertical | AI Voice Pencils? | Notes |
|---|---|---|
| Auto insurance | Yes | High-volume, structured questions, machine-voice tolerated |
| Home insurance | Yes | Similar profile to auto; tolerance high in non-coastal states |
| Medicare advantage | Yes (with constraints) | CMS rules require specific disclosures; AI voice handles them with logging |
| Solar | Yes | Roof ownership, shade, utility bill - all binary or short-list answers |
| Mortgage refinance | Marginal | Requires nuanced credit conversation; router pattern essential |
| Legal mass tort | No | Plaintiff vetting requires human empathy and case-value judgment |
| High-ticket B2B | No | Decision-maker contact tolerates lower automation |
| Home services | Yes | Service window, address verification, lead-grade fits short script |
The pattern is consistent: AI voice pencils when the qualification produces binary or short-list output, the dialogue runs under 90 seconds of meaningful exchange, the lead pool tolerates machine voices, and call volumes exceed roughly 800 dials per equivalent agent per month. Below that volume threshold the platform fees and engineering overhead amortize poorly. Above it, the math is structural.
The AI SDR tools guide catalogued the AI SDR vendor landscape through Q1 2026; the GPT-5.5 reset shifts the vendor economics but not the buyer math at typical volumes.
The Router Pattern: Why Haiku and Flash Matter More Now
The single most consequential operational response to GPT-5.5 is not a vendor switch. It is a routing pattern that sends low-complexity turns to a cheap model and reserves frontier reasoning for the hard turns.
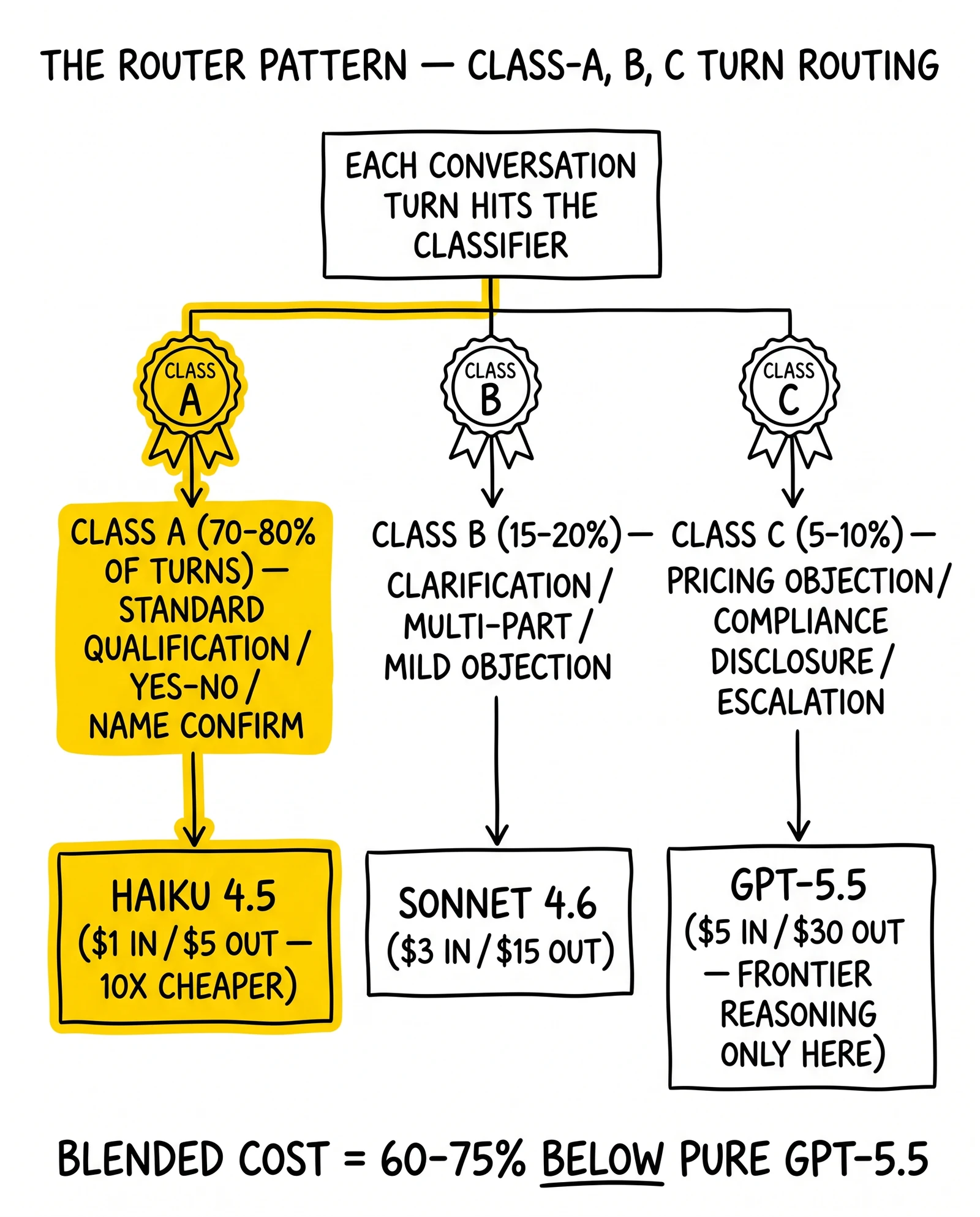
The classifier - a small, fast model running locally or via Haiku 4.5 - reads each incoming user turn and assigns it to one of three classes. Class A is standard qualification: name confirmation, simple factual questions, scripted yes/no flows. Class A turns route to Haiku 4.5 at $1 input and $5 output or Gemini 2.5 Flash at $0.30 input and $2.50 output. Class B is intermediate: clarification requests, multi-part questions, mild objection handling. Class B routes to Sonnet 4.6 at $3 input and $15 output. Class C is hard: pricing objections, compliance disclosures, escalation triggers, anything requiring careful reasoning. Class C routes to GPT-5.5 at $5 input and $30 output, or Opus 4.7 if the operator prefers Anthropic’s reasoning profile.
In production deployments across insurance and solar verticals, Class A absorbs 70 to 80 percent of conversation turns. Class B captures another 15 to 20 percent. Class C - the GPT-5.5 work - lands at 5 to 10 percent of turns. The blended LLM cost lands 60 to 75 percent below pure GPT-5.5, comfortably below the GPT-5.4 baseline.
The router pattern’s quality risk is real but bounded. Pure Haiku 4.5 deployments underperform on long contexts and multi-step reasoning, particularly in Medicare advantage where disclosure sequences interlock with eligibility logic. Pure Flash deployments degrade on objection handling. The router pattern’s strength is preserving frontier reasoning where it matters while capturing the 10x cost differential everywhere else.
Implementation cost of the router itself is modest: a small classifier model (often a fine-tuned 7B-class open-weight model running on the operator’s infrastructure) plus routing logic in the platform layer. Most production operators amortize the engineering cost over the first 60 to 90 days of operation.
The AI SDR Vendor Repricing
AI SDR vendors face a different math than voice operators. Their workloads are bursty, credit-based, and orchestration-heavy rather than per-conversation. The GPT-5.5 hike hits them through the cost-of-goods line for managed services, not through unit pricing.
11x.ai charges roughly $5,000 per month for managed AI SDR coverage, with most contracts landing in the $50,000 to $90,000 annual range. The value sits in workflow orchestration, multi-channel sequencing, and CRM integration rather than raw LLM call volume. Internal estimates suggest 11x’s gross margin compresses 3 to 5 percentage points under pure GPT-5.5 sourcing, before mitigations. The likely Q3 2026 response is product-tier separation: a router-default tier at the current price point and a premium GPT-5.5 tier at a 30 to 40 percent premium for buyers who want frontier reasoning across all turns.
Clay at $149 per month plus credits and Apollo at $49 to $59 per seat per month are insulated because their LLM consumption is bursty - users trigger enrichment, research, and outreach drafts on demand rather than in continuous flows. Credit-based pricing gives them passthrough flexibility without restructuring the rate card. Expect Clay to revise credit costs for GPT-5.5-backed workflows quietly within 60 days; Apollo’s per-seat model absorbs the hike without surface-level changes.
The agentic commerce guide on this site mapped the broader agentic-AI vendor landscape; the GPT-5.5 reset accelerates the consolidation toward router-pattern vendors and away from single-model dependents. Vendors that sourced exclusively through OpenAI face a structural disadvantage that becomes visible to buyers within two quarterly cycles.
The sales motion implication for buyers: any AI SDR vendor demo that does not address its model-routing strategy and its exposure to single-vendor LLM pricing is not ready for the post-April-23 environment. Procurement teams should add three diligence questions to every AI SDR evaluation: which models the vendor uses for which classes of work, how quickly the vendor can shift mix in response to pricing changes, and what the contractual passthrough mechanism is for upstream LLM rate increases.
Vertical-by-Vertical Repricing Math
The cost delta from GPT-5.5 lands differently across the verticals where AI voice qualification is most active. Three vertical case studies illustrate the pattern.
Insurance: The Volume Vertical
Auto and home insurance lead aggregators run the highest call volumes in lead generation - typical operations dial 25,000 to 100,000 attempted contacts per month per program. At 25,000 calls per month and a five-minute average duration, the LLM cost line moves from $1,250 per month at GPT-5.4 to $2,500 at GPT-5.5 raw. The all-in voice cost moves from $12,500 to $13,750 - a $1,250 monthly increase against a typical program revenue of $200,000 to $400,000 per month. The hit is real but absorbable. Programs that implement the router pattern recover the full delta and capture an additional $750 to $1,000 in monthly savings.
The insurance vertical’s structural advantage is qualification simplicity. The script asks for ZIP, current carrier, vehicle count or property type, and current premium. Class A turns dominate; the router pattern captures most of the conversation in Haiku 4.5 territory.
Solar: The Compliance-Aware Vertical
Solar leads carry tighter compliance requirements than insurance because of TCPA mass settlements and state-level consent rules. The script must capture explicit consent timestamps, verify roof ownership, screen for shading, and surface utility bill thresholds. The dialogue is longer - typical solar qualification runs 6 to 8 minutes rather than 5.
At a 7-minute average and 12,000 calls per month, GPT-5.5 raw adds roughly $840 per month versus GPT-5.4 - a 12 to 14 percent hit on the LLM line that translates to 1.4 percent of total program cost. The compliance-driven turns (consent capture, disclosure logging) tend to fall in Class B or C and resist routing to Haiku 4.5; solar programs capture less of the router pattern’s savings than insurance programs do, typically 40 to 55 percent of LLM cost rather than 60 to 75 percent.
The solar lead qualification reference covers the qualification flow that drives this vertical’s specific cost profile.
Legal Mass Tort: The Vertical That Does Not Pencil
Legal mass tort intake is the canonical example of where AI voice qualification does not work and where GPT-5.5 pricing is irrelevant. Plaintiff vetting requires human empathy, case-value judgment, and the ability to read distress signals in the caller’s voice. The qualification produces nuanced output - case strength, exposure level, severity, statute-of-limitations posture - rather than binary classification. Mass tort intake firms running AI voice see 30 to 50 percent quality degradation versus human intake specialists, against a per-contact cost of $5 to $15 for human intake.
Mass tort programs deploying AI for intake pre-screening - filtering obvious non-qualifiers before routing to human specialists - capture a different value. That hybrid model survives GPT-5.5 unchanged because the AI handles the high-volume reject-pile screening rather than the high-stakes qualification turns.
The 90-Day Playbook for GPT-5.4 Operators
Operators currently running GPT-5.4 voice stacks face a choice: accept the 10 percent all-in cost hike, or restructure the model layer to recover the delta. The 90-day playbook for the second path:
Days 1 through 30: Instrument and baseline. Add cost-per-resolved-conversation and cost-per-qualified-lead to the call-level telemetry. Most platform layers expose token usage but not cost; the operator must compute cost per call from the platform’s token output and the current rate card. Run a 5 percent traffic slice through pure GPT-5.5 and a parallel 5 percent through the router pattern (Haiku 4.5 + Sonnet 4.6 + GPT-5.5). Measure quality drift through standard QA frameworks - completion rate, qualification accuracy, customer satisfaction proxy (call duration, callback rate, lead-grade outcomes).
Days 31 through 60: Migrate first-turn classification. First-turn classification - the model’s initial parse of why the lead is calling and what qualification path applies - is the lowest-risk router migration. Move it to Haiku 4.5 or Gemini 2.5 Flash. Most operators capture 30 to 40 percent of the total LLM savings here without touching downstream conversation logic.
Days 31 through 60 (parallel): Migrate standard qualification turns. Class A turns identified in the routing taxonomy move to Haiku 4.5. Keep GPT-5.5 for objection handling, pricing questions, compliance disclosures, and any turn where the classifier’s confidence falls below threshold.
Days 61 through 90: Renegotiate and consolidate. Capture cached-input pricing on GPT-5.5 turns where the system prompt and routing logic stay constant. Move Batch and Flex eligible workloads (post-call summarization, lead-grade scoring, transcript classification) to the half-rate tiers. Evaluate self-hosted Llama 4 70B for high-volume static scripts where the operator has the engineering capacity to run inference. Lock vertical-specific routing rules and document the decision tree.
Operators that complete this loop hold blended LLM cost flat to 15 percent below the pre-GPT-5.5 baseline. Operators that skip the playbook absorb the 10 percent all-in increase and forfeit the structural cost-down available since Haiku 4.5 shipped at $1/$5 in late 2025.
Decision Matrix: When Voice Still Pencils Versus When Text Wins
The April 23 reset puts a sharper edge on a decision that was already coming for many programs: when AI voice qualification beats AI text qualification (chat, SMS, email-driven flows). The structural cost gap matters more after GPT-5.5 because the voice stack carries telephony, STT, and TTS layers that text qualification does not.
| Lead Profile | Voice Pencils? | Text Pencils? | Driver |
|---|---|---|---|
| High intent, time-sensitive (auto insurance quote, solar callback) | Yes | Marginal | Five-minute rule favors voice |
| Researched, low time pressure (mortgage refi, B2B SaaS demo) | Marginal | Yes | Text matches buyer behavior, lower cost |
| Compliance-heavy (Medicare, TCPA-sensitive) | Yes (with logging) | Yes (with logging) | Either works; voice carries higher disclosure cost |
| Low-volume, high-value (legal mass tort, enterprise B2B) | No | No | Human-only; AI degrades quality |
| Mass-volume, simple script (home services, lead-grade qualification) | Yes | Yes | Both work; volume threshold favors voice |
| International, language-diverse | Marginal | Yes | TTS quality varies by language; text scales cleanly |
Source: site analysis of voice-stack and text-stack cost profiles as of April 24, 2026.
The matrix yields a portfolio recommendation rather than a binary answer. Most multi-vertical lead operators run both stacks with vertical-specific routing: voice for auto, home, solar, and Medicare; text-driven for mortgage refi, B2B, and international; human-only for legal mass tort and enterprise B2B. The GPT-5.5 reset does not change which stack each vertical lands in; it sharpens the cost penalty for keeping voice in verticals where text already wins.
The chatGPT conversational qualification guide covers the text-driven side of the same decision; the AI lead scoring reference handles the post-qualification scoring layer that consumes either output.
What Procurement Should Ask Vendors Now
The post-April-23 vendor diligence surface looks different from the pre-launch one. Three questions matter more than they did two weeks ago:
Model-routing strategy. Which models does the vendor use for which classes of work? Vendors that route exclusively through GPT-5.5 carry structural cost disadvantage versus router-pattern vendors. Vendors that cannot articulate their routing strategy do not have one. Buyers should treat “we use the best model for each task” as a non-answer absent specifics.
LLM cost passthrough mechanics. How does the contract handle upstream price changes? Pre-April-23 contracts often had no passthrough provision because LLM prices had been declining for two years. Post-April-23, vendors will introduce passthrough or absorb margin compression; buyers should clarify the mechanism rather than discover it in the next renewal cycle.
Mix flexibility. How quickly can the vendor shift model mix in response to a pricing change like the one that just happened? Vendors locked into single-vendor relationships (OpenAI-only or Anthropic-only) face higher switching cost and slower response time than vendors that built routing infrastructure from day one. The structural advantage compounds across pricing cycles.
The conversation intelligence guide addressed the post-call analysis layer that often runs on the same model stack; buyers evaluating that layer should apply the same three diligence questions.
Key Takeaways
-
GPT-5.5 doubled the GPT-5.4 rate card to $5 input and $30 output per million tokens, but the all-in voice qualification cost moves only 10 percent from roughly $0.50 to $0.55 per five-minute call - because the LLM is 10 to 20 percent of the total stack cost rather than the dominant line.
-
The router pattern (Haiku 4.5 + Sonnet 4.6 + GPT-5.5) recovers the entire delta and lands below the pre-GPT-5.5 baseline. Class A turns absorb 70 to 80 percent of conversation volume at one-fifth the GPT-5.5 cost; Class C frontier-reasoning turns stay on GPT-5.5 where they matter.
-
OpenAI’s token-efficiency claim is real for Codex but not for voice qualification. Independent benchmarks show 1.7 to 2x real cost increases on output-heavy structured workflows; operators should model the rate card as the realistic case.
-
AI voice qualification still pencils against human SDRs at 60 to 64 percent cost advantage for any vertical with binary or short-list output, sub-90-second meaningful dialogue, and machine-voice tolerance: auto/home insurance, solar, Medicare, home services. Legal mass tort and high-ticket B2B remain human-only.
-
The platform fee dominates voice stack cost, not the LLM. Vapi, Retell, and Bland charge $0.25 to $0.30 all-in per minute when STT, TTS, LLM, and telephony pass through; operators looking for material cost-down should examine the platform layer before the model layer.
-
AI SDR vendor margins compress 3 to 5 percentage points under pure GPT-5.5 sourcing. Expect Q3 2026 product-tier separation: router-default tiers at current price points and premium GPT-5.5 tiers at 30 to 40 percent uplift.
-
Cached input pricing at $0.50 per million matters for voice qualification when the system prompt stays constant. Most operators capture 30 to 40 percent of GPT-5.5 input cost through caching alone, before any routing.
-
The 90-day playbook - instrument, route first-turn classification, migrate Class A turns, capture cached-input and batch tiers - holds blended cost flat to 15 percent below the pre-April-23 baseline. Operators that skip the playbook absorb the 10 percent all-in increase.
-
Procurement diligence now requires three questions about model-routing strategy, LLM cost passthrough mechanics, and mix flexibility. Vendors that cannot answer them carry structural cost disadvantage that compounds across pricing cycles.
-
Voice and text qualification stacks divide by vertical, not by preference. Voice for high-intent time-sensitive verticals; text for researched low-time-pressure verticals; human-only for low-volume high-value verticals. GPT-5.5 sharpens the cost penalty for misalignment but does not change the alignment itself.
Frequently Asked Questions
How much did GPT-5.5 actually raise voice agent costs?
Raw LLM cost per five-minute voice call moves from roughly $0.05 at GPT-5.4 to roughly $0.10 at GPT-5.5 standard pricing. All-in voice-stack cost moves from about $0.50 to about $0.55, a 10 percent total increase, because the LLM is only 10 to 20 percent of the per-minute cost. Operators using cached input pricing at $0.50 per million input tokens or batch rates at half price recover most of that delta. Routing first-turn intent classification through Haiku 4.5 at $1/$5 or Gemini 2.5 Flash at $0.30/$2.50 brings the all-in below $0.51, lower than the GPT-5.4 baseline.
What is GPT-5.5’s exact pricing compared to its predecessors?
GPT-5.5 standard pricing is $5 per million input tokens and $30 per million output tokens, with cached input at $0.50 per million and Batch and Flex tiers at half rate. GPT-5.4 was $2.50/$15 and GPT-5 was $1.25/$10. The output-side jump from $15 to $30 hits voice qualifiers hardest because qualification dialogues are output-heavy: the agent asks more questions and produces more structured JSON than the customer says back. GPT-5.5 Pro carries $30/$180 pricing for complex reasoning loads.
Does the OpenAI claim of fewer tokens per response cancel out the price hike?
Not for voice and structured-output workloads. OpenAI’s token-efficiency claims center on Codex coding tasks where the model produces tighter solutions. Independent benchmarks of voice qualification, structured JSON extraction, and function-calling pipelines show 1.7 to 2x real cost increases versus GPT-5.4 on the same prompt set. Operators running production voice agents should model the price doubling as the realistic case, not the OpenAI marketing case. Codex users see the efficiency gains; voice and SDR operators see the rate card.
When does AI voice qualification still pencil against human SDRs?
AI voice qualification pencils against human SDRs whenever attempted-contact volume exceeds roughly 800 dials per agent per month and qualification scripts run under 90 seconds of meaningful dialogue. Human SDRs cost $1.20 to $2.10 per attempted contact fully loaded - hourly wage plus floor space plus management plus benefits plus dialer plus QA - across US-based programs. AI voice at $0.50 to $0.55 per five-minute conversation pencils for any vertical where leads tolerate machine voices and where the qualification yields binary or short-list output. Insurance, solar, and Medicare clear that bar; legal mass tort and high-ticket B2B do not.
Should operators switch to Claude Haiku 4.5 or Gemini Flash to cut LLM costs?
Yes for first-turn classification and routing, no for full-conversation handling on warm verticals. The router pattern uses Haiku 4.5 at $1/$5 or Gemini 2.5 Flash at $0.30/$2.50 to handle 70 to 80 percent of low-complexity turns and escalates to GPT-5.5 only when the conversation hits objection-handling, pricing questions, or compliance-sensitive disclosures. This cuts LLM blended cost by 60 to 75 percent without a measurable quality drop on standard insurance or solar qualification flows. Pure Haiku 4.5 stacks underperform on long contexts and multi-step reasoning, so the router stays the dominant pattern through Q3 2026.
What is the real cost breakdown of a five-minute AI voice qualification call?
A typical five-minute call breaks down as STT at roughly $0.039 (Deepgram Nova-3 at $0.0077 per minute), TTS at roughly $0.045 (ElevenLabs at $0.05-$0.08 per minute, blended), LLM at $0.05 to $0.10 depending on model, telephony at roughly $0.065 (Twilio US local outbound at $0.014 per minute plus inbound and recording), and platform fee at $0.25 to $0.30 depending on whether the operator uses Vapi, Retell, or a self-hosted stack. The all-in lands at $0.50 with GPT-5.4, $0.55 with GPT-5.5, or $0.51 with a Haiku-routed hybrid.
Why did OpenAI double pricing on April 23, 2026?
OpenAI cited improved reasoning capability and 1M context window availability across the GPT-5.5 line as justification, paired with an internal compute-cost narrative around the new tokenizer and longer context attention. Industry consensus reads the move differently: GPT-5.5 is a margin reset after two years of price competition with Anthropic, Google, and DeepSeek. The Pro variant at $30/$180 signals OpenAI’s intent to capture frontier-reasoning workloads at premium pricing while ceding the commodity layer to Haiku, Flash, and DeepSeek V4.
Does the 1M context window justify the GPT-5.5 price for voice qualification?
Rarely. Voice qualification calls produce 3,000 to 8,000 tokens of total context across a five-minute conversation, well under the 200K context window of GPT-5.4. The 1M window matters for document-heavy enterprise agents handling long policy ingestion or multi-call buyer histories - not for first-touch qualification. Operators paying GPT-5.5 prices for voice qualification subsidize a context capacity they cannot use. The exception is enterprise SDR fleets that load full CRM histories, prior call transcripts, and product catalogs into every prompt - a workload pattern still under 5 percent of the AI SDR market.
What is the 90-day playbook for operators currently running GPT-5.4 voice stacks?
Days 1-30: instrument cost-per-resolved-conversation and cost-per-qualified-lead at the call level, then run a Haiku 4.5 router A/B against pure GPT-5.5 on a 5-percent traffic slice to measure quality drift. Days 31-60: migrate first-turn classification and standard qualification turns to the router, keeping GPT-5.5 for objection handling and disclosures. Days 61-90: renegotiate platform contracts to capture cached-input and batch pricing, evaluate self-hosted Llama 4 70B for high-volume static scripts, and lock vertical-specific routing rules. Operators that complete this loop hold blended cost flat or below the pre-GPT-5.5 baseline.
What happens to AI SDR vendor pricing now?
AI SDR vendors face a margin squeeze. 11x.ai charges roughly $5,000 per month for managed AI SDR coverage, with most of the value in workflow orchestration rather than raw LLM calls; the GPT-5.5 hike compresses their gross margin by 3 to 5 percentage points unless they pass it through. Clay at $149 per month plus credits and Apollo at $49 to $59 per seat per month are insulated because their LLM-heavy workloads are bursty and credit-based rather than per-conversation. Expect 11x.ai-class managed vendors to introduce a router-default tier and a premium GPT-5.5 tier within Q3 2026, separating buyers by willingness to pay for frontier reasoning.
The April 23 reset will be remembered less for the price hike itself than for what it forced into the open. AI voice qualification economics survived the doubling because the LLM was never the dominant cost line; the platform fee and telephony layer were and remain so. AI SDR vendor strategies survived in proportion to their routing infrastructure - vendors that built mix flexibility from day one absorbed the change quietly, vendors that did not will surface the constraint in the next renewal cycle. The structural lesson for buyers and operators is that single-model dependency is the underlying risk, not any specific model’s pricing. The router pattern, cached-input discipline, and vertical-specific stack alignment are what keep the math working through whatever comes after GPT-5.5.
Sources
- OpenAI, “Introducing GPT-5.5,” openai.com, April 23, 2026 - https://openai.com/index/introducing-gpt-5-5/
- OpenAI, “API Pricing,” openai.com, retrieved April 24, 2026 - https://openai.com/api/pricing/
- OpenAI, “Platform Pricing Documentation,” platform.openai.com, retrieved April 24, 2026 - https://platform.openai.com/docs/pricing/
- Anthropic, “Claude API Pricing - Haiku 4.5, Sonnet 4.6, Opus 4.7,” platform.claude.com, retrieved April 24, 2026 - https://platform.claude.com/docs/en/about-claude/pricing
- Google, “Gemini API Pricing - 2.5 Pro and Flash,” ai.google.dev, retrieved April 24, 2026 - https://ai.google.dev/pricing
- Deepgram, “Pricing - Nova-3 Speech-to-Text and Aura-2 Text-to-Speech,” deepgram.com, retrieved April 24, 2026 - https://deepgram.com/pricing
- ElevenLabs, “Pricing - Flash v2.5 and Multilingual TTS,” elevenlabs.io, retrieved April 24, 2026 - https://elevenlabs.io/pricing
- Twilio, “Programmable Voice Pricing - United States,” twilio.com, retrieved April 24, 2026 - https://www.twilio.com/en-us/voice/pricing/us
- Retell AI, “AI Voice Agent Pricing - Full Cost Breakdown 2026,” retellai.com, March 2026 - https://www.retellai.com/blog/ai-voice-agent-pricing-full-cost-breakdown-platform-comparison-roi-analysis
- CloudTalk, “How Much Does Voice AI Cost - 2026 Pricing Breakdown,” cloudtalk.io, Q1 2026 - https://www.cloudtalk.io/blog/how-much-does-voice-ai-cost/
- Landbase, “11x.ai Pricing 2026 - Plans and Costs Breakdown,” landbase.com, Q1 2026 - https://www.landbase.com/blog/11x-ai-pricing