HUMAN Security’s analysis through April 2026, published across two HUMAN posts (the Black Friday-Cyber Monday agentic-commerce traffic analysis and the AI Agents Carding Attack Breakdown), documented a 6,900% increase in agent and agentic-browser request volume since January 2025 and observed Perplexity Comet producing checkout-page patterns that resemble early-stage carding – rapid card additions, repeated payment attempts, fallback to loyalty-point redemption. The same agent traffic class is likely to appear, and in some operator telemetry already appears, on insurance and auto quote forms. Lead generation fraud detection, built for a human-or-script binary world, needs a third category – and lead buyers need contractual language for what counts as a billable lead when an agent fills the form.
Where the WebMCP browser runtime analysis and the tool-defined lead capture piece treat agentic browsers as a capture surface to instrument, and the agentic commerce overview treats agents as a buyer-side workflow shift, this analysis treats the same products – Perplexity Comet and ChatGPT Atlas – as a fraud and form-abuse vector that breaks existing lead-validation taxonomies.
A 6,900% Growth Curve That Crossed Into Lead Generation in Q1 2026
The number HUMAN Security put on the curve was the kind of figure that gets cited in conference keynotes and industry-press headlines and then quietly absorbed without anyone working out what it actually means downstream. From January 2025 to early 2026, agent and agentic-browser request volume across the web sites HUMAN monitors grew by approximately 6,900 percent. Black Friday-Cyber Monday 2025 agent traffic to e-commerce sites surged 144.7 percent year over year. Most of the public discussion treated this as a search-and-discovery story – AI assistants summarizing product pages, comparison shopping on behalf of users, occasionally replacing a click that would have gone through traditional organic search.
That framing missed the operational story. Inside the same traffic curve, HUMAN’s analysts documented Perplexity Comet – the agentic browser Perplexity launched in mid-2025 – producing patterns on e-commerce checkout pages that closely resembled the early stages of what fraud teams have classified for two decades as carding. Rapid sequences of card additions and removals on a cart. Repeated payment attempts with small variations. Fallback to loyalty-point redemption when a card transaction failed. None of these patterns, taken individually, prove malicious intent. Taken together, they describe the behavioral signature that bot-mitigation platforms have used to identify card-testing operations since the early 2010s.
For the lead generation industry, the question is no longer whether this matters. The question is which week in 2026 the same patterns cross from Shopify checkout into insurance, mortgage, solar, and auto lead forms – and whether the existing fraud detection stack can tell the difference between a Comet session that was instructed by a verified human shopper to compare auto insurance quotes and a Comet session being driven by an actor who scraped a target list and is testing form fields for downstream identity-fraud workflows. The answer to the second question, based on the detection capabilities currently shipping in the major lead-validation platforms, is mostly no. This analysis covers what HUMAN’s findings actually documented, why agentic-browser traffic forces a third category between “human” and “bot” in fraud taxonomies, what the detection surfaces exposed by Comet and ChatGPT Atlas look like in lead-form telemetry, and what contractual language lead operators and buyers need to negotiate before Q3 2026.
What HUMAN Security Actually Documented, and Why It Reads Differently for Lead Generators
HUMAN Security’s research, summarized through trade press coverage in April 2026, focused on e-commerce as the primary observation surface. The dataset combined the company’s own bot-management telemetry – which sits in front of a substantial slice of the consumer web – with checkout-flow analysis at retailer customers. The 6,900 percent growth figure measures request volume from clients identified as agentic-browser sessions or as agent-mediated headless instances. The Black Friday-Cyber Monday 144.7 percent surge measures agentic traffic specifically against the November-December 2025 retail peak.
The carding-resembling pattern is the part that has made the rounds in security circles without making it into lead generation conversations. HUMAN’s analysts described Comet sessions that, after being instructed by users to complete purchase flows, repeatedly added and removed payment instruments, retried failed transactions with minor variations in form data, and fell back to non-card redemption paths (gift cards, loyalty points) when card paths failed. The behavior was not necessarily fraudulent. In many of the documented sessions, the underlying user mandate was legitimate – a shopper asking the agent to find a deal and complete a purchase. What HUMAN flagged was that the behavioral signature of those legitimate sessions was indistinguishable, at the request-pattern level, from the signature of card-testing operations that bot-mitigation platforms have been blocking for years.
For e-commerce platforms, the immediate consequence is a detection-tuning problem: how to keep blocking actual carding without false-positiving the agent-mediated legitimate shoppers. For lead generation, the consequence is more structural. Lead operators do not have a “blocking” decision to make in the same way a checkout system does. The operator has a “is this a billable lead” decision and a “did this submission carry valid consent” decision. Both decisions depend on a fraud taxonomy that was built around a binary distinction between humans and scripts. Agent-mediated submissions are neither. They are produced by software but carry – at least notionally – a human user mandate. The question of whether they count, under existing TCPA and lead-buyer contractual frameworks, as human-originated submissions is unresolved.
The composition of the 6,900 percent number
It matters, for operational planning, to understand what kinds of requests the 6,900 percent figure is actually measuring. HUMAN’s reporting clusters the growth across three categories. The first is “agentic browser” sessions in the strict sense – Comet, ChatGPT Atlas, and analogous products that ship a browser surface with an embedded agent. The second is API-mediated agent activity that hits public websites without an embedded browser, typically routed through headless Chromium with agent-controlled inputs. The third is what HUMAN’s analysts have referred to as “tool-using model” sessions, where an LLM-driven workflow makes HTTP requests to a website as part of a larger task chain – a category that overlaps with the first two but is technically distinct.
For a lead generation operator looking at form-submission telemetry, the most important point about this composition is that the three categories present different fingerprints. A Comet session presents user-agent strings that include the Comet identifier and a Chromium fingerprint that follows recent stable Chromium TLS and HTTP/2 conventions. A ChatGPT Atlas session presents a user-agent string that has been documented in favicon-fetch logs as including “ChatGPT Atlas” alongside CFNetwork and Darwin signatures characteristic of macOS clients. An API-mediated agent session may present a generic Chromium user agent or, in some cases, a user-agent string that the model was instructed to use. A tool-using model session may not even maintain consistent user-agent identity across requests.
What this means for bot detection on lead forms is that the detection surface is not a single signal but a layered one. The user-agent string is the easiest signal to capture and the easiest for an attacker to spoof. TLS fingerprinting and HTTP/2 frame ordering provide harder-to-spoof signals but require infrastructure most lead-form vendors do not yet ship. Behavioral signals – typing dynamics, mouse-movement patterns, viewport and scroll behavior – provide the most resistant detection, but they are also the signals most likely to false-positive on legitimate agent-mediated sessions because, by definition, a Comet or Atlas session has no human keystrokes or mouse movement to capture.
Why “resembling early-stage carding” is the load-bearing phrase
The phrasing HUMAN’s analysts settled on – “resembling early-stage carding” – is doing real work. The verb is “resembling,” not “is.” The qualifier is “early-stage,” not “active.” The choice of words reflects the genuine ambiguity in the data. The patterns observed match the signature of fraud-precursor activity, but the underlying intent of any given session was, in many cases, ordinary commerce instructed by a real user. The risk is not that every Comet session is a carding session. The risk is that the population of actors who want to do actual carding now have a new vector – an AI browser whose default behavioral profile happens to match their attack pattern – and that the legitimate-traffic noise floor will mask the malicious signal until detection platforms develop a means to separate the two.
For lead generation, the analogous risk is not that every Comet form fill is fraud. It is that actors who want to abuse insurance, mortgage, or solar lead forms now have a tool whose default fill behavior produces submissions that will pass most existing lead-quality control checks – and that the legitimate-agent population will produce so much background volume that the malicious population becomes statistically harder to isolate.
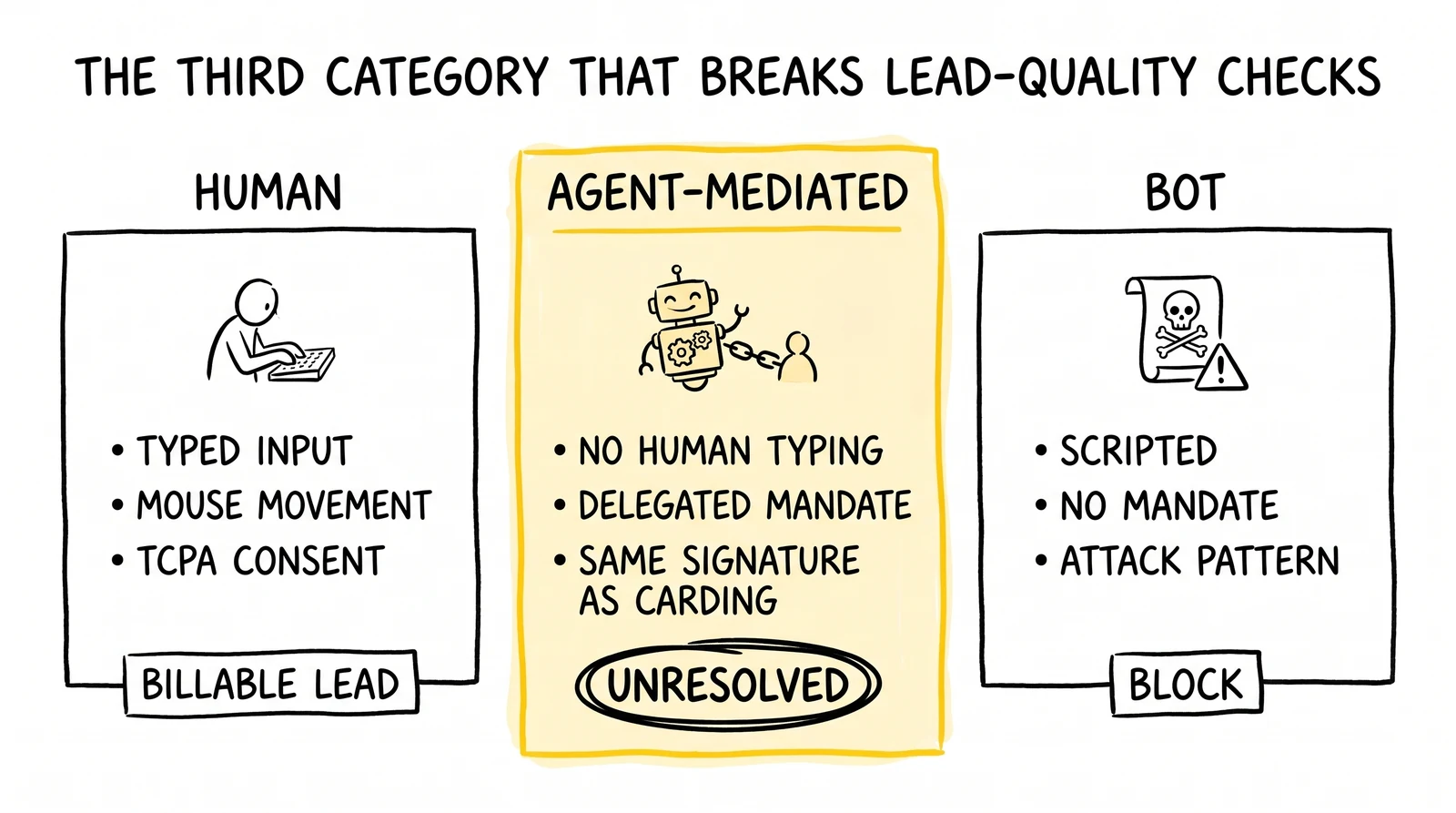
The Three-Category Problem: Human, Bot, and Something Else
The fraud detection vocabulary that lead generation has built over the last fifteen years rests on a binary distinction. There are humans, who fill out forms with their own keystrokes and consent, and there are bots, which is shorthand for any automated client that produces a form submission without a corresponding human consent event. Detection platforms – TrustedForm, Jornaya, Anura, the various proprietary tools at the larger lead aggregators – were architected around this distinction. The cert produced by TrustedForm, the LeadiD captured by Jornaya, the score produced by Anura: each is, at its core, a confidence assertion about the binary classification of “human-authored” versus “automated.”
Agentic-browser submissions break the binary in two distinct ways.
The first way is technical. A Comet session does not produce keystrokes in the form fields. It does not produce mouse movement. It does not, depending on the operating mode, render the page in a visible browser window in front of a human user. From the perspective of session-evidence-capture tools that record the consent moment as a video-style replay, a Comet session looks like a script – and would, under default settings, be flagged as such. From the perspective of behavioral-analytics tools that score sessions on typing dynamics and pointer behavior, a Comet session has no behavior to score.
The second way is contractual and definitional. The legal frameworks that govern lead generation – TCPA in the federal context, the various state-level “mini-TCPA” statutes that proliferated through 2024 and 2025, and the contractual definitions that lead buyers use to define a “billable lead” – were written assuming that the question to be answered was whether a human had filled the form. They were not written assuming a third condition: that an agent acting under a user’s mandate had filled the form on behalf of a human who never personally entered the data but whose signature on a prior agent-authorization gave the agent legitimate authority to act.
There is no settled answer in the case law to whether an agent-completed lead submission satisfies the consent capture requirements of TCPA or of the various state statutes. There is no settled answer in industry contracts to whether such a submission counts as a billable lead. Operators and buyers are negotiating the question on a deal-by-deal basis through Q1 and Q2 2026, and the answers diverge widely. The result is a contractual minefield in which two operators selling to the same buyer can have entirely different obligations on the same incoming agent submission.
The categories that need to exist
The framework that resolves the binary problem requires three categories rather than two:
- Human-authored: A submission produced by a human directly interacting with the form via keyboard, pointer, and viewport. The legacy “human” category, which is what TrustedForm certs and Jornaya LeadiDs have been certifying since their inception.
- Agent-authored, human-mandated: A submission produced by an AI agent (Comet, Atlas, or analogous) acting under an instruction from a verified human user whose intent matches the form’s purpose. The user did not directly fill the form, but the agent’s action was authorized by the user.
- Automated, no human mandate: A submission produced by a script, headless browser, or API client without any verified human authorization. The legacy “bot” category, which existing fraud detection blocks as a matter of course.
This three-category framework is workable in concept. Operationalizing it is harder. The technical signals that distinguish category one from category two are clear enough – user-agent strings, TLS fingerprints, behavioral absence patterns. The technical signals that distinguish category two from category three are far less clear. In both cases, the submission was produced by software. In both cases, the underlying claim of “human mandate” is asserted, not proven. The platforms that today certify the binary distinction – TrustedForm and Jornaya in particular – will need to extend their certification frameworks to include an “agent-mandated” cert, and the verification logic for that cert is an unresolved engineering and policy question.
What is clear is that the operators and buyers who continue to operate on the binary framework through 2026 will accumulate two specific exposures. They will reject category-two submissions that should have been billable, losing margin. And they will accept category-three submissions that the actor crafted to look like category two, taking compliance and quality losses that the existing detection layer was not designed to catch.
The Detection Surfaces Comet and Atlas Actually Expose
Before discussing what to build, it helps to be specific about what the agentic browsers actually expose at the network and application layer. The discussion below is based on publicly documented behaviors of Perplexity Comet and OpenAI ChatGPT Atlas as of April 2026, supplemented by industry-press reporting on observed traffic patterns. None of this is exhaustive, and the products are evolving rapidly; operators should validate current behavior against their own telemetry before relying on any specific signal.
Comet: the comet://extensions/ exposure and TLS fingerprint
Perplexity Comet ships as a Chromium-based browser with an embedded agent layer. Its user-agent string follows Chromium conventions but typically includes a “Comet” identifier or a Perplexity-attributed string in environments where the agent is the active driver. Independent security research published through early 2026 has documented that Comet exposes a comet://extensions/ internal URL surface that is reachable in some configurations from agent-driven flows, raising distinct security questions about extension installation and permissioning in agent-driven contexts. For lead-form operators, the practical signal is that a TLS fingerprint matching recent Chromium stable plus a user-agent string with Comet or Perplexity attribution is a high-confidence indicator that the session is agent-mediated rather than human-driven.
The behavioral signature is more diagnostic than the user-agent string for the same reason that any user-agent-only detection is brittle: the string is trivial to spoof. What is harder to spoof is the absence pattern – no mouse movement, no keystroke timing, no scroll micro-behavior, no field-focus dwell – combined with a navigation pattern that arrives at the form through programmatic URL loads rather than through a referrer chain that includes search-engine intermediation. A session that produces all of those absence signals plus a Comet-attributed user agent is, for practical purposes, an agentic-browser session.
ChatGPT Atlas: the favicon-fetch CFNetwork/Darwin signature
OpenAI’s ChatGPT Atlas, launched in late 2025 and expanding through Q1 2026, presents a different fingerprint. Researchers analyzing favicon-fetch logs from public websites have documented Atlas requests with user-agent strings that include “ChatGPT Atlas” alongside CFNetwork and Darwin signatures characteristic of macOS-native clients. The CFNetwork/Darwin combination indicates that the underlying network stack is the macOS-native networking layer rather than a Chromium HTTP/2 implementation, which produces a TLS fingerprint distinct from any Chromium-based browser.
For lead-form telemetry, this matters because most existing bot-detection rules were tuned against either Chromium-based legitimate-browser fingerprints or against headless-Chromium attacker fingerprints. A native-macOS-stack agent does not match either profile. Detection systems that rely on Chromium-only fingerprint catalogs will, in default configuration, classify Atlas sessions as either suspicious (because they do not match a known browser profile) or as benign (because they do not match a known attacker profile). Neither classification produces the right operational outcome – which is to identify the session as agent-mediated and route it to the appropriate handling path.
The behavioral signal that survives spoofing
User-agent strings can be spoofed. TLS fingerprints can be partially spoofed with sufficient effort. What is harder to spoof is the multi-dimensional behavioral signature that emerges when an agent fills a form. Specifically, the agent session typically:
- Loads the form page programmatically, often without a search-referrer chain matching organic traffic
- Issues field-fill events as discrete DOM operations rather than as keystroke sequences
- Submits the form within a narrow time window after page load (often under a second), versus a typical human session that includes multiple seconds of read time
- Does not produce mouse-movement, scroll, or viewport-resize events between page load and submission
- May produce JavaScript execution traces that match agent-controlled puppeteer, playwright, or proprietary instrumentation rather than human-driven Chromium
A detection rule that combines two or three of these signals, weighted, produces a high-confidence agent-session classification that is independent of whether the user-agent string was spoofed. This is the rule logic that the major lead-validation platforms – TrustedForm, Jornaya, Anura – will need to ship as part of their 2026-2027 detection updates, and that the operators with internal validation systems should be building now rather than waiting for vendor updates.
The challenge, again, is that this rule logic correctly identifies agent sessions but does not, on its own, distinguish human-mandated agent sessions from no-mandate agent sessions. That distinction requires either signed agent-mandate attestations from the agent platform (which neither Perplexity nor OpenAI ship in any standardized form as of April 2026) or out-of-band verification of the human user behind the agent (which raises its own privacy and friction trade-offs).
What This Means for Insurance, Mortgage, Solar, and Auto Lead Buyers Specifically
The translation from HUMAN’s e-commerce findings to lead generation is not abstract. The lead verticals that face the most immediate exposure share three characteristics: high per-lead pricing that creates an attacker incentive, form architectures that capture personally identifiable information sufficient for downstream identity workflows, and existing fraud-detection stacks that were tuned against human-or-script binary classification.
Insurance: the highest immediate exposure
Auto and home insurance lead pricing in 2026 sits in the $20-$80 range for shared leads and substantially higher for exclusive verticals. The forms capture name, address, date of birth, driver’s license number in some flows, current policy information, and claim history. From an attacker’s perspective, the data is more useful for identity-fraud assembly than the e-commerce checkout data HUMAN observed. From a defender’s perspective, the form telemetry is captured by TrustedForm or Jornaya in nearly every commercial flow, but the cert framework was designed around human authorship and does not, in default configuration, distinguish agent-mediated sessions.
For insurance lead operators specifically, the next-quarter exposure is two-fold. First, the false-negative case: agent submissions that are flagged as human-authored, billed to the buyer, and then fail downstream verification (phone match, address validation, vehicle-VIN cross-check) at higher rates than human-authored submissions, producing chargeback exposure and quality-tier degradation. Second, the false-positive case: human-mandated agent submissions where the underlying consumer is genuinely shopping for insurance via an agent, the submission carries valid consent under the agent’s authorization, and the lead is rejected as suspected fraud – losing margin and producing a customer-experience problem that propagates back through the buyer’s reputation.
Mortgage: the contractual minefield
Mortgage lead generation is the vertical where the contractual ambiguity is most acute. Mortgage lead buyer contracts typically define billable leads with reference to “consumer-initiated” submissions and to the captured cert from TrustedForm or Jornaya. The phrase “consumer-initiated” was not drafted with agent-mediated submissions in mind. A submission filled by Comet under a user mandate is, under one reasonable reading, consumer-initiated; under another reasonable reading, it is not. The cert evidence captured at the moment of submission shows agent activity, not consumer activity.
For mortgage operators selling into lender networks, the practical near-term step is to revisit billable-lead definitions and to negotiate explicit language for agent-mediated submissions before the volume forces the issue retroactively. Operators who do not negotiate this language are accepting whatever interpretation the buyer’s compliance team adopts when chargebacks start accumulating, and the historical pattern in lead-generation contractual disputes is that ambiguity resolves against the seller. The same dynamic that drove the bot-leads detection negotiations two years ago will drive the agent-leads negotiations through 2026.
Solar and home-services: the velocity vector
Solar and home-services lead pricing, while lower per lead than mortgage or insurance, runs at higher volume and faster qualification cycles. The exposure pattern is different. Attackers using agent infrastructure to assemble solar lead submissions are likely to be optimizing for installer-network access – generating submissions that look qualified enough to be routed to an installer, then either harvesting installer outreach for downstream fraud or testing field validation logic to assemble cleaner identity packages.
The detection challenge for solar specifically is that the legitimate use case for agent-mediated solar lead submissions is real and growing. Consumers using AI agents to research solar installation, compare pricing across providers, and submit quote requests on their behalf are a fast-growing segment. The fraud detection framework that classifies all agent submissions as suspect will reject this segment along with the malicious population, ceding the segment to operators with more sophisticated classification.
Auto: the OEM-direct lead pricing pressure
Auto lead generation – both for OEM-direct programs and for marketplace aggregators – has been under sustained pricing pressure since 2024 as OEMs concentrated their digital-marketing spend and tightened lead-quality requirements. The introduction of agent-mediated submissions adds a new dimension to the quality conversation. OEMs and large dealer groups will quickly require contractual language that addresses agent-mediated submissions, either by excluding them from the billable-lead pool or by requiring additional certification beyond the existing TrustedForm and Jornaya frameworks.
The operators who anticipate this and build agent-classification capability into their delivery pipeline will be able to accept OEM contracts that exclude unverified agent submissions while continuing to monetize verified-mandate agent submissions through alternative buyer channels. The operators who do not build the classification capability will be forced to accept contractual exclusions that cap a growing share of their inbound traffic.
The Approaches That Will Underperform
Three responses to the HUMAN Security findings and the broader agent-traffic environment are visible in industry conversations through April 2026. Each will produce worse outcomes than its proponents expect.
The first is the “block all agents” posture. The argument is that lead generation contractual frameworks were not built for agent-mediated submissions, that classification accuracy is too uncertain, and that the safest defensive response is to reject any session identified as agent-mediated. The problem with this posture is that the legitimate agent population is growing faster than the fraud-actor agent population. Cloudflare bot-management telemetry and analogous public datasets show that AI agents are projected to account for an increasing share of all web traffic over the next 24 months. Operators who block all agent traffic will, within two to three quarters, be blocking a meaningful share of legitimate inbound submissions – and the buyer side of the market will not reward this conservatism with higher pricing on the human-only inventory that remains. The posture trades current uncertainty for future revenue compression.
The second is the “accept all agents” posture. The mirror image of the first. The argument is that agent-mediated submissions carry user mandates, that the legitimate use case predominates, and that classification overhead is not worth the cost. The problem is that this posture allows category-three (no-mandate) submissions to flow through the lead pool unflagged, producing chargeback exposure at the buyer side and propagating fraud signal into downstream verification systems. Within a one-to-two-quarter window, the buyer side of the market will reprice inventory from operators who do not classify, and the operators running the accept-all posture will see margin compression both from increased chargebacks and from buyer-side bid degradation.
The third is the “wait for the vendor update” posture. The argument is that TrustedForm, Jornaya, Anura, and the other major lead-validation platforms will ship agent-detection updates within 2026, and that operators should wait for the vendor capability rather than building internal classification. The problem is that the vendor updates, when they ship, will be tuned against the broad market and will produce classification thresholds that may not match any specific operator’s risk profile. Operators who run differentiated risk strategies – willing to accept higher false-positive or false-negative rates in specific segments to maximize margin – will need to operate above the vendor classification layer regardless of when the vendor capability ships. The wait-and-see posture trades a quarter or two of uncertainty for a long-term capability gap that competitors who built earlier will use to extract margin.
The common pattern across these three approaches is the same: each treats the agent traffic question as a single binary decision rather than as a multi-axis classification and routing problem. The operators who build the classification and routing capability – even imperfectly – capture the margin window that the wait-and-see and binary-blocking operators give up.
A Practitioner Framework for Agent-Aware Fraud Detection
The framework that resolves the three-category problem in operational practice rests on four design principles. None of them is a single-vendor purchase. All of them require the operator to take the integration and classification work in-house, at least at a configuration level, even when underlying signals are sourced from third-party platforms.
Principle one: capture the agent signal explicitly, do not infer it
The first principle is that the operator’s lead-validation pipeline should capture and persist explicit signals about whether each submission was agent-mediated, rather than inferring agent activity from the absence of human signals. This means logging the user-agent string, the TLS fingerprint where the operator’s infrastructure can capture it, and the behavioral telemetry that distinguishes agent and human sessions. The captured signals should be tagged on the lead record itself, not inferred at billing time.
This is a non-trivial pipeline change for many operators, who currently rely on TrustedForm or Jornaya certs as the entire fraud-evidence layer. The cert is necessary but not sufficient under the three-category framework. Operators need their own captured signals that they can apply their own classification logic to, separate from the cert provider’s classification.
Principle two: classify, then route, do not block
The second principle is that classified-as-agent submissions should be routed to a separate handling path, not blocked. The handling path should include a higher verification threshold, a different buyer-tier mapping, and a distinct contractual representation to the buyer. A category-two submission (agent-authored, human-mandated) routed to a buyer who has accepted agent submissions under negotiated language, with appropriate verification, is a billable lead. The same submission routed to a buyer who has not accepted agent submissions is a charge-back risk and should be held back.
This principle requires the operator to maintain per-buyer configuration of which categories each buyer accepts, and to operate the routing engine with that configuration in real time. This is more complex than the legacy single-routing model but is the only configuration that captures the value of the legitimate agent population without taking the chargeback exposure of the no-mandate population.
Principle three: contract the language before the volume forces the issue
The third principle is that the contractual definition of a billable lead should be revisited and renegotiated in advance of agent-traffic volume becoming a forcing event. Operators who wait for the first chargeback dispute to introduce the contractual question are negotiating from a weaker position than operators who introduce the question proactively in a quarterly business review.
The specific language to negotiate covers: (a) whether agent-mediated submissions are accepted as billable; (b) what evidence is required to assert that an agent submission carried a user mandate; (c) how chargeback rights apply to agent-classified submissions versus human-classified submissions; (d) what rights the buyer has to audit the operator’s classification logic; and (e) how disputed-classification submissions are reconciled. Each of these terms is straightforward to discuss when introduced in a planning context and contentious to discuss when introduced in a chargeback context.
Principle four: invest in detection that survives spoofing
The fourth principle is that the detection logic should rely on signals that survive spoofing rather than on signals that an attacker could trivially modify. User-agent strings are the most spoofable signal and should not be the primary classification input. TLS fingerprints are harder to spoof and provide a more durable signal. Behavioral signals – the absence patterns described earlier – are the hardest to spoof for an actor running an actual agent, because the agent’s default behavior is what produces the absence pattern in the first place.
This argues for investing in conversation- and session-intelligence layers that capture multi-dimensional behavioral signals and apply weighted classification logic, rather than relying on user-agent rules that an actor will defeat as soon as the rules are widely deployed. The detection capability is not a single product purchase; it is a configuration discipline that combines vendor signals with operator-side behavioral capture and weighted classification.
Implementation Reality: What It Actually Takes
The strategic framework is straightforward in concept. The implementation is harder than most operators expect, for reasons that mirror the implementation patterns seen in earlier waves of fraud-detection upgrades.
Resource requirements
A lead operator implementing agent-aware fraud detection should plan for three categories of investment.
The first is signal capture. The operator’s form-handling infrastructure needs to capture user-agent, TLS fingerprint where possible, and a comprehensive set of behavioral signals from the form session. For operators using a hosted form provider that captures only the cert from TrustedForm or Jornaya, this requires either upgrading to a form-provider configuration that exposes the additional signals or building a parallel telemetry capture layer. Engineering effort: 30-60 days for operators with internal form infrastructure; 60-120 days for operators dependent on hosted form providers.
The second is classification logic. The captured signals need to feed a classification engine that produces a category assignment for each submission. The engine can be rule-based at first (combining user-agent matches, TLS fingerprint matches, and behavioral-absence thresholds) and can be upgraded to a learned classifier as labeled training data accumulates. Engineering effort: 20-40 days for an initial rule-based engine; ongoing work for tuning and learning-classifier upgrades.
The third is buyer-side routing and contracting. The classification output needs to feed a routing engine that maps category assignments to buyer-tier configurations, and the operator needs to negotiate the contractual language with each buyer that defines how each category is treated. Engineering effort for routing: 20-40 days. Commercial effort for buyer renegotiation: dependent on buyer count and cycle, typically 60-120 days for an operator with twenty to fifty buyers.
The combined timeline for a mid-sized operator running existing TrustedForm or Jornaya integrations is typically four to six months from project start to first agent-classified leads flowing through the renegotiated buyer contracts. The operators who began this work in Q1 2026 will be in production by mid-2026; the operators starting in Q2 2026 will be in production by Q4. The operators who delay past Q3 2026 will be implementing into a market where buyer-side contractual norms have already been set by earlier movers and where the chargeback patterns have already established the baseline.
Common obstacles
Three obstacles consistently slow these implementations beyond the nominal timeline.
The first is the form-provider dependency. Lead operators who built their funnel on hosted form providers – JotForm, Formstack, Typeform, Unbounce, the various proprietary builders – are dependent on the provider’s roadmap for additional signal capture. Some providers will ship the necessary capture by mid-2026; others will not. Operators in the latter category face a more substantial migration than operators with internal form infrastructure, and the migration itself can take 90-180 days for funnels with multiple form variants and integrations.
The second is the labeling problem. The classification engine needs labeled training data – submissions known to be agent-mediated versus human-authored – to tune thresholds and to evaluate accuracy. This data is not readily available from third-party sources and must be assembled through a combination of explicit-disclosure capture (forms that ask whether an agent is filling on the user’s behalf), known-agent-population studies, and adversarial-injection testing. Building the labeled dataset takes longer than the engineering work and is the bottleneck that determines classification accuracy.
The third is the buyer education and renegotiation cycle. Lead buyers – particularly mid-sized lenders, insurance carriers, and OEMs – operate on quarterly contracting cycles and rarely accept mid-cycle contractual modifications. Operators who introduce the agent-classification renegotiation in the wrong part of the cycle face a six-to-nine-month wait for the next contracting window. The operators who time the conversation correctly compress the cycle to two to three months.
What the contracting language looks like
A working draft of the contractual language for agent-mediated submissions, developed across multiple operator-buyer conversations in early 2026, addresses the following points:
- Definition: An agent-mediated submission is one classified by the operator as having been completed by an automated browser agent (Comet, Atlas, or analogous) acting under a user mandate, with the classification supported by captured user-agent, TLS, and behavioral signals.
- Acceptance: The buyer accepts agent-mediated submissions as billable provided the operator’s classification logic has been disclosed and reviewed, and provided the submission also satisfies all other billable-lead criteria (consent, vertical fit, contact validity).
- Evidence: The operator preserves the captured signals for a defined retention period (typically the duration of the chargeback window plus a reasonable audit margin) and makes them available to the buyer on request for chargeback dispute resolution.
- Chargeback: The buyer’s chargeback rights for agent-mediated submissions are equivalent to those for human-authored submissions, except that the buyer agrees not to chargeback solely on the basis of agent classification.
- Audit: The buyer has the right to audit the operator’s classification logic on a quarterly basis, with reasonable notice and confidentiality protections.
This is a starting framework, not a complete contract. The specifics will vary by vertical and by buyer. The operators who introduce the framework in current contracts establish the definitional baseline; the operators who do not will be working from the baseline that earlier-mover operators have established when they eventually engage.
Future Implications: What Changes Through 2028
The April 2026 HUMAN Security findings are an inflection point, not an endpoint. The trajectory through the next two years is reasonably predictable from the dynamics already visible in the market.
In the next twelve months, the agent-traffic share of total web traffic will continue compounding. The 6,900 percent growth observed by HUMAN since January 2025 reflects the ramp from a near-zero base, and the absolute share of traffic remains modest. By mid-2027, agent traffic will plausibly represent a double-digit percentage of all submissions to public lead forms in major verticals. This is a forecast, not a measurement, and the rate could accelerate or decelerate based on agent-platform adoption curves; the directional point is that the share will be material to operational planning rather than a fringe consideration.
The vendor landscape will reprice during this period. TrustedForm, Jornaya, Anura, and the other lead-validation platforms will each ship agent-detection updates through 2026 and 2027. The first generation of these updates will likely be conservative – flagging high-confidence agent sessions and producing supplementary classification signals on the cert – and will leave room for operator-side classification logic to operate above the vendor layer. The second generation, expected in 2027-2028, will likely include more granular category assignment and may include vendor-attempted user-mandate verification (potentially through partnerships with the agent platforms themselves). Operators who build classification capability now will be able to absorb the vendor updates as additional signals; operators who do not build will find themselves dependent on vendor classification thresholds that may not match their risk tolerance.
The OWASP framework – the 2026 Top 10 for Agentic Applications listing goal hijacking, tool misuse, memory poisoning, and unintended cross-domain actions among systemic risks – will continue to evolve. The current list represents the security community’s best 2026 enumeration of agent risks; subsequent revisions will add categories as new attack patterns emerge. For lead generation operators, the OWASP work matters less for its specific category list and more for what it signals about the maturity of the underlying threat model. The threat model is still being written, in real time, by security researchers working against agent platforms that are themselves still being built. Operators making investment decisions today should plan for the threat model to expand, not contract.
The contractual norms for agent-mediated submissions will be set by the second half of 2026. The operators and buyers who engage the question proactively in Q2 and Q3 will define the baseline language; the operators who delay past Q4 will be working within whatever baseline the earlier movers have established. Once the baseline is set, the cost of renegotiating it climbs significantly – and the operators who set the baseline will have done so in a configuration that favors their own operational capabilities. This is a precedent-setting moment, not just a technical moment.
The longer-term shift, beyond 2028, is more open-ended. If the agent-platform ecosystem develops standardized user-mandate attestation – a signed assertion from the agent platform that a specific session was authorized by a specific verified user – the three-category framework collapses cleanly into a verifiable two-category framework: human (whether direct or attested-mandate agent) versus unverified-automation. If the platforms do not develop attestation, the three-category framework persists indefinitely, and the classification work becomes a permanent operational discipline. The current signals from Anthropic, Perplexity, and OpenAI suggest some movement toward attestation but no concrete standard as of April 2026; operators should plan for both possibilities and avoid betting the implementation on a single attestation outcome.
Key Takeaways
HUMAN Security’s documentation of 6,900 percent growth in agent traffic since January 2025 and of carding-resembling patterns in Perplexity Comet sessions is the operational signal that lead generation fraud detection has crossed into a new regime. The findings translate directly from e-commerce checkout to insurance, mortgage, solar, and auto lead forms.
The binary “human-or-bot” fraud taxonomy that lead validation has used for fifteen years cannot accommodate agent-mediated submissions. A three-category framework – human-authored, agent-authored under human mandate, and unverified automated – is necessary; operationalizing it requires both technical classification work and contractual renegotiation.
Comet and ChatGPT Atlas expose distinct fingerprints (user-agent strings, TLS handshake characteristics, CFNetwork/Darwin signatures for Atlas on macOS) that allow technical classification of agent sessions, but no current platform provides standardized verification of the user-mandate claim that distinguishes legitimate agent activity from no-mandate automation.
Insurance, mortgage, solar, and auto lead operators face different exposure profiles. Insurance has the highest immediate quality-and-chargeback risk; mortgage has the most acute contractual ambiguity; solar faces a velocity-driven detection challenge; auto faces OEM-driven contractual exclusions that will be set during 2026.
Three response postures will underperform: blocking all agent traffic (cedes legitimate volume to competitors), accepting all agent traffic (accumulates chargeback exposure), and waiting for vendor updates (creates a long-term capability gap). Each treats the question as binary when it is multi-axis.
A practitioner framework rests on four principles: capture the agent signal explicitly rather than inferring it, classify and route rather than block, contract the language before volume forces the issue, and invest in detection that survives spoofing. None of these is a single vendor purchase; all require operator-side configuration and integration work.
The implementation timeline for a mid-sized operator is four to six months end-to-end, covering signal capture, classification logic, routing, and buyer contractual renegotiation. Operators starting in Q2 2026 will be in production by Q4. Operators delaying past Q3 will implement into a market where buyer-side norms have already been established.
The two-year trajectory points to a continued compounding of agent traffic share, vendor-side detection updates that operate as supplementary signals rather than replacements for operator classification, OWASP-led evolution of the threat model that will expand rather than contract, and contractual norms that will be set by the second half of 2026 and become expensive to renegotiate thereafter.
For lead operators currently running TrustedForm or Jornaya certs as their primary fraud-evidence layer, the next ninety days are the planning window. The next one hundred and eighty days are the implementation window. The window for setting favorable contractual baselines closes earlier than the implementation window – which means the contractual conversations should start before the technical implementation completes, not after.
Frequently Asked Questions
What did HUMAN Security actually find about agentic browsers?
HUMAN Security’s analysis through April 2026 documented a 6,900 percent increase in agent and agentic-browser request volume across the websites under its bot-management coverage since January 2025, and a 144.7 percent surge in agent traffic to e-commerce sites during the 2025 Black Friday-Cyber Monday window. The findings most often cited in industry press centered on Perplexity Comet, where HUMAN’s analysts observed checkout-page patterns that resembled the early stages of carding – rapid card additions and removals, repeated payment attempts with form-field variation, and fallback to loyalty-point redemption when card transactions failed. HUMAN’s framing was deliberately careful: the patterns “resembled” carding but were not necessarily fraudulent, since many sessions originated from legitimate user mandates instructing the agent to complete a purchase. The structural finding was that the behavioral signature of legitimate agent-mediated checkout is, at the request-pattern level, indistinguishable from card-testing fraud – which creates both detection-tuning problems for e-commerce and analogous problems for any other form-based traffic surface, including lead generation.
How does agentic browser traffic differ from traditional bot traffic?
Traditional bot traffic is produced by scripts, headless browsers, or API clients without an associated human user mandate. The traffic is automated end-to-end: the actor wrote or configured the script, the script executes against the target, and there is no user behind the activity at the moment of execution. Agentic browser traffic is produced by AI agents (Comet, ChatGPT Atlas, and analogous products) that may be operating under instructions from a verified human user. The user typed an instruction in natural language; the agent interpreted the instruction and executed the technical actions necessary to fulfill it, including form-fill submissions on third-party sites. Technically, both traditional bot traffic and agent traffic are software-generated. Practically, the agent traffic carries – at least in legitimate cases – a human consent and intent layer that traditional bot traffic does not. The fraud-detection challenge is that the technical signals are similar enough that distinguishing the two requires either signal-rich behavioral analysis or out-of-band user-mandate attestation, and neither is currently a solved problem for lead generation.
What is the OWASP 2026 Top 10 for Agentic Applications and why does it matter?
The OWASP 2026 Top 10 for Agentic Applications is the security community’s enumeration of the most significant systemic risks in AI-agent-driven systems. The list includes goal hijacking (an attacker manipulating an agent to pursue a different objective than the user intended), tool misuse (an agent invoking tools – APIs, integrations, browsers – in ways that exceed the user’s authorization), memory poisoning (manipulation of the agent’s context or persistent memory to influence future actions), and unintended cross-domain actions (an agent taking actions in one domain based on signals from another domain in ways the user did not authorize). For lead generation, the OWASP framework matters because it describes the threat model that determines what kinds of agent-driven attacks will appear on lead forms. An attacker leveraging goal hijacking against a Comet user could redirect that user’s intended insurance shopping into a fraud workflow on a different domain. Operators who plan only for the existing bot threat model and not for the agent threat model will be defending against the wrong attacks within the next 12 to 18 months.
How do TrustedForm and Jornaya certs handle agent-mediated submissions?
As of April 2026, both TrustedForm (ActiveProspect) and Jornaya (Verisk) capture session evidence that records the events of the form submission, including page URL, time stamps, and session-replay style evidence of user activity. The cert frameworks were designed around human authorship: the captured evidence is intended to demonstrate that a human user was present and gave consent at the moment of submission. Agent-mediated submissions produce certs in the same format but with different underlying evidence – no keystroke events, no mouse movement, programmatic field fill, often a non-human user-agent string. Neither vendor, as of April 2026, ships a standardized “agent-mediated” cert classification. The vendors are likely to ship updates through 2026 and 2027 that include agent-detection signals as supplementary fields on the cert, but operators should not assume the cert alone is sufficient for billable-lead determination in an agent-traffic environment. The cert is necessary; it is no longer sufficient.
What is the “third category” the article proposes between human and bot?
The third category is “agent-authored, human-mandated” submissions: form fills produced by an AI agent acting under instructions from a verified human user whose intent matches the form’s purpose. This category sits between traditional human-authored submissions (where the user directly typed the form data) and traditional bot submissions (where there is no associated human at all). Operationally, distinguishing the three categories requires technical signals that identify the agent layer (user-agent strings, TLS fingerprints, behavioral patterns) and verification signals that establish the user mandate (signed attestations from the agent platform, or out-of-band user verification). The technical classification is achievable today with appropriate signal capture and rule logic. The user-mandate verification is not yet a solved problem at industry scale, which is why the contractual language for category-two submissions is still being negotiated rather than standardized.
How should mortgage lead operators specifically handle this?
Mortgage lead operators face the most acute contractual ambiguity because mortgage buyer contracts typically use the phrase “consumer-initiated” to define billable leads, and the phrase was not drafted with agent-mediated submissions in mind. The recommended near-term steps are: revisit billable-lead definitions in current buyer contracts and identify ambiguity around agent submissions; introduce explicit language defining how agent-mediated submissions are treated, including evidence requirements and chargeback rights; capture and persist the agent-classification signals on each lead record so that disputed submissions can be reconciled with evidence; and route classified-as-agent submissions to the buyer tier whose contractual language explicitly accepts them, holding back submissions where the contractual treatment is ambiguous. Operators who introduce these conversations in Q2 2026 are doing so on their own timing; operators who delay past Q3 will be reacting to chargeback disputes in a position of contractual weakness.
What are the user-agent fingerprints for Comet and ChatGPT Atlas?
Perplexity Comet ships as a Chromium-based browser and produces user-agent strings that follow Chromium conventions but typically include a “Comet” identifier or a Perplexity-attributed string in environments where the agent is the active driver. The TLS fingerprint matches recent Chromium stable. ChatGPT Atlas, OpenAI’s agentic browser launched in late 2025, has been documented in favicon-fetch logs producing user-agent strings that include “ChatGPT Atlas” alongside CFNetwork and Darwin signatures characteristic of macOS-native clients. The CFNetwork/Darwin combination indicates the underlying network stack is macOS-native rather than Chromium-derived, producing a TLS fingerprint distinct from any Chromium-based browser. Both fingerprints are spoofable by sufficiently motivated attackers, which is why detection logic should combine user-agent signals with TLS fingerprinting and behavioral analysis rather than relying on the user-agent string alone. Operators should validate current fingerprints against their own telemetry rather than relying on any single published reference, because the products evolve rapidly.
Why does Anthropic’s enterprise share matter for this analysis?
Anthropic’s 2026 State of AI Agents report cited estimates that Claude accounts for approximately 40 percent of enterprise AI spend versus OpenAI’s 27 percent – figures sourced from third-party enterprise-spending analytics rather than from Anthropic itself. The composition of enterprise AI spend matters for lead generation because it indicates which agent platforms are being deployed at scale in the kinds of organizations that build customer-facing automation. An enterprise environment dominated by Claude-driven agents will produce a different traffic mix on public lead forms than one dominated by OpenAI-driven agents, and the technical fingerprints will differ accordingly. Operators planning detection capability should not bet on a single agent platform dominating; the realistic forecast is a multi-platform environment in which Comet, Atlas, Claude-driven agents (often through enterprise integrations rather than a consumer browser), and various API-mediated workflows all contribute to inbound agent traffic. Detection logic should be platform-agnostic in design, with platform-specific signals as additive inputs rather than as primary classification keys.
What does the 144.7% Black Friday-Cyber Monday surge indicate about 2026 holiday volume?
The 144.7 percent year-over-year increase in agent traffic to e-commerce during the 2025 Black Friday-Cyber Monday window, as documented by HUMAN Security and consistent with bot-management telemetry from other vendors, establishes that agent traffic is concentrating around high-volume commerce events rather than distributing evenly through the year. This pattern has direct implications for lead generation operators in verticals that follow seasonal demand peaks: insurance shopping concentrates in open-enrollment windows, mortgage origination concentrates around rate-cycle inflection points, solar concentrates in spring and summer purchase windows. Operators should plan for agent-traffic share to be materially higher during their vertical’s seasonal peaks than during off-peak periods, and should size their detection-and-classification capability for peak rather than average load. The 2025 BFCM data is the precedent. The 2026 vertical-specific peaks – open enrollment in November-December, mortgage seasonality through summer, solar in Q2-Q3 – will produce analogous concentrations.
How does this relate to the existing 5-15% duplicate rate that lead operators already manage?
The 5-15 percent duplicate rate that lead operators manage today is a separate quality dimension from agent classification, but the two interact in ways that matter for billing accuracy. A duplicate lead is a submission of a record that the operator or buyer has already received within a defined deduplication window; it is rejected from billing under existing contractual frameworks regardless of whether the underlying submission was human or agent. The interaction with agent classification is that agent-mediated submissions may produce different duplicate patterns than human-authored ones – for example, an agent comparison-shopping across multiple insurance carriers on behalf of the same user may produce multiple submissions from the same underlying consumer in a short time window, increasing the apparent duplicate rate. Operators should be prepared to see duplicate-rate signals shift as agent traffic share grows, and should review whether their deduplication windows and matching logic remain appropriate as the underlying traffic mix changes. The directional expectation is that duplicate rates will rise modestly with agent share, not that the existing 5-15 percent baseline will collapse or explode.
What contractual language should operators introduce with buyers?
A working framework for the contractual language covers five elements. First, a definition: agent-mediated submissions are those classified by the operator as having been completed by an automated browser agent acting under a user mandate, supported by captured user-agent, TLS, and behavioral signals. Second, an acceptance clause: the buyer accepts agent-mediated submissions as billable provided classification logic has been disclosed and reviewed and other billable-lead criteria are satisfied. Third, an evidence preservation clause: the operator retains the captured signals for the chargeback window plus a reasonable audit margin and provides them on request. Fourth, a chargeback clause: the buyer’s chargeback rights are equivalent for agent and human submissions, except that the buyer agrees not to chargeback solely on the basis of agent classification. Fifth, an audit clause: the buyer has the right to audit the operator’s classification logic on a quarterly basis with reasonable notice and confidentiality protections. This is a starting framework; specifics vary by vertical and buyer. Operators introducing the framework in current contracts establish the definitional baseline that subsequent operators will work within.
What is the realistic implementation timeline for an operator starting now?
A mid-sized operator running existing TrustedForm or Jornaya integrations should plan four to six months from project start to first agent-classified leads flowing through renegotiated buyer contracts. The breakdown: signal capture (30-60 days for operators with internal form infrastructure, 60-120 days for those dependent on hosted form providers); classification logic (20-40 days for an initial rule-based engine, with ongoing tuning thereafter); routing engine updates (20-40 days for the per-buyer category-mapping configuration); buyer contractual renegotiation (60-120 days for an operator with twenty to fifty buyers, dependent on each buyer’s contracting cycle). The streams partially parallelize: signal capture and classification logic can run in parallel with early-stage buyer conversations, and routing-engine work can begin once classification is producing categorized outputs. The bottleneck is typically the buyer contractual cycle, which is least under the operator’s direct control. Operators starting in Q2 2026 will be in production by Q4. Operators delaying past Q3 will implement into a market where buyer-side norms have already been set by earlier movers – a worse competitive position than the technical timeline alone suggests.
Sources
Tier 1: Primary Vendor and Standards Sources
-
HUMAN Security, “Agentic Commerce Traffic: Black Friday and Cyber Monday,” accessed April 28, 2026 – https://www.humansecurity.com/learn/blog/agentic-commerce-traffic-black-friday-cyber-monday/
-
HUMAN Security, “AI Agents Carding Attack Breakdown” (Perplexity Comet checkout-page patterns), accessed April 28, 2026 – https://www.humansecurity.com/learn/blog/ai-agents-carding-attack-breakdown/
-
OWASP Foundation, “OWASP Top 10 for LLM Applications and Agentic Applications,” 2026 – https://owasp.org/www-project-top-10-for-llm-applications/
-
Anthropic, “Research” (2026 State of AI Agents and related publications), accessed April 28, 2026 – https://www.anthropic.com/research
-
Perplexity, “Comet Browser,” accessed April 28, 2026 – https://www.perplexity.ai/comet
-
OpenAI, “Introducing ChatGPT Atlas,” 2025-2026 – https://openai.com/index/introducing-chatgpt-atlas/
-
Cloudflare, “Cloudflare Radar – AI and Bot Insights,” accessed April 28, 2026 – https://radar.cloudflare.com/
Tier 2: Established Industry Research and Trade Press
-
ActiveProspect, “TrustedForm – Lead Certification Product Page,” accessed April 28, 2026 – https://activeprospect.com/products/trustedform/
-
Verisk, “Jornaya – Lead-Event Recording,” accessed April 28, 2026 – https://www.verisk.com/insurance/products/jornaya/
-
Anura, “Ad and Lead Fraud Detection Platform,” accessed April 28, 2026 – https://www.anura.io/
-
The Verge, OpenAI ChatGPT Atlas launch coverage, late 2025 – https://www.theverge.com/
-
TechCrunch, Perplexity Comet feature coverage, 2025-2026 – https://techcrunch.com/
-
Wired, Agent traffic and security coverage, 2026 – https://www.wired.com/
Tier 3: Industry and Vendor Statements
-
Perplexity, “Introducing Comet,” product announcement, 2025 – https://www.perplexity.ai/
-
OpenAI, “ChatGPT Atlas – Browser Agent Documentation,” 2025-2026 – https://openai.com/
-
Anthropic, “Claude Agents – Capabilities and Safety,” accessed April 28, 2026 – https://www.anthropic.com/
-
ActiveProspect, “Bot Detection and Lead Quality Updates,” 2025-2026 – https://activeprospect.com/
-
Verisk, “Jornaya Detection Capability Updates,” 2025-2026 – https://www.verisk.com/
Tier 4: Supporting Industry Commentary
-
Industry analyst commentary on agent traffic share growth, various trade publications, Q1-Q2 2026.
-
Security researcher coverage of Comet
comet://extensions/exposure, various 2026 publications. -
Lead generation trade press coverage of TrustedForm and Jornaya agent-detection roadmaps, 2026.
-
Insurance, mortgage, solar, and auto industry coverage of agent-mediated lead handling, Q1-Q2 2026.
-
OWASP working-group commentary on the 2026 Top 10 for Agentic Applications, accessed April 28, 2026.
-
Bot-management vendor analyses of holiday 2025 agent traffic patterns, including HUMAN, Cloudflare, and DataDome public reporting.
Closing
The HUMAN Security findings will be remembered, in retrospect, as the moment when lead generation fraud detection encountered a problem its existing taxonomy could not describe. The 6,900 percent growth number is the headline. The operational story is that the agent-traffic curve has crossed from a search-and-discovery phenomenon into a form-fill phenomenon, and that the detection vocabulary built for a binary world cannot accommodate a population that is neither human nor purely automated. The lead operators and buyers who treat April 2026 as a vendor-update wait will spend the next two to three quarters operating on yesterday’s classification framework while competitors build the three-category capability that captures both the legitimate agent population and the no-mandate fraud population. The operators who treat the moment as a contractual and technical reset – capturing the signals explicitly, classifying and routing rather than blocking, contracting the language before chargebacks force the question, and investing in detection that survives spoofing – will run a margin window that closes when the rest of the market catches up. The decision about which group to be in is being made in the next ninety days of planning and the next one hundred and eighty days of build. The window for setting favorable contractual baselines is shorter than the technical implementation window. There is no comfortable third option that splits the difference.
Market data, vendor capabilities, and security findings reflect publicly reported conditions through April 28, 2026. Agent-platform behaviors, fingerprints, and detection capabilities change continuously; verify current behavior through primary sources and operator-side telemetry before relying on any specific signal. This article provides general industry analysis and does not constitute legal, compliance, or security advice. Consult qualified counsel for specific compliance questions related to TCPA, state-level mini-TCPA statutes, and contractual definitions of billable leads in agent-mediated traffic environments.